Speech Recognition with Shallow Neural Network Classification Project
VerifiedAdded on 2022/09/07
|12
|2380
|21
Project
AI Summary
This project report delves into speech recognition using shallow neural network classification. It explores the application of Bayesian regularization algorithms to enhance accuracy and reduce processing time. The methodology involves a shallow neural network with one hidden layer, contrasting with deep neural networks. The study highlights the use of MATLAB for implementation and analysis, including the application of Mel-frequency cepstral coefficients (MFCC) and Hidden Markov Models (HMM) for feature extraction and classification. The report discusses experiments, results, and the architecture of the neural network, including network training summaries, error histograms, ROC plots, and confusion matrices. It also examines the benefits of speech recognition for various applications, such as aiding individuals with disabilities and enhancing security systems. The conclusion emphasizes the advantages of speech recognition technologies, from improving accessibility to saving time and effort in various applications.

Running head: SPEECH RECOGNITION USING SHALLOW NEURAL NETWORK
CLASSIFICATION
Speech Recognition Using Shallow Neural Network Classification
Student’s name
Institution Affiliation(s)
CLASSIFICATION
Speech Recognition Using Shallow Neural Network Classification
Student’s name
Institution Affiliation(s)
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

SPEECH RECOGNITION USING SHALLOW NEURAL NETWORK CLASSIFICATION
Table of Contents
Abstract............................................................................................................................................2
Introduction......................................................................................................................................3
Problem definition...........................................................................................................................3
Methodology....................................................................................................................................3
Experiments and discussion.............................................................................................................4
Bayesian regularization algorithm...................................................................................................5
Matlab..............................................................................................................................................5
Neural network architecture............................................................................................................6
Network training summary..............................................................................................................7
A plot of training state.....................................................................................................................7
Error histogram for test set..............................................................................................................8
Roc plot for test classes...................................................................................................................8
A plot of the confusion matrix.........................................................................................................9
Conclusion.....................................................................................................................................10
References......................................................................................................................................11
1
Table of Contents
Abstract............................................................................................................................................2
Introduction......................................................................................................................................3
Problem definition...........................................................................................................................3
Methodology....................................................................................................................................3
Experiments and discussion.............................................................................................................4
Bayesian regularization algorithm...................................................................................................5
Matlab..............................................................................................................................................5
Neural network architecture............................................................................................................6
Network training summary..............................................................................................................7
A plot of training state.....................................................................................................................7
Error histogram for test set..............................................................................................................8
Roc plot for test classes...................................................................................................................8
A plot of the confusion matrix.........................................................................................................9
Conclusion.....................................................................................................................................10
References......................................................................................................................................11
1

SPEECH RECOGNITION USING SHALLOW NEURAL NETWORK CLASSIFICATION
Abstract
Speech recognition is a technology used by human beings to identify and capture the
voice spoken through the microphone. The words or the voice is then decoded by a speech
recognizer, which in system outputs the recognized words. Speech recognition technology offers
a platform for better recognition of the voice even when there is a lot of noise.
2
Abstract
Speech recognition is a technology used by human beings to identify and capture the
voice spoken through the microphone. The words or the voice is then decoded by a speech
recognizer, which in system outputs the recognized words. Speech recognition technology offers
a platform for better recognition of the voice even when there is a lot of noise.
2
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

SPEECH RECOGNITION USING SHALLOW NEURAL NETWORK CLASSIFICATION
Introduction
This project aims to come up with a system that will have a higher recognition accuracy
and, at the same time, reducing the time taken in the recognition process(Youhao, 2012). The
improved noise-robust features will ensure that there are accuracy and better extraction
capabilities. Once this project is complete, it can be used to perform a variety of technical
services that may include the use of voice for security purposes, in dialing applications, and even
in application control systems (Arora & Singh, 2012). For disabled people, speech recognition
applications can help them in enhancing their communication capabilities. It will also help
people with spinal cord injuries to access private areas with the use of a voice recognition
program (Gevaert, Tsenov, & Mladenov, 2010). The program should be in a position to interpret
voice command with the use of computer-based systems.
Problem definition
Speech recognition aids persons who are disabled. Speech recognition has also been
applied to enhancing security. Even though the project may be expensive, it will provide the
necessary assistance to many people and at the same time enhancing security. The program will
be in a position to offer different kinds of speech recognition, including isolation speech,
connected speech, and spontaneous speech.
Methodology
A shallow neural network methodology will be used to classify the data to be used as
input in speech recognition. Shallow neural networks are network architectures that have only
one hidden layer as opposed to a deep neural network that contains several hidden strata (Wang,
Jiang, & Xie, 2017). The use of Bayesian regularization algorithms improves the level of
accuracy in speech recognition because it operates on a logarithmic scale. The Bayesian
3
Introduction
This project aims to come up with a system that will have a higher recognition accuracy
and, at the same time, reducing the time taken in the recognition process(Youhao, 2012). The
improved noise-robust features will ensure that there are accuracy and better extraction
capabilities. Once this project is complete, it can be used to perform a variety of technical
services that may include the use of voice for security purposes, in dialing applications, and even
in application control systems (Arora & Singh, 2012). For disabled people, speech recognition
applications can help them in enhancing their communication capabilities. It will also help
people with spinal cord injuries to access private areas with the use of a voice recognition
program (Gevaert, Tsenov, & Mladenov, 2010). The program should be in a position to interpret
voice command with the use of computer-based systems.
Problem definition
Speech recognition aids persons who are disabled. Speech recognition has also been
applied to enhancing security. Even though the project may be expensive, it will provide the
necessary assistance to many people and at the same time enhancing security. The program will
be in a position to offer different kinds of speech recognition, including isolation speech,
connected speech, and spontaneous speech.
Methodology
A shallow neural network methodology will be used to classify the data to be used as
input in speech recognition. Shallow neural networks are network architectures that have only
one hidden layer as opposed to a deep neural network that contains several hidden strata (Wang,
Jiang, & Xie, 2017). The use of Bayesian regularization algorithms improves the level of
accuracy in speech recognition because it operates on a logarithmic scale. The Bayesian
3
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

SPEECH RECOGNITION USING SHALLOW NEURAL NETWORK CLASSIFICATION
regularization algorithm features can also be used to extract and find the meaning in the
algorithm that makes it the most preferred system to be used in the application or the project. Its
performance in different environments proves to be useful as it provides the highest level of
accuracy that makes it the best system to use, taking into consideration the gender, the
background, and style used in speaking (Keshet, 2018). The combination of neural network
architecture and Bayesian regularization algorithms produces the best results due to the
combination of both architectures. The combination works better in a noisy environment as it
provides a high level of accuracy.
Experiments and discussion
The system will ensure that the Hidden Markov Model (HMM) based system will meet
the needs of the program (Quinn, Vidaurre, & Becker, 2018). With the use of decision logic,
pattern training, feature extraction, and preprocessing will enhance the implementation of the
system. The organization has provided the necessary mechanism to ensure that the training of the
proposed method works effectively. Once the speech recognition has been identified, different
testing environments will be created to test its authenticity. The organization expects the use of
HMM (Bertrand, Tam, & Fablet, 2013) to create a good speech recognition program, which will
ensure that there is the provision of different architectural data that will increase accuracy,
especially in the noisy environment, due to the coordination of the HMM and Mel-frequency
cepstral coefficients (MFCC) (Eskidere & Gürhanlı, 2015).
For the process to be successful, the following process and items have to be provided.
The first one is the audio output, the analog to the digital platform, the acoustic model, the
language to be used, the speech engine, and finally, the display. The voice input includes the
microphone audio and the pc sound, which helps in producing the received digital audio. It will
4
regularization algorithm features can also be used to extract and find the meaning in the
algorithm that makes it the most preferred system to be used in the application or the project. Its
performance in different environments proves to be useful as it provides the highest level of
accuracy that makes it the best system to use, taking into consideration the gender, the
background, and style used in speaking (Keshet, 2018). The combination of neural network
architecture and Bayesian regularization algorithms produces the best results due to the
combination of both architectures. The combination works better in a noisy environment as it
provides a high level of accuracy.
Experiments and discussion
The system will ensure that the Hidden Markov Model (HMM) based system will meet
the needs of the program (Quinn, Vidaurre, & Becker, 2018). With the use of decision logic,
pattern training, feature extraction, and preprocessing will enhance the implementation of the
system. The organization has provided the necessary mechanism to ensure that the training of the
proposed method works effectively. Once the speech recognition has been identified, different
testing environments will be created to test its authenticity. The organization expects the use of
HMM (Bertrand, Tam, & Fablet, 2013) to create a good speech recognition program, which will
ensure that there is the provision of different architectural data that will increase accuracy,
especially in the noisy environment, due to the coordination of the HMM and Mel-frequency
cepstral coefficients (MFCC) (Eskidere & Gürhanlı, 2015).
For the process to be successful, the following process and items have to be provided.
The first one is the audio output, the analog to the digital platform, the acoustic model, the
language to be used, the speech engine, and finally, the display. The voice input includes the
microphone audio and the pc sound, which helps in producing the received digital audio. It will
4

SPEECH RECOGNITION USING SHALLOW NEURAL NETWORK CLASSIFICATION
be the responsibility of the organization to provide the necessary items and infrastructure, which
will support in setting out the system for testing the program (Dede & Sazli, 2010).
Bayesian regularization algorithm
Bayesian regularization algorithm transforms non-linear regression into an ordered
statistical problem. The algorithm is advantageous at its designs and is more robust and does not
require any validation processes (Sariev & Germano, 2020). The algorithm is specifically useful
in implementing speech recognition since it provides optimization for network architecture.
People with medical disabilities like muscular dystrophy and strain injuries usually have some
challenges when typing (Burden & Winkler, 2018). With technology, the telephony system can
enhance the use of spoken commands instead of using the buttons to execute a command. The
use of Bayesian regularization algorithms and MFCC can increase the voice command
recognition system to reduce the amount of data and the computation time taken (Koolagudi,
Rastogi, & Rao, 2012). The use of Euclidean distance can be utilized as a similarity criterion to
increase the accuracy of the algorithms that can help to reduce the error in the speech recognition
platform for more than 15%. This is because it enhances a zero error in the command system;
this is because the MFCC has superior performance, especially in adverse conditions (Burden &
Winkler, 2018). It is also easy to conduct computation and perceptional considerations during the
process.
Matlab
The use of MFCC for the extraction of the algorithms with the help of the Gaussian
Mixture Model (GMM) and the HMM may be expensive but provides the best results. This is
because they provide improved accuracy (Dede & Sazli, 2010). With the help of the MATLAB
7.9 software, the accuracy of the system is better with the use of the preprocessing system. In the
5
be the responsibility of the organization to provide the necessary items and infrastructure, which
will support in setting out the system for testing the program (Dede & Sazli, 2010).
Bayesian regularization algorithm
Bayesian regularization algorithm transforms non-linear regression into an ordered
statistical problem. The algorithm is advantageous at its designs and is more robust and does not
require any validation processes (Sariev & Germano, 2020). The algorithm is specifically useful
in implementing speech recognition since it provides optimization for network architecture.
People with medical disabilities like muscular dystrophy and strain injuries usually have some
challenges when typing (Burden & Winkler, 2018). With technology, the telephony system can
enhance the use of spoken commands instead of using the buttons to execute a command. The
use of Bayesian regularization algorithms and MFCC can increase the voice command
recognition system to reduce the amount of data and the computation time taken (Koolagudi,
Rastogi, & Rao, 2012). The use of Euclidean distance can be utilized as a similarity criterion to
increase the accuracy of the algorithms that can help to reduce the error in the speech recognition
platform for more than 15%. This is because it enhances a zero error in the command system;
this is because the MFCC has superior performance, especially in adverse conditions (Burden &
Winkler, 2018). It is also easy to conduct computation and perceptional considerations during the
process.
Matlab
The use of MFCC for the extraction of the algorithms with the help of the Gaussian
Mixture Model (GMM) and the HMM may be expensive but provides the best results. This is
because they provide improved accuracy (Dede & Sazli, 2010). With the help of the MATLAB
7.9 software, the accuracy of the system is better with the use of the preprocessing system. In the
5
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

SPEECH RECOGNITION USING SHALLOW NEURAL NETWORK CLASSIFICATION
testing process, the use of MFCC and HMM provides an accuracy of 90% higher than the use of
LPC and DTW, which provides an accuracy of 86%. With the cost involved more so the same,
the use of the first testing system proved to be better in enhancing the speech recognition system.
The combination also helps to provide a solution to various challenges in the society.
The speech interface can help the physically challenged people to have better use of
computers and other house appliances. For security purposes, the physically challenged people
can use it to ensure that they are in a position to secure their properties. With this, the cost-
benefit analysis can guide in the adoption of the best plan to have the best and modern speech
recognition application. This application can be used for commercial activities.
Neural network architecture
Neural network architecture is the organization of neurons into stratums and the
connection design between the learning methods, the activation functions, and the layers. For
speech recognition, the network architecture determines how the inputs are transformed into
outputs (Gevaert et al., 2010).
6
testing process, the use of MFCC and HMM provides an accuracy of 90% higher than the use of
LPC and DTW, which provides an accuracy of 86%. With the cost involved more so the same,
the use of the first testing system proved to be better in enhancing the speech recognition system.
The combination also helps to provide a solution to various challenges in the society.
The speech interface can help the physically challenged people to have better use of
computers and other house appliances. For security purposes, the physically challenged people
can use it to ensure that they are in a position to secure their properties. With this, the cost-
benefit analysis can guide in the adoption of the best plan to have the best and modern speech
recognition application. This application can be used for commercial activities.
Neural network architecture
Neural network architecture is the organization of neurons into stratums and the
connection design between the learning methods, the activation functions, and the layers. For
speech recognition, the network architecture determines how the inputs are transformed into
outputs (Gevaert et al., 2010).
6
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
SPEECH RECOGNITION USING SHALLOW NEURAL NETWORK CLASSIFICATION
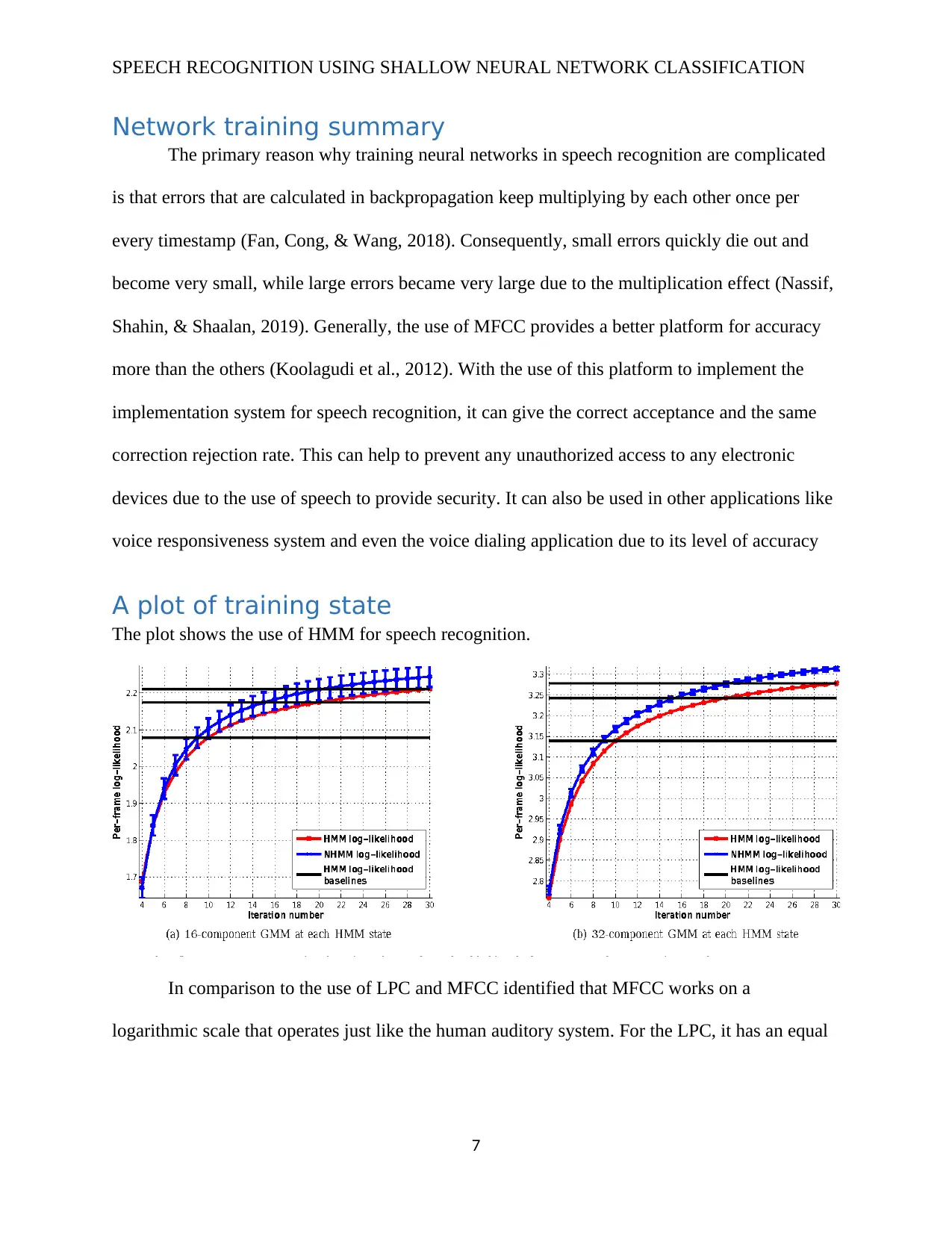
Network training summary
The primary reason why training neural networks in speech recognition are complicated
is that errors that are calculated in backpropagation keep multiplying by each other once per
every timestamp (Fan, Cong, & Wang, 2018). Consequently, small errors quickly die out and
become very small, while large errors became very large due to the multiplication effect (Nassif,
Shahin, & Shaalan, 2019). Generally, the use of MFCC provides a better platform for accuracy
more than the others (Koolagudi et al., 2012). With the use of this platform to implement the
implementation system for speech recognition, it can give the correct acceptance and the same
correction rejection rate. This can help to prevent any unauthorized access to any electronic
devices due to the use of speech to provide security. It can also be used in other applications like
voice responsiveness system and even the voice dialing application due to its level of accuracy
A plot of training state
The plot shows the use of HMM for speech recognition.
In comparison to the use of LPC and MFCC identified that MFCC works on a
logarithmic scale that operates just like the human auditory system. For the LPC, it has an equal
7
Network training summary
The primary reason why training neural networks in speech recognition are complicated
is that errors that are calculated in backpropagation keep multiplying by each other once per
every timestamp (Fan, Cong, & Wang, 2018). Consequently, small errors quickly die out and
become very small, while large errors became very large due to the multiplication effect (Nassif,
Shahin, & Shaalan, 2019). Generally, the use of MFCC provides a better platform for accuracy
more than the others (Koolagudi et al., 2012). With the use of this platform to implement the
implementation system for speech recognition, it can give the correct acceptance and the same
correction rejection rate. This can help to prevent any unauthorized access to any electronic
devices due to the use of speech to provide security. It can also be used in other applications like
voice responsiveness system and even the voice dialing application due to its level of accuracy
A plot of training state
The plot shows the use of HMM for speech recognition.
In comparison to the use of LPC and MFCC identified that MFCC works on a
logarithmic scale that operates just like the human auditory system. For the LPC, it has an equal
7
SPEECH RECOGNITION USING SHALLOW NEURAL NETWORK CLASSIFICATION
resolution on top of the frequency system; this makes MFCC have a better recognition rate than
the rest (Patel et al., 2018).
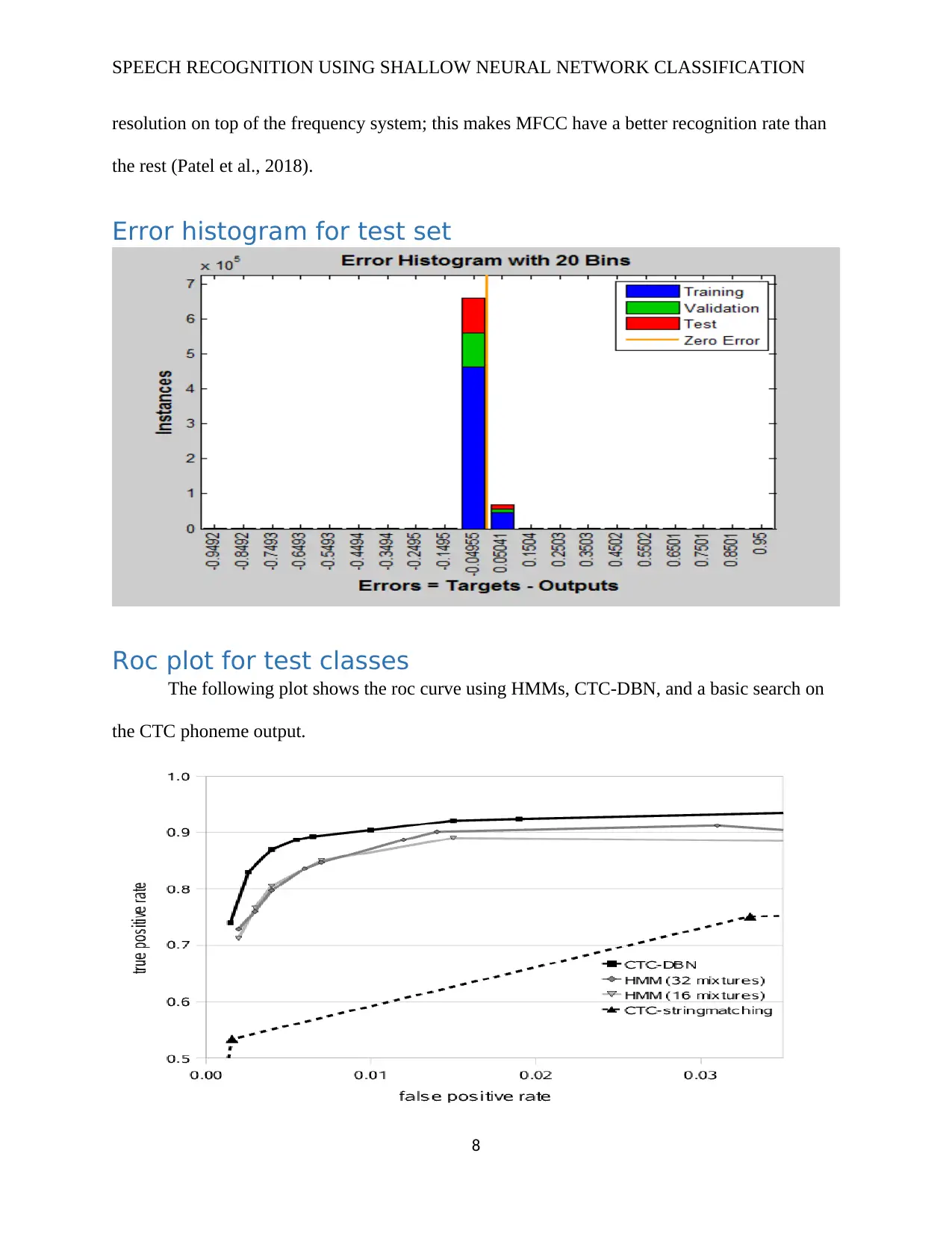
Error histogram for test set
Roc plot for test classes
The following plot shows the roc curve using HMMs, CTC-DBN, and a basic search on
the CTC phoneme output.
8
resolution on top of the frequency system; this makes MFCC have a better recognition rate than
the rest (Patel et al., 2018).
Error histogram for test set
Roc plot for test classes
The following plot shows the roc curve using HMMs, CTC-DBN, and a basic search on
the CTC phoneme output.
8
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

SPEECH RECOGNITION USING SHALLOW NEURAL NETWORK CLASSIFICATION
A plot of the confusion matrix
The computational efficiency and perceptional consideration of the two systems can offer
the best platform for improving the speech recognition system with minimum mistakes, thus
enhancing clarity. The speech recognition accuracy depends on the training time; the increase in
the training time signals a corresponding increase in its accuracy. Below is an example of a
speech recognition confusion matrix with no noise.
Conclusion
Speech recognition can be very advantageous. From benefitting the disabled to saving
one from cramped fingers and hands to saving time, such methods recognized an individual’s
voice. For instance, what is being dictated into the user’s microphone will display as a word-
processed document.
9
A plot of the confusion matrix
The computational efficiency and perceptional consideration of the two systems can offer
the best platform for improving the speech recognition system with minimum mistakes, thus
enhancing clarity. The speech recognition accuracy depends on the training time; the increase in
the training time signals a corresponding increase in its accuracy. Below is an example of a
speech recognition confusion matrix with no noise.
Conclusion
Speech recognition can be very advantageous. From benefitting the disabled to saving
one from cramped fingers and hands to saving time, such methods recognized an individual’s
voice. For instance, what is being dictated into the user’s microphone will display as a word-
processed document.
9
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

SPEECH RECOGNITION USING SHALLOW NEURAL NETWORK CLASSIFICATION
References
Arora, S., & Singh, R. (2012). Automatic Speech Recognition: A Review. International Journal
of Computer Applications, 60, 34–44. Available from:
https://doi.org/10.5120/9722-4190
Bertrand, S., Tam, J., & Fablet, R. (2013). Hidden Markov Models: The Best Models for Forager
Movements? PLOS ONE, 8(8), e71246. Available from:
https://doi.org/10.1371/journal.pone.0071246
Burden, F., & Winkler, D. (2018). Bayesian regularization of neural networks. Methods in
Molecular Biology (Clifton, N.J.), 458, 25–44. Available from:
https://doi.org/10.1007/978-1-60327-101-1_3
Dede, G., & Sazli, M. (2010). Speech recognition with artificial neural networks. Digital Signal
Processing, 20, 763–768. Available from:
https://doi.org/10.1016/j.dsp.2009.10.004
Eskidere, Ö., & Gürhanlı, A. (2015). Voice Disorder Classification Based on Multitaper Mel
Frequency Cepstral Coefficients Features [Research Article]. Available from:
https://doi.org/10.1155/2015/956249
Fan, F., Cong, W., & Wang, G. (2018). Generalized backpropagation algorithm for training
second-order neural networks. International Journal for Numerical Methods in Biomedical
Engineering, 34(5), e2956. Available from:
https://doi.org/10.1002/cnm.2956
Gevaert, W., Tsenov, G., & Mladenov, V. (2010). Neural networks used for speech recognition.
Journal of Automatic Control, 20. Available from:
https://doi.org/10.2298/JAC1001001G
Keshet, J. (2018). Automatic speech recognition: A primer for speech-language pathology
researchers. International Journal of Speech-Language Pathology, 20(6), 599–609. Available
from:
https://doi.org/10.1080/17549507.2018.1510033
Koolagudi, S. G., Rastogi, D., & Rao, K. S. (2012). Identification of Language using Mel-
Frequency Cepstral Coefficients (MFCC). Procedia Engineering, 38, 3391–3398. Available
from:
https://doi.org/10.1016/j.proeng.2012.06.392
Nassif, A. B., Shahin, I., & Shaalan, K. (2019). Speech Recognition Using Deep Neural
Networks: A Systematic Review. IEEE Access, 7, 19143–19165. Available from:
https://doi.org/10.1109/ACCESS.2019.2896880
Patel, H., Thakkar, A., Pandya, M., & Makwana, K. (2018). Neural network with deep learning
architectures. Journal of Information and Optimization Sciences, 39(1), 31–38. Available from:
https://doi.org/10.1080/02522667.2017.1372908
10
References
Arora, S., & Singh, R. (2012). Automatic Speech Recognition: A Review. International Journal
of Computer Applications, 60, 34–44. Available from:
https://doi.org/10.5120/9722-4190
Bertrand, S., Tam, J., & Fablet, R. (2013). Hidden Markov Models: The Best Models for Forager
Movements? PLOS ONE, 8(8), e71246. Available from:
https://doi.org/10.1371/journal.pone.0071246
Burden, F., & Winkler, D. (2018). Bayesian regularization of neural networks. Methods in
Molecular Biology (Clifton, N.J.), 458, 25–44. Available from:
https://doi.org/10.1007/978-1-60327-101-1_3
Dede, G., & Sazli, M. (2010). Speech recognition with artificial neural networks. Digital Signal
Processing, 20, 763–768. Available from:
https://doi.org/10.1016/j.dsp.2009.10.004
Eskidere, Ö., & Gürhanlı, A. (2015). Voice Disorder Classification Based on Multitaper Mel
Frequency Cepstral Coefficients Features [Research Article]. Available from:
https://doi.org/10.1155/2015/956249
Fan, F., Cong, W., & Wang, G. (2018). Generalized backpropagation algorithm for training
second-order neural networks. International Journal for Numerical Methods in Biomedical
Engineering, 34(5), e2956. Available from:
https://doi.org/10.1002/cnm.2956
Gevaert, W., Tsenov, G., & Mladenov, V. (2010). Neural networks used for speech recognition.
Journal of Automatic Control, 20. Available from:
https://doi.org/10.2298/JAC1001001G
Keshet, J. (2018). Automatic speech recognition: A primer for speech-language pathology
researchers. International Journal of Speech-Language Pathology, 20(6), 599–609. Available
from:
https://doi.org/10.1080/17549507.2018.1510033
Koolagudi, S. G., Rastogi, D., & Rao, K. S. (2012). Identification of Language using Mel-
Frequency Cepstral Coefficients (MFCC). Procedia Engineering, 38, 3391–3398. Available
from:
https://doi.org/10.1016/j.proeng.2012.06.392
Nassif, A. B., Shahin, I., & Shaalan, K. (2019). Speech Recognition Using Deep Neural
Networks: A Systematic Review. IEEE Access, 7, 19143–19165. Available from:
https://doi.org/10.1109/ACCESS.2019.2896880
Patel, H., Thakkar, A., Pandya, M., & Makwana, K. (2018). Neural network with deep learning
architectures. Journal of Information and Optimization Sciences, 39(1), 31–38. Available from:
https://doi.org/10.1080/02522667.2017.1372908
10

SPEECH RECOGNITION USING SHALLOW NEURAL NETWORK CLASSIFICATION
Quinn, A., Vidaurre, D., & Becker, R. (2018). Task-Evoked Dynamic Network Analysis
Through Hidden Markov Modeling. Frontiers in Neuroscience, 12. Available from:
https://doi.org/10.3389/fnins.2018.00603
Sariev, E., & Germano, G. (2020). Bayesian regularized artificial neural networks for the
estimation of the probability of default. Quantitative Finance, 20(2), 311–328. Available from:
https://doi.org/10.1080/14697688.2019.1633014
Wang, L., Jiang, F., & Xie, Y. (2017). A shallow convolutional neural network for blind image
sharpness assessment. PLOS ONE, 12(5), e0176632. Available from:
https://doi.org/10.1371/journal.pone.0176632
Youhao, Y. (2012). Research on Speech Recognition Technology and Its Application. 2012
International Conference on Computer Science and Electronics Engineering, 1, 306–309.
Available from:
https://doi.org/10.1109/ICCSEE.2012.359
11
Quinn, A., Vidaurre, D., & Becker, R. (2018). Task-Evoked Dynamic Network Analysis
Through Hidden Markov Modeling. Frontiers in Neuroscience, 12. Available from:
https://doi.org/10.3389/fnins.2018.00603
Sariev, E., & Germano, G. (2020). Bayesian regularized artificial neural networks for the
estimation of the probability of default. Quantitative Finance, 20(2), 311–328. Available from:
https://doi.org/10.1080/14697688.2019.1633014
Wang, L., Jiang, F., & Xie, Y. (2017). A shallow convolutional neural network for blind image
sharpness assessment. PLOS ONE, 12(5), e0176632. Available from:
https://doi.org/10.1371/journal.pone.0176632
Youhao, Y. (2012). Research on Speech Recognition Technology and Its Application. 2012
International Conference on Computer Science and Electronics Engineering, 1, 306–309.
Available from:
https://doi.org/10.1109/ICCSEE.2012.359
11
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 12
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.