Data Analysis Project: Analyzing Sports Skills with Regression Models
VerifiedAdded on 2022/08/23
|25
|2639
|19
Project
AI Summary
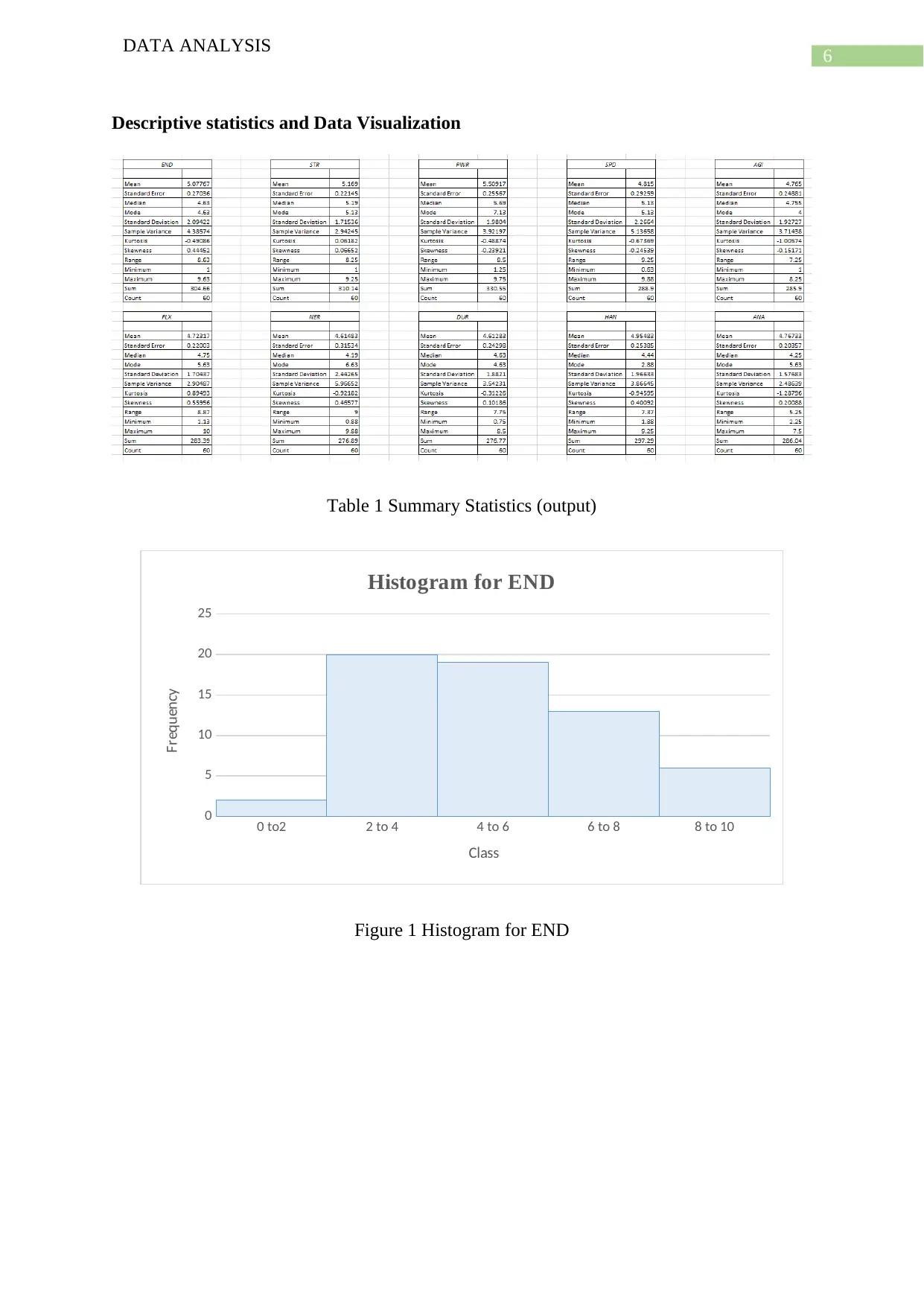
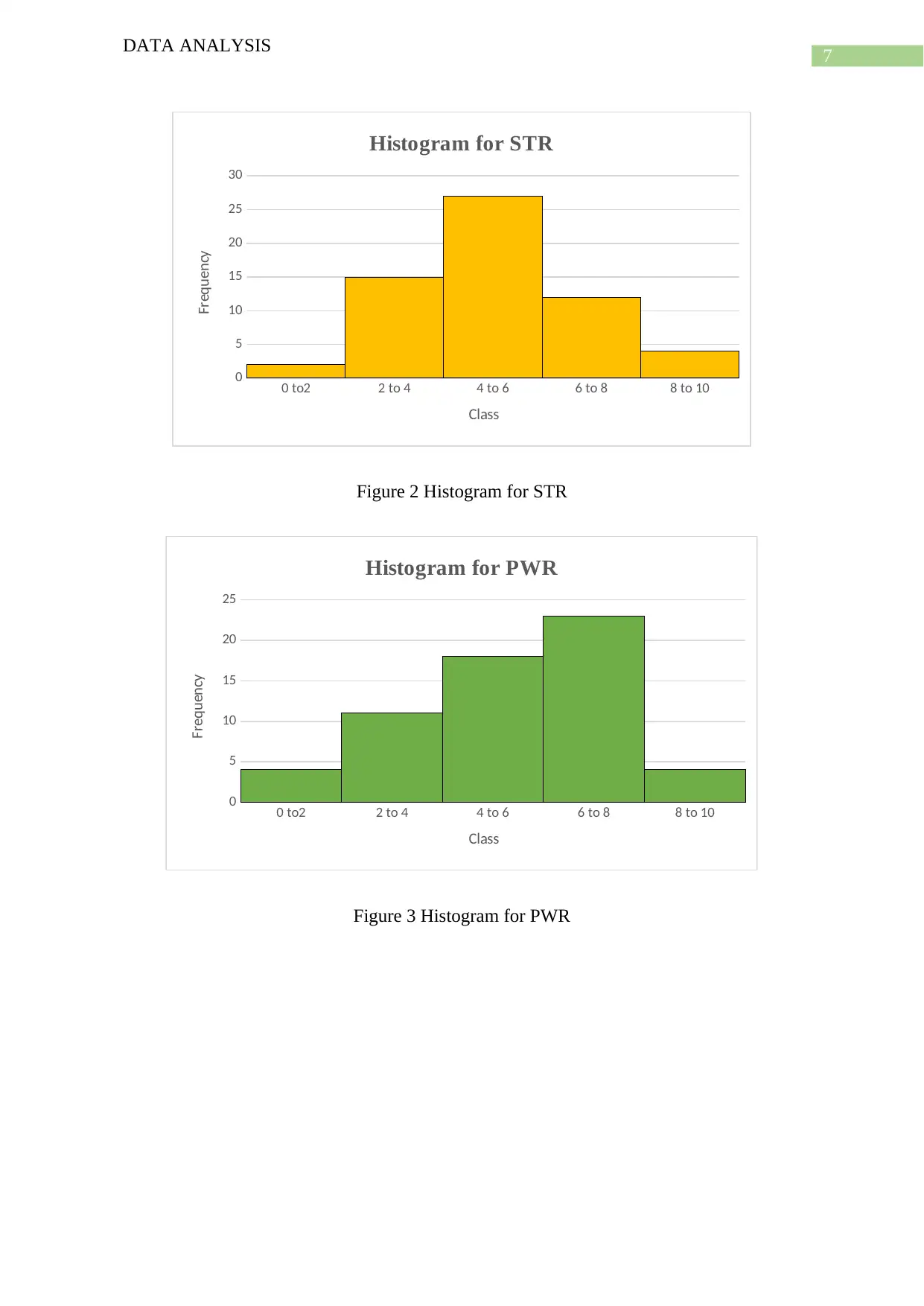
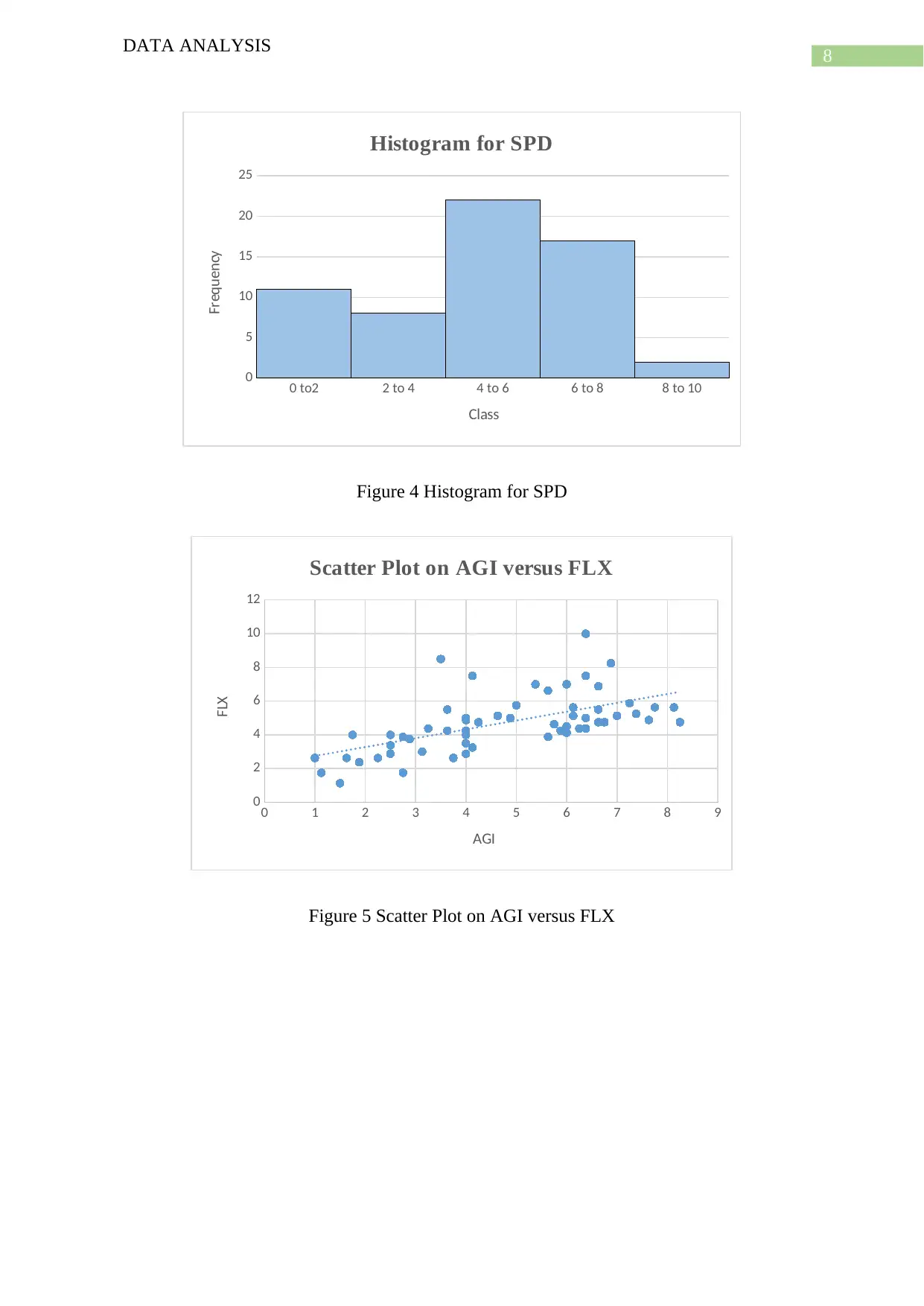
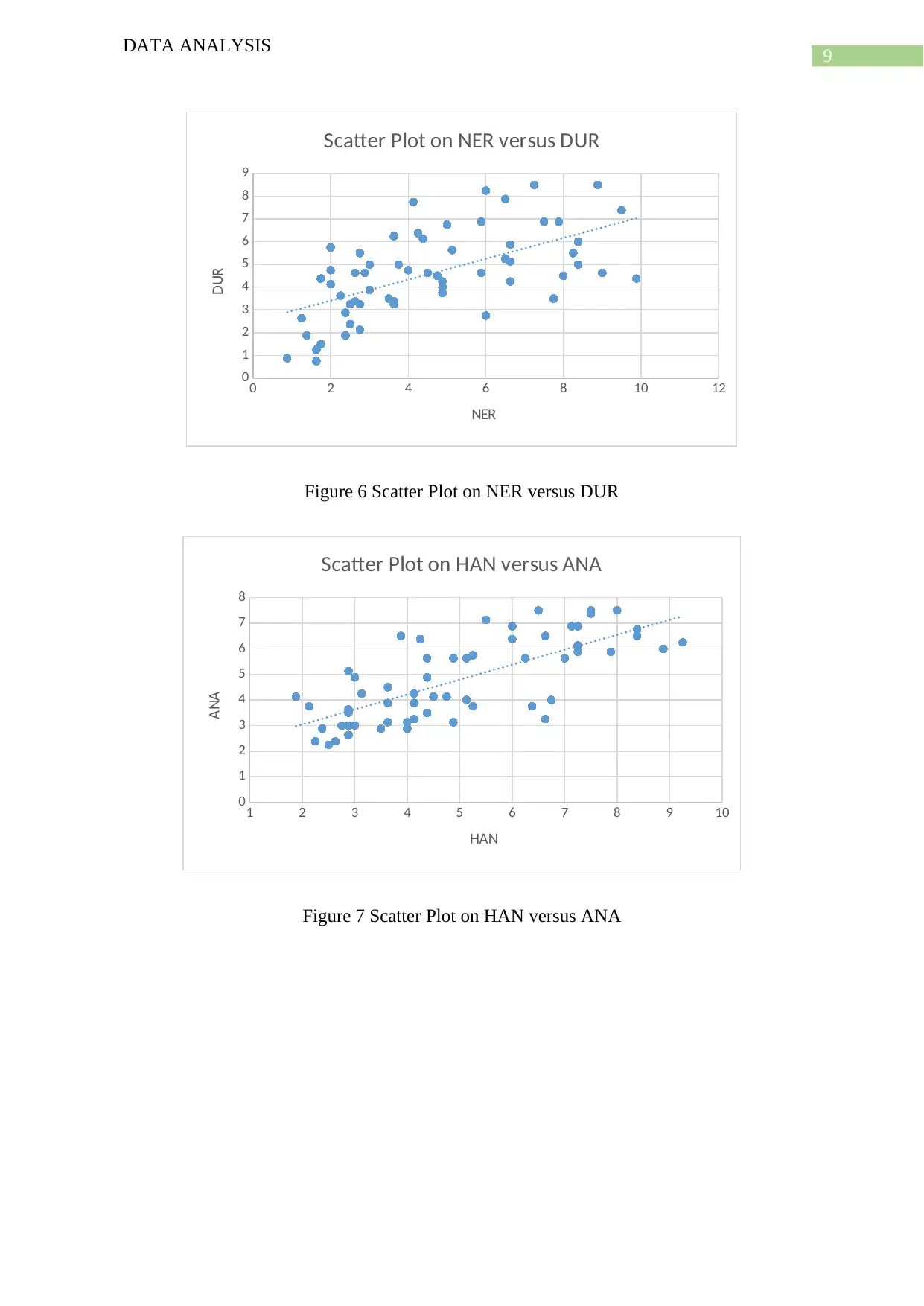
This data analysis project examines sports-specific skills, analyzing a dataset of 60 sports with 12 variables. The project conducts summary statistics, scatter plots, box plots, histograms, and regression analysis to explore relationships between variables. It emphasizes data cleaning to ensure data integrity. The study includes descriptive statistics, data visualization, and multiple regression analysis to identify significant relationships between variables. The analysis involves identifying skewness, outliers, and correlations. The project uses regression models to analyze the impact of different sports skills. The findings include positive and negative skewness and relationships between variables, supported by citations to relevant literature. The project concludes with a summary of the findings and suggestions for future research.







1 out of 25
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.