STA 250 SPSS Assignment: Statistical Analysis and Interpretation
VerifiedAdded on 2021/04/17
|12
|1701
|457
Homework Assignment
AI Summary
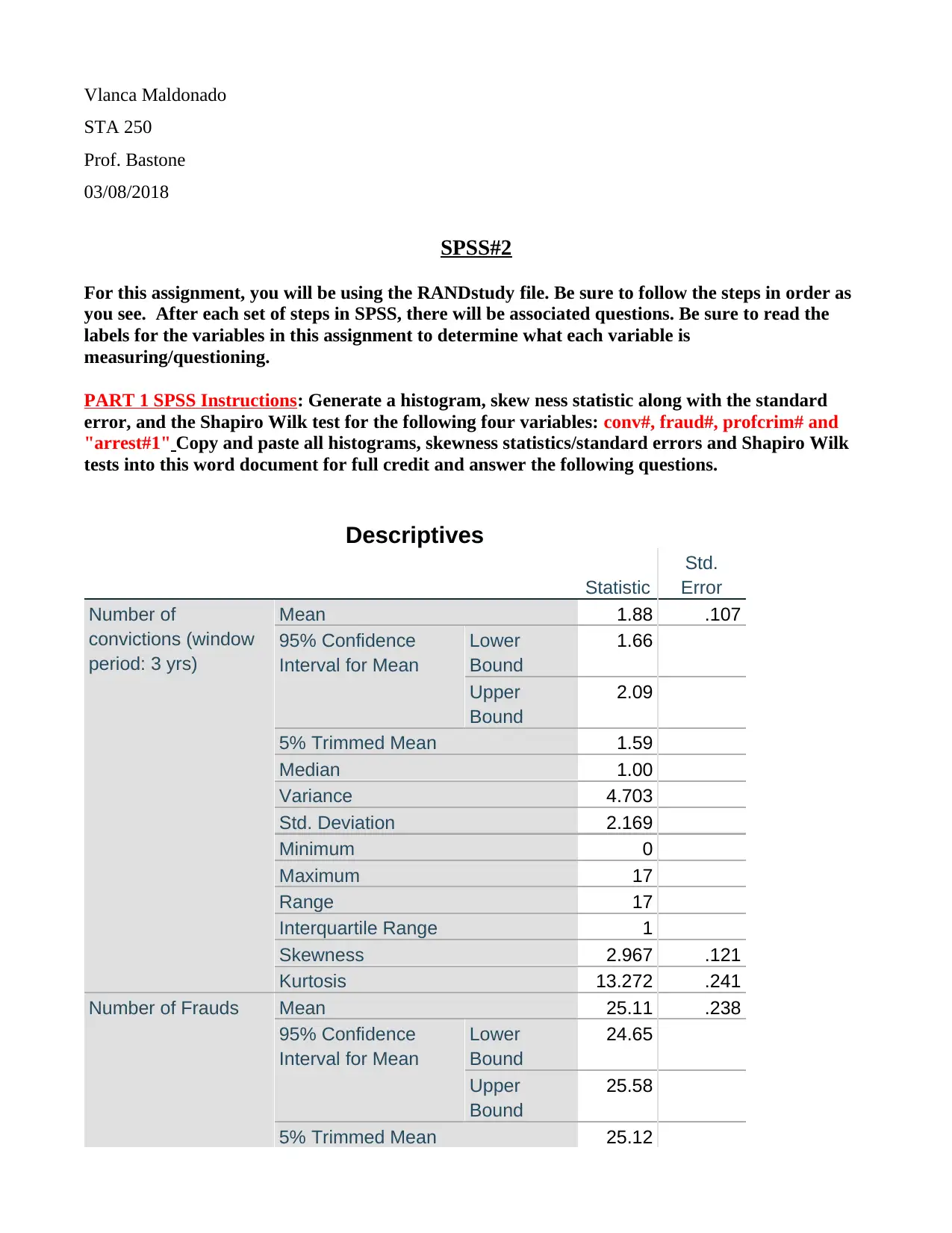
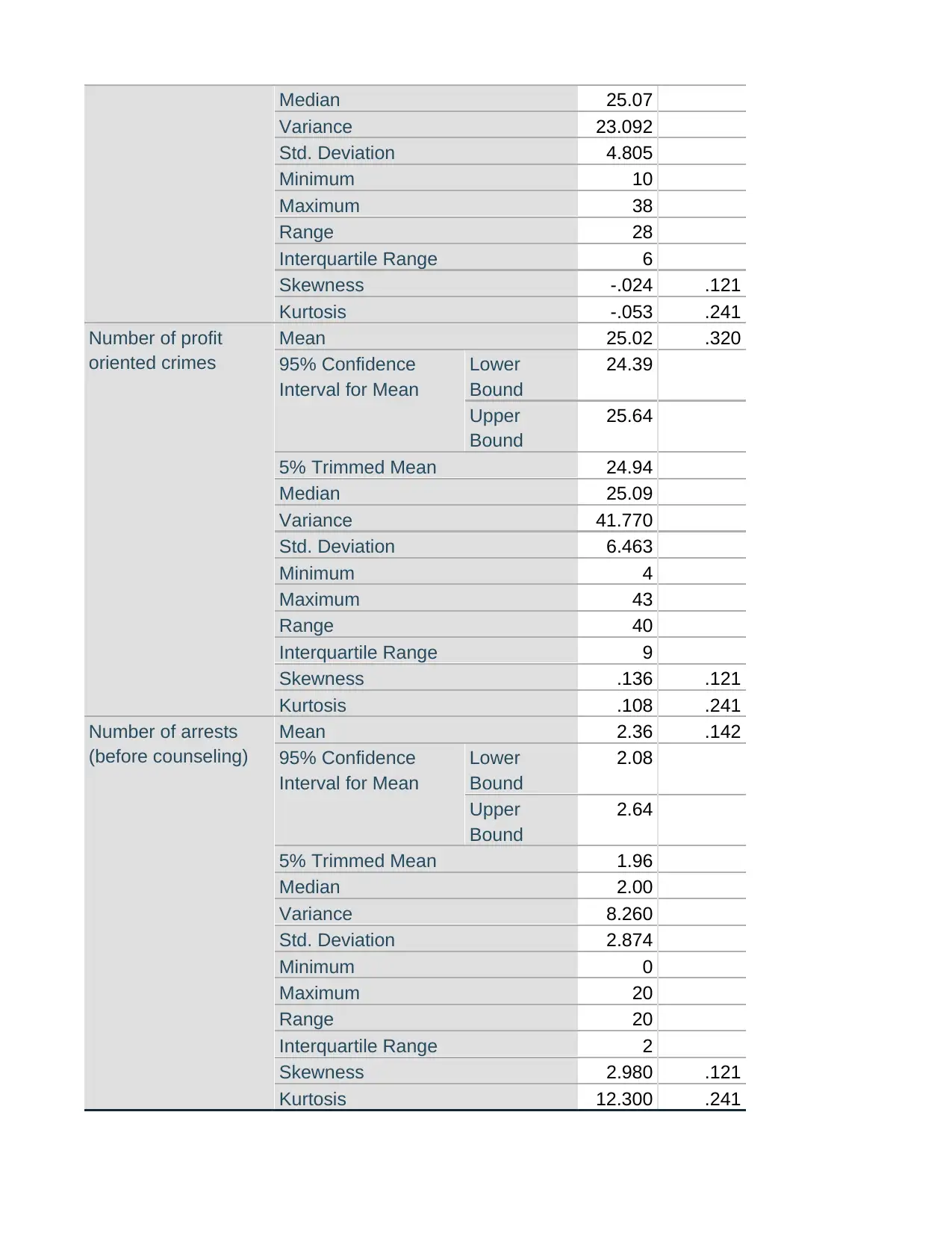
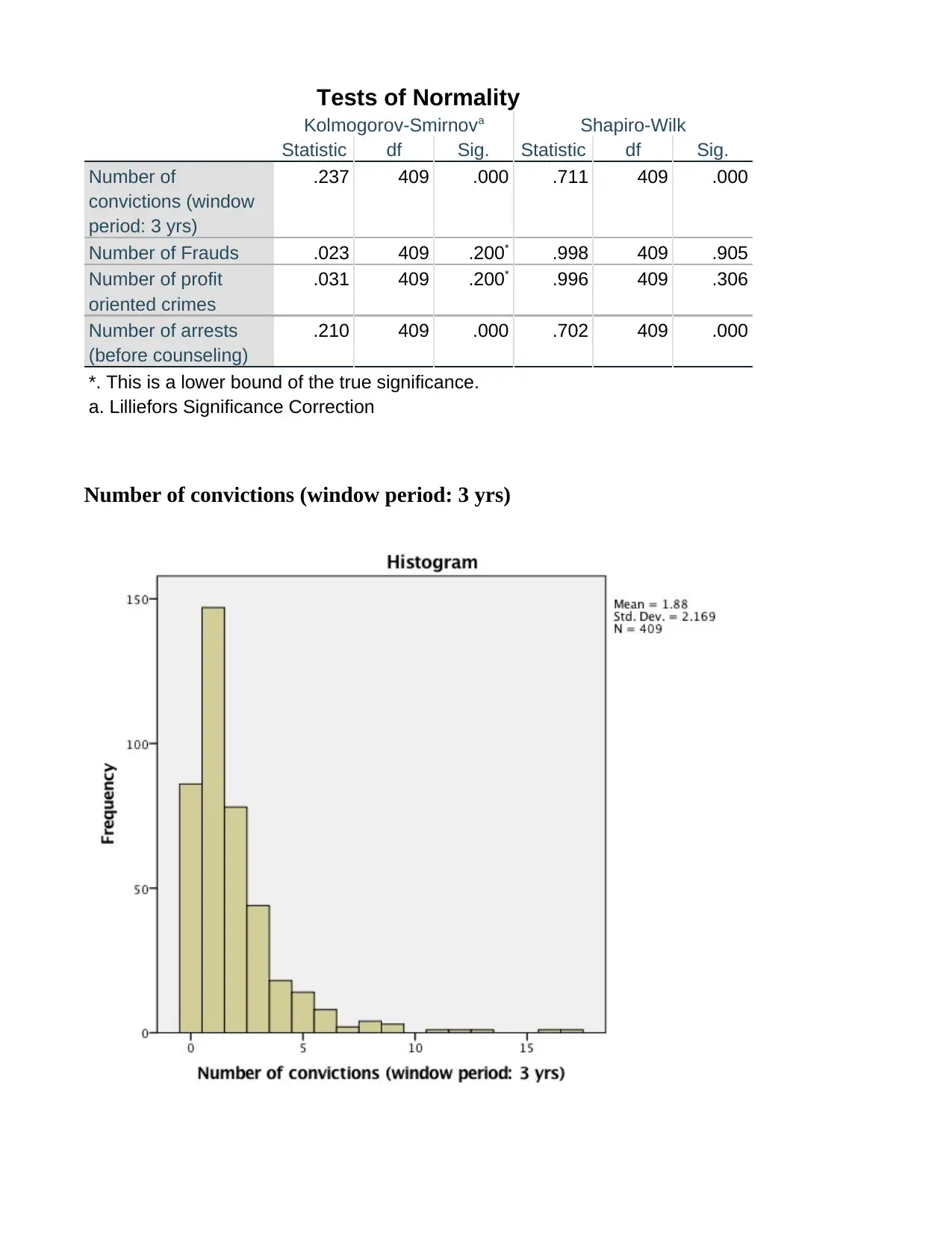
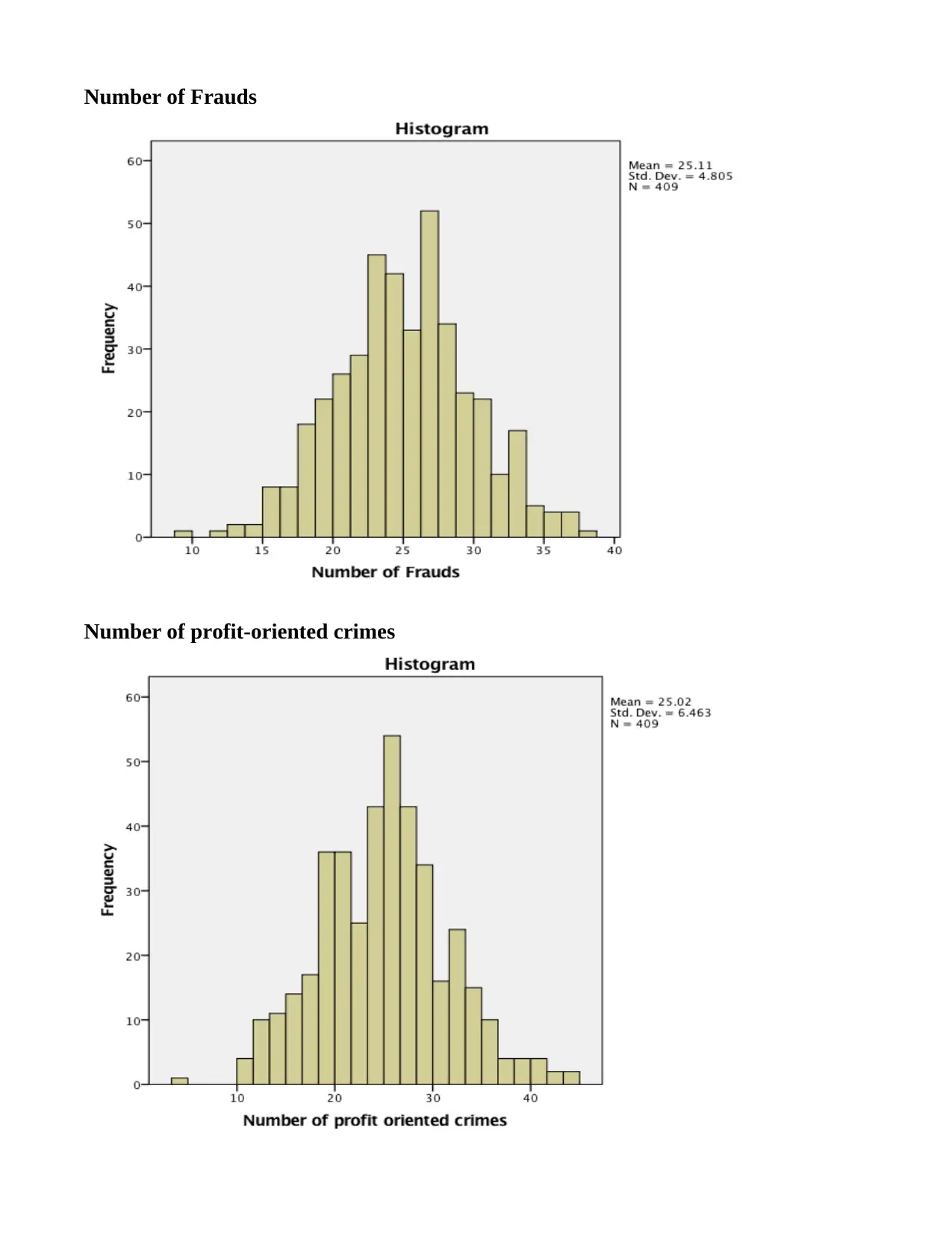
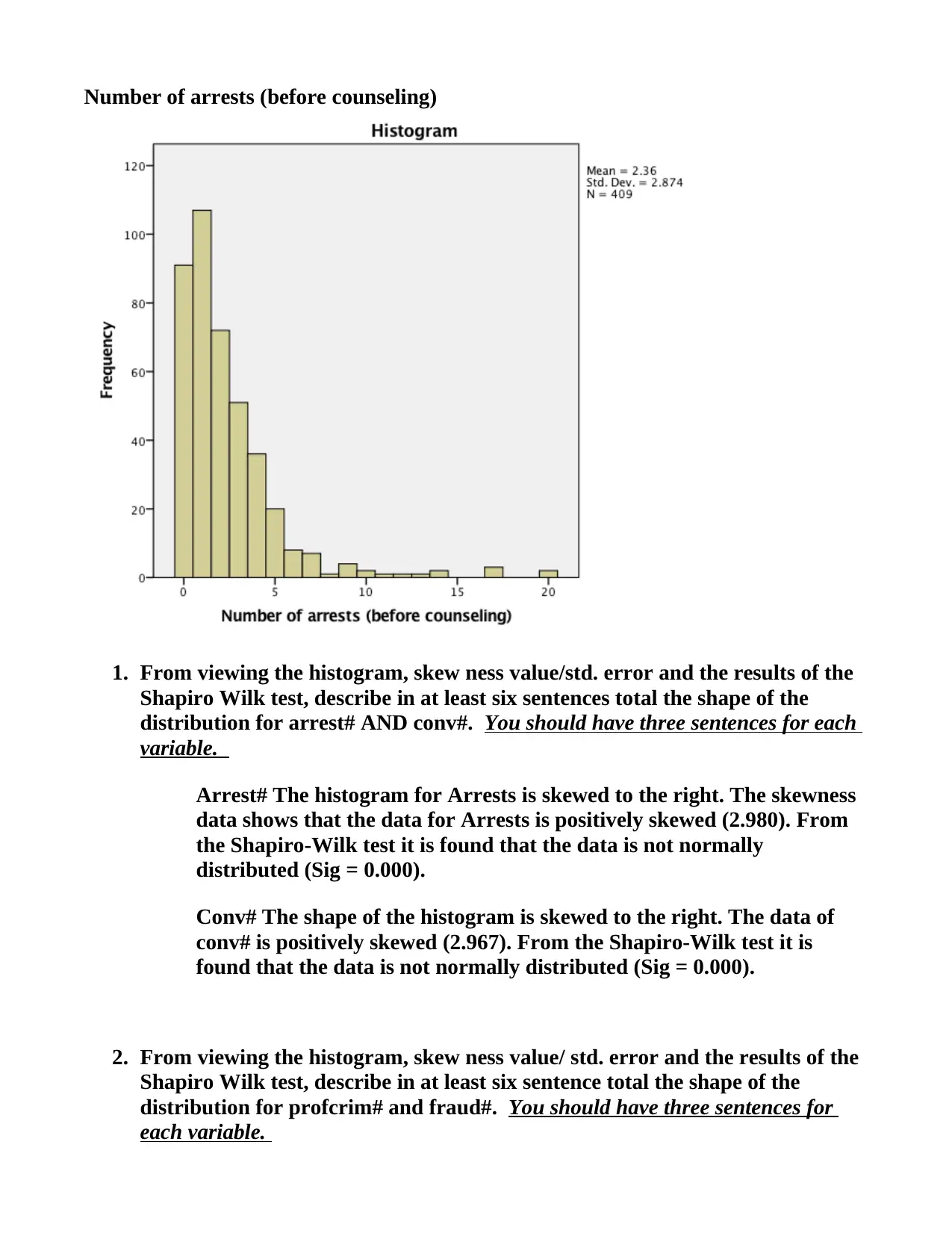
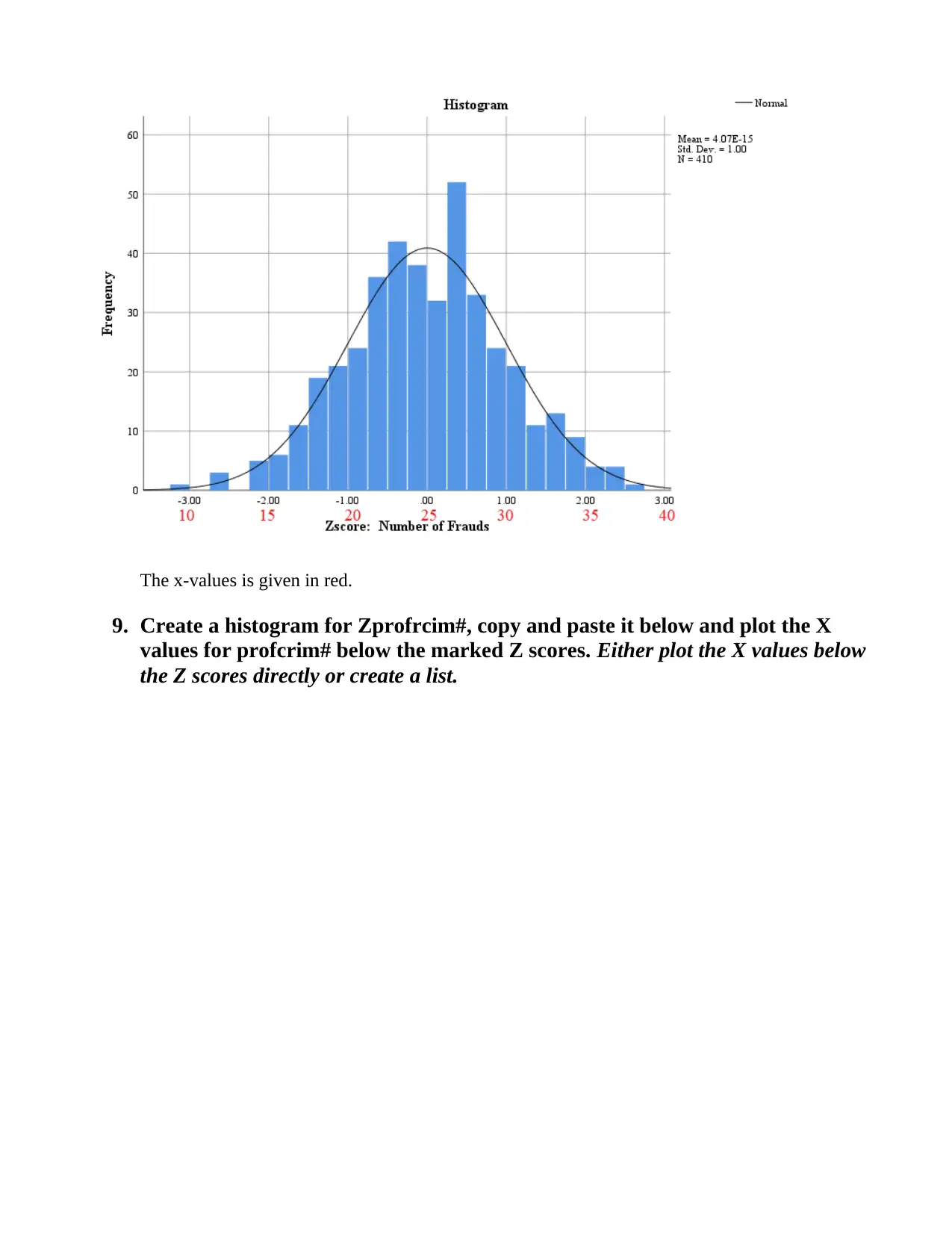
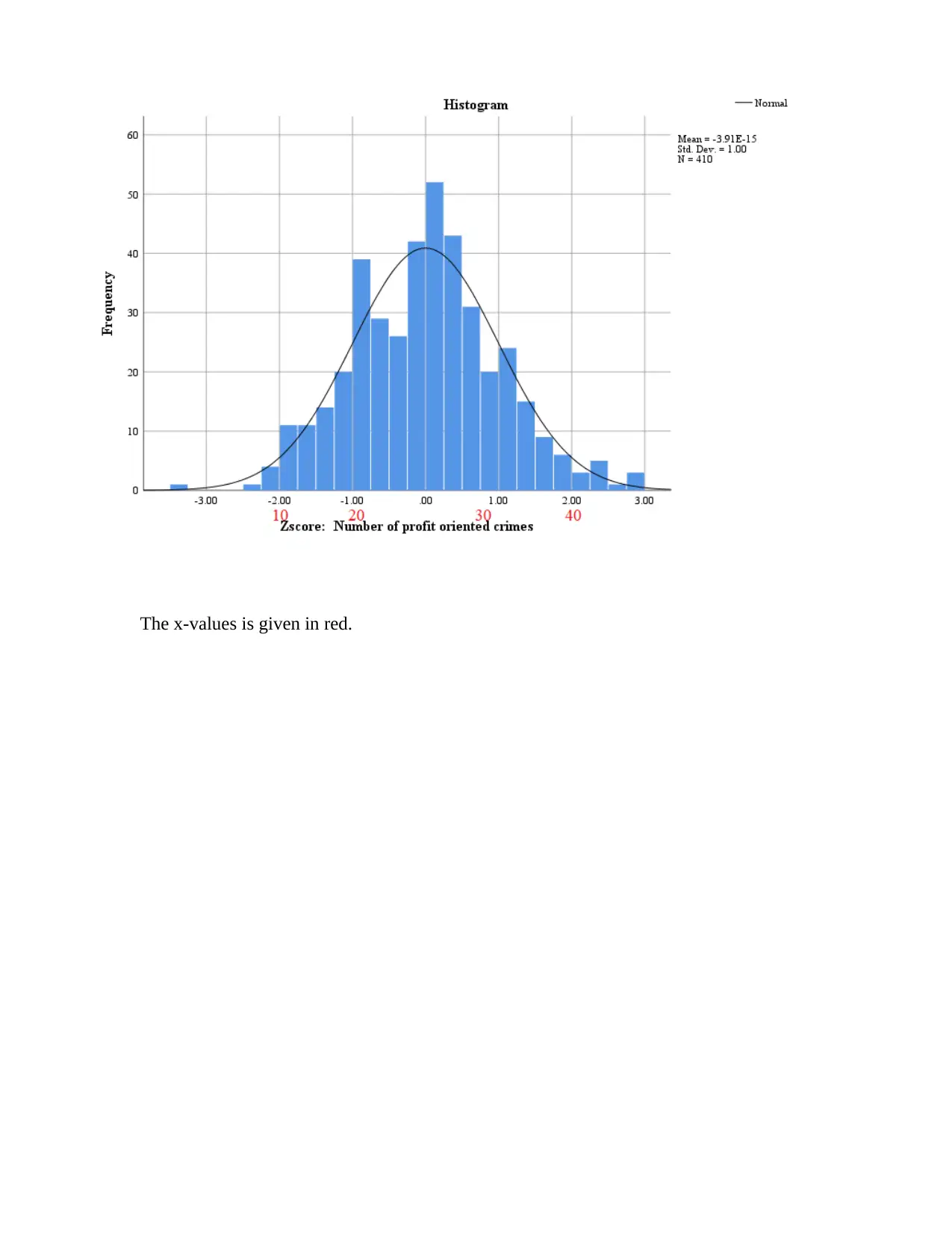
This SPSS assignment, completed by Vlanca Maldonado for STA 250, Prof. Bastone, covers various statistical concepts using the RANDstudy and Drug Court Data files. The assignment begins with generating histograms, calculating skewness, and performing the Shapiro-Wilk test for variables such as convictions, fraud, profit-oriented crimes, and arrests. Students are required to describe the shape of distributions, identify variables suitable for Z-score creation, and determine the location of specific X values within the Z distribution. Part 2 involves creating Z-scores, generating descriptive statistics for both X and Z-score variables, and interpreting the differences between them. Histograms are created for Zfraud# and Zprofcrim#, and X values are plotted in relation to the Z-scores. The assignment concludes with a cross-tabulation analysis using the Drug Court Data file, exploring the relationship between gang membership and gender, including calculations of percentages and probabilities to determine if gender influences gang membership.





1 out of 12
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.