STA101 Statistics for Business: Assignment on Data Analysis, 2017
VerifiedAdded on 2020/03/16
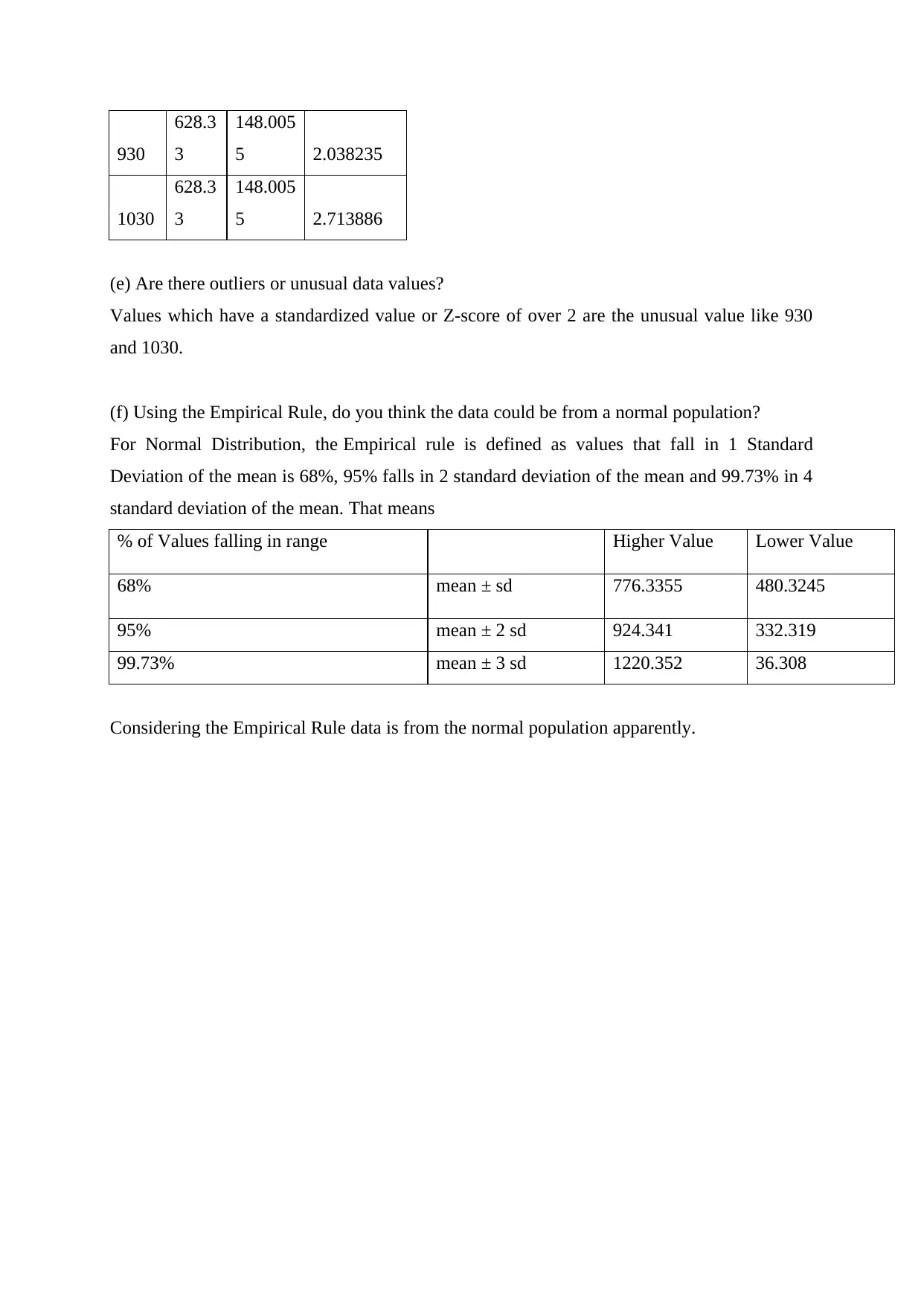
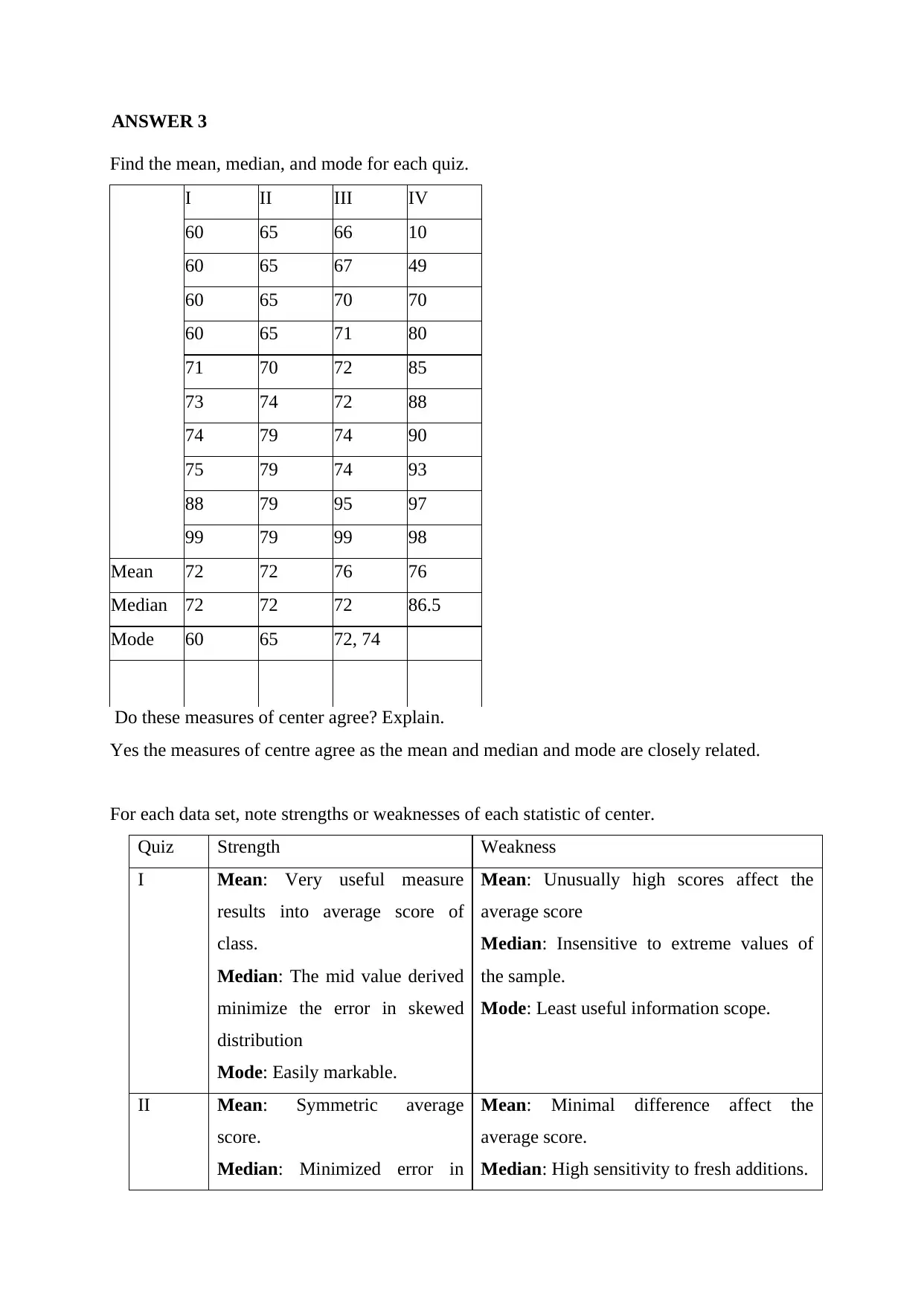
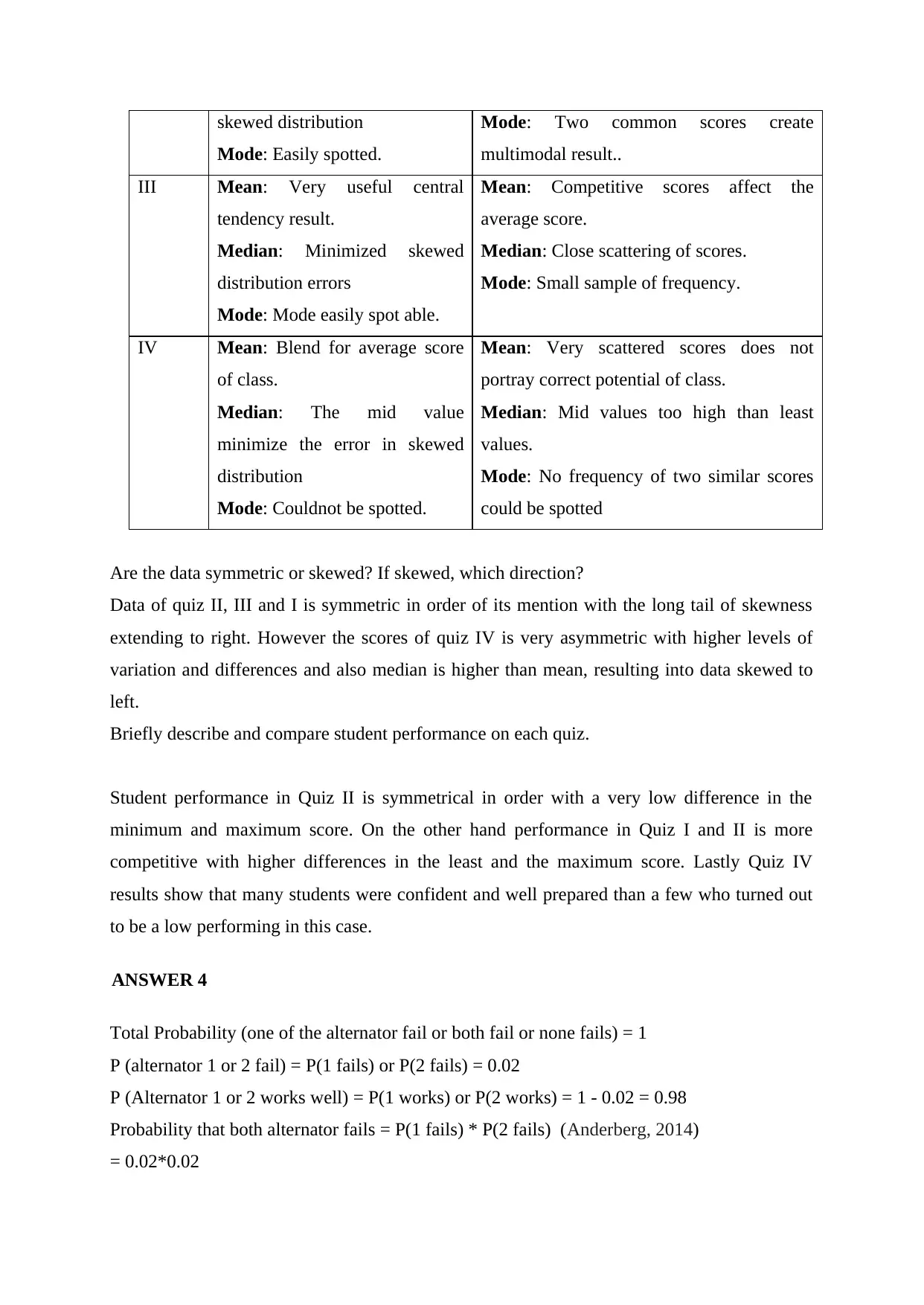
|15
|2206
|36
Homework Assignment
AI Summary
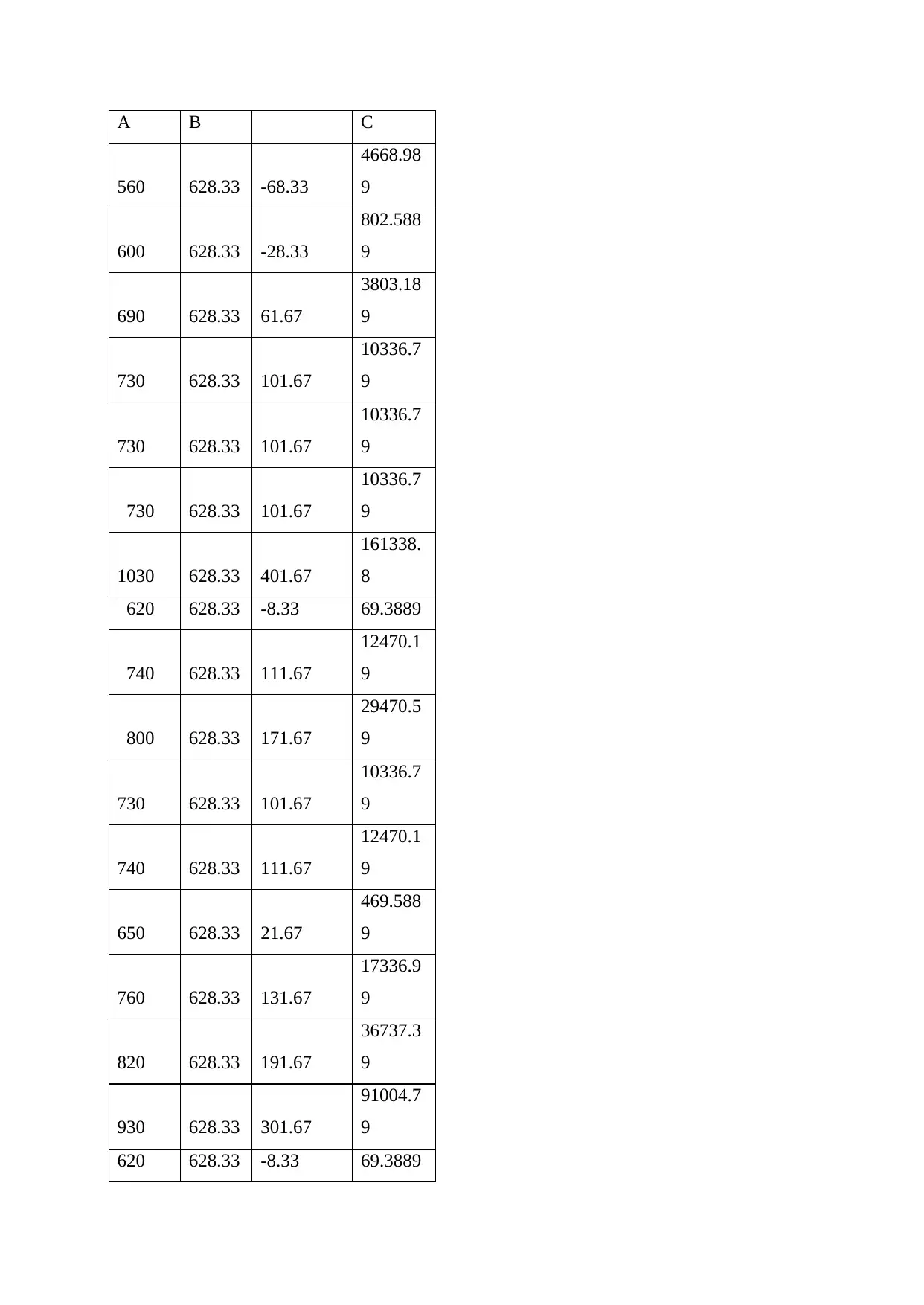
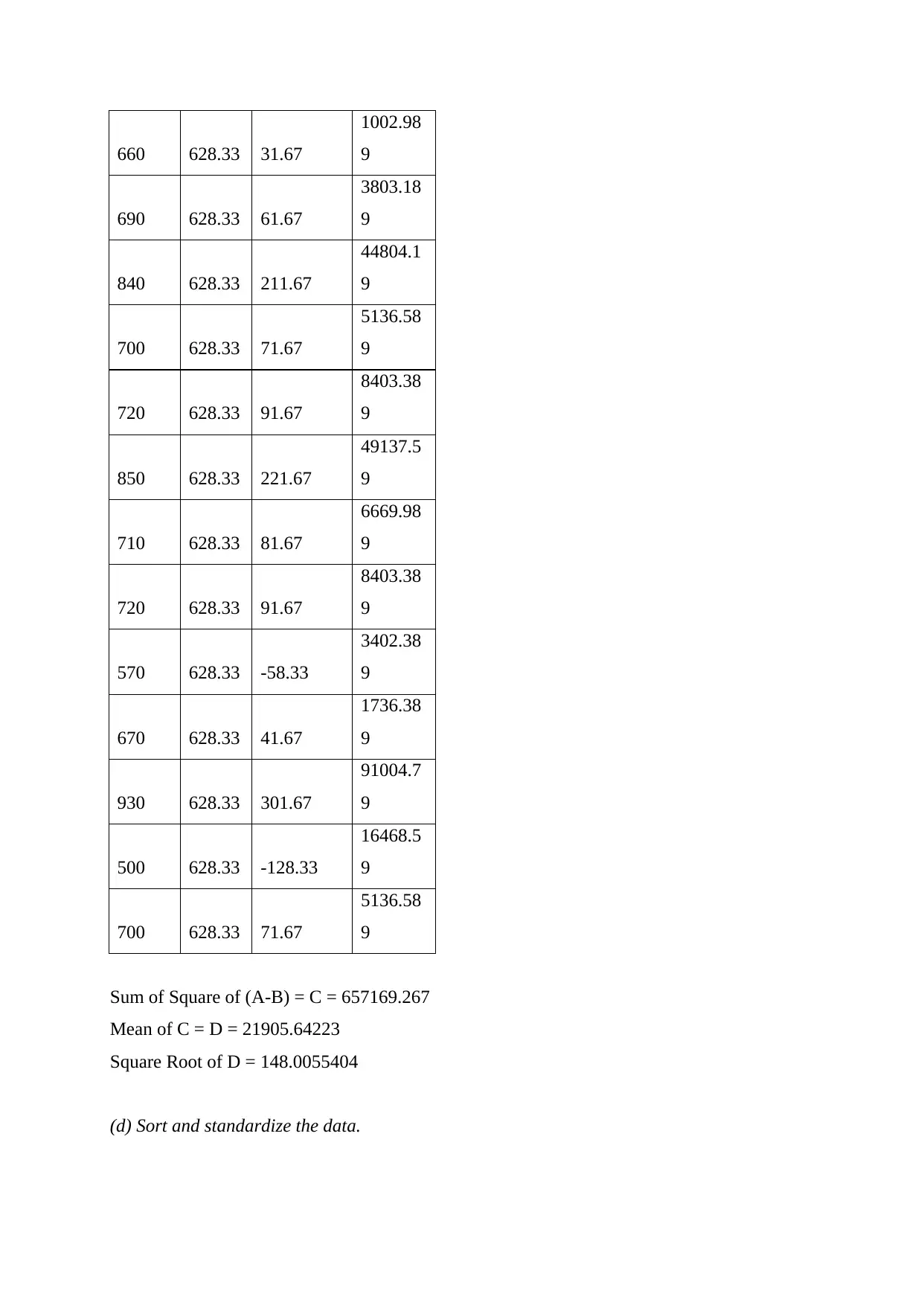
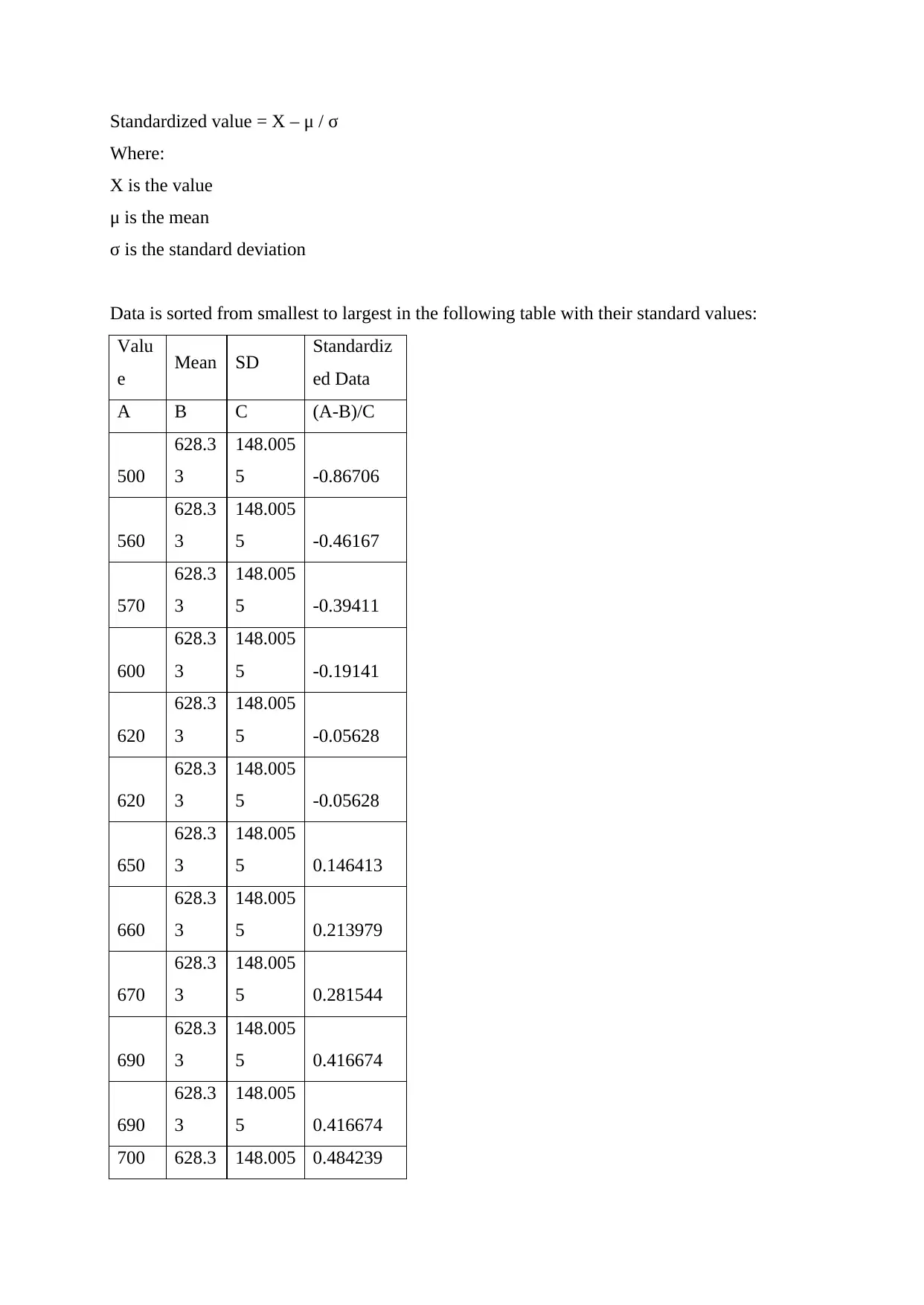
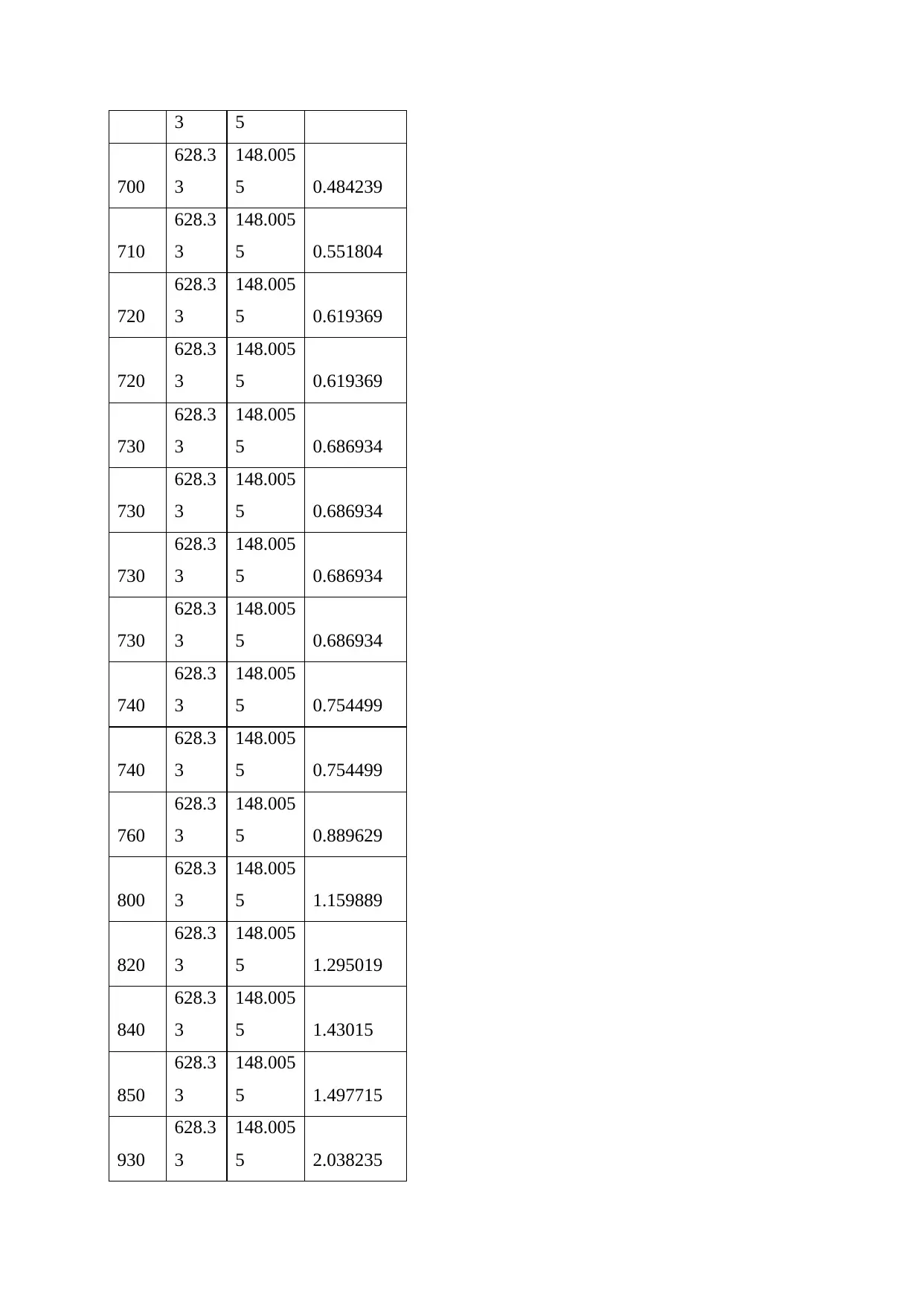
This document presents a comprehensive solution to an STA101 Statistics for Business assignment. The assignment covers various aspects of data analysis, including data types (categorical, discrete, and continuous), measurement scales (nominal, ordinal, interval, and ratio), and descriptive statistics such as mean, median, and mode. It delves into the calculation and interpretation of standard deviation, the identification of outliers using Z-scores, and the application of the Empirical Rule to assess data normality. Furthermore, the solution addresses probability calculations, including the probability of alternator failures, and provides a detailed analysis of student performance on quizzes, comparing measures of central tendency and assessing data symmetry. The document also includes a confidence interval calculation and a sample size determination, along with a visual representation of the data through a line chart and concludes with a list of references.





1 out of 15
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.