STA2300 Data Analysis S1, 20 Assignment 1: Statistical Analysis Report
VerifiedAdded on 2022/09/15
|7
|1303
|16
Homework Assignment
AI Summary
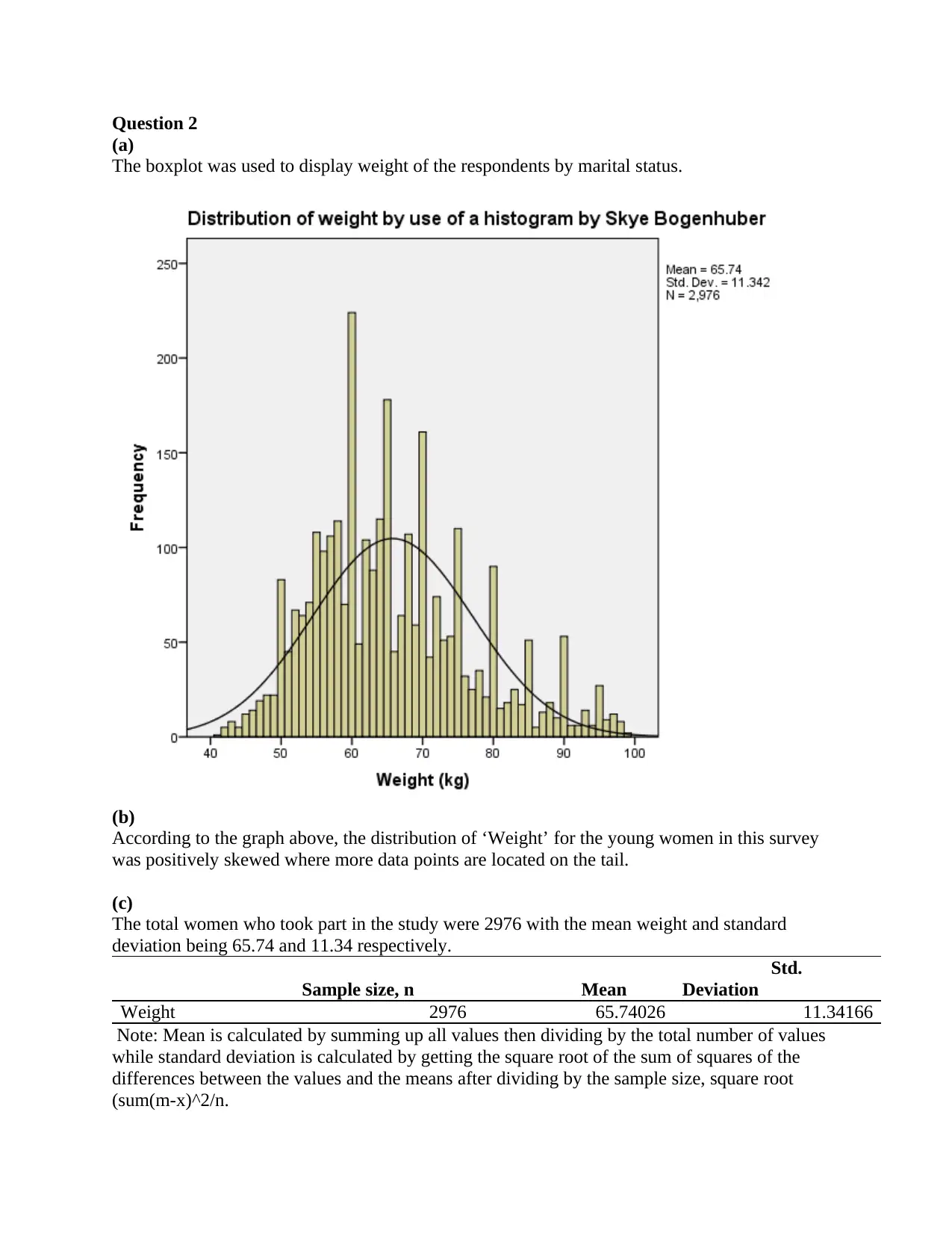
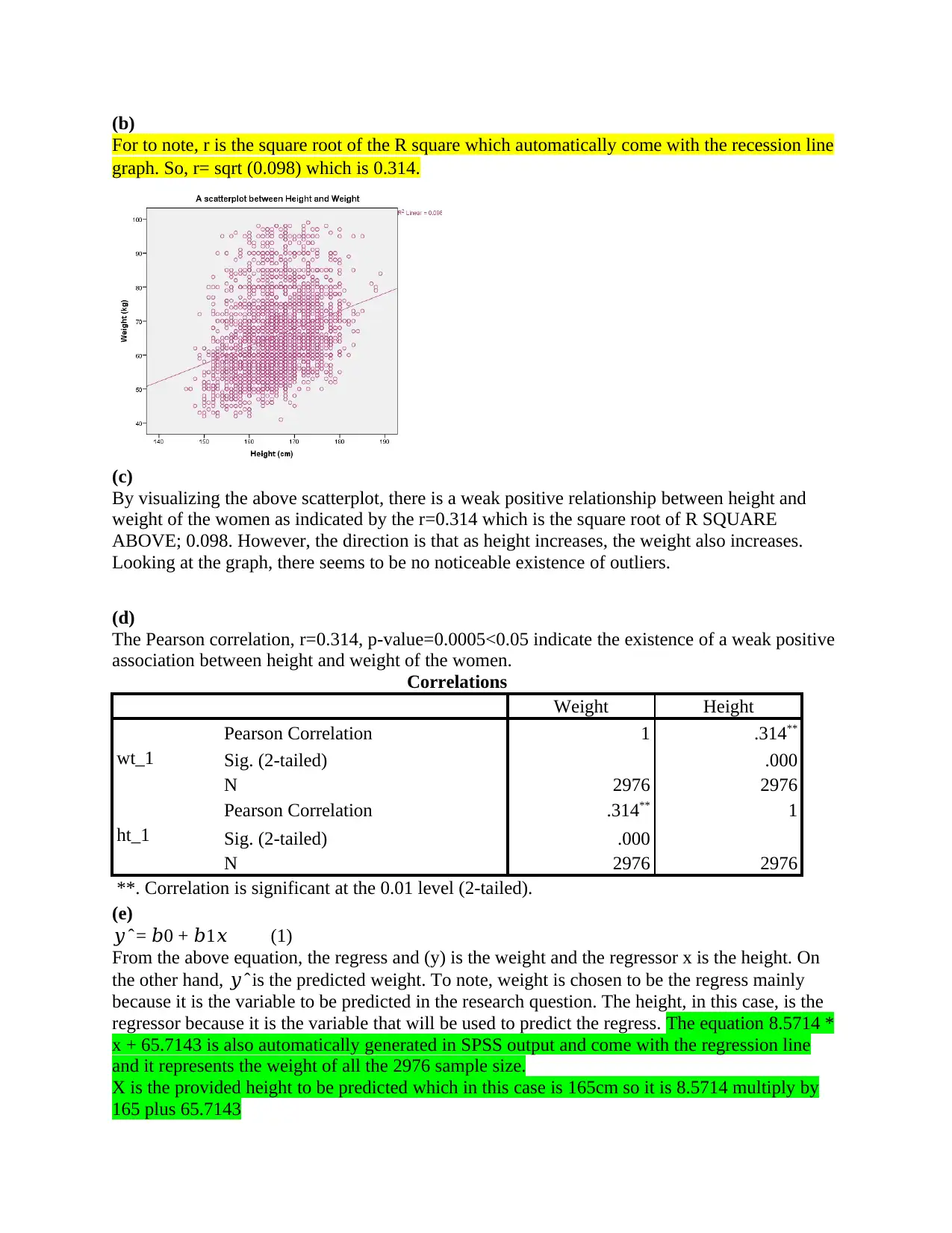
This document presents the solutions to STA2300 Data Analysis Assignment 1, covering various statistical concepts and methods. The assignment analyzes data using boxplots, correlation, regression analysis, and binomial distribution, and includes the interpretation of SPSS output. The solution addresses questions related to the distribution of weight, calculation of proportions, correlation between height and weight, regression equation, model parameters, and experimental study design. It also addresses potential confounders and the interpretation of study findings. The solutions provide detailed explanations and calculations, demonstrating a comprehensive understanding of the statistical concepts and their practical application.





1 out of 7
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.