Statistics Assignment: Analysis of Startup Costs in Businesses
VerifiedAdded on 2020/03/16
|10
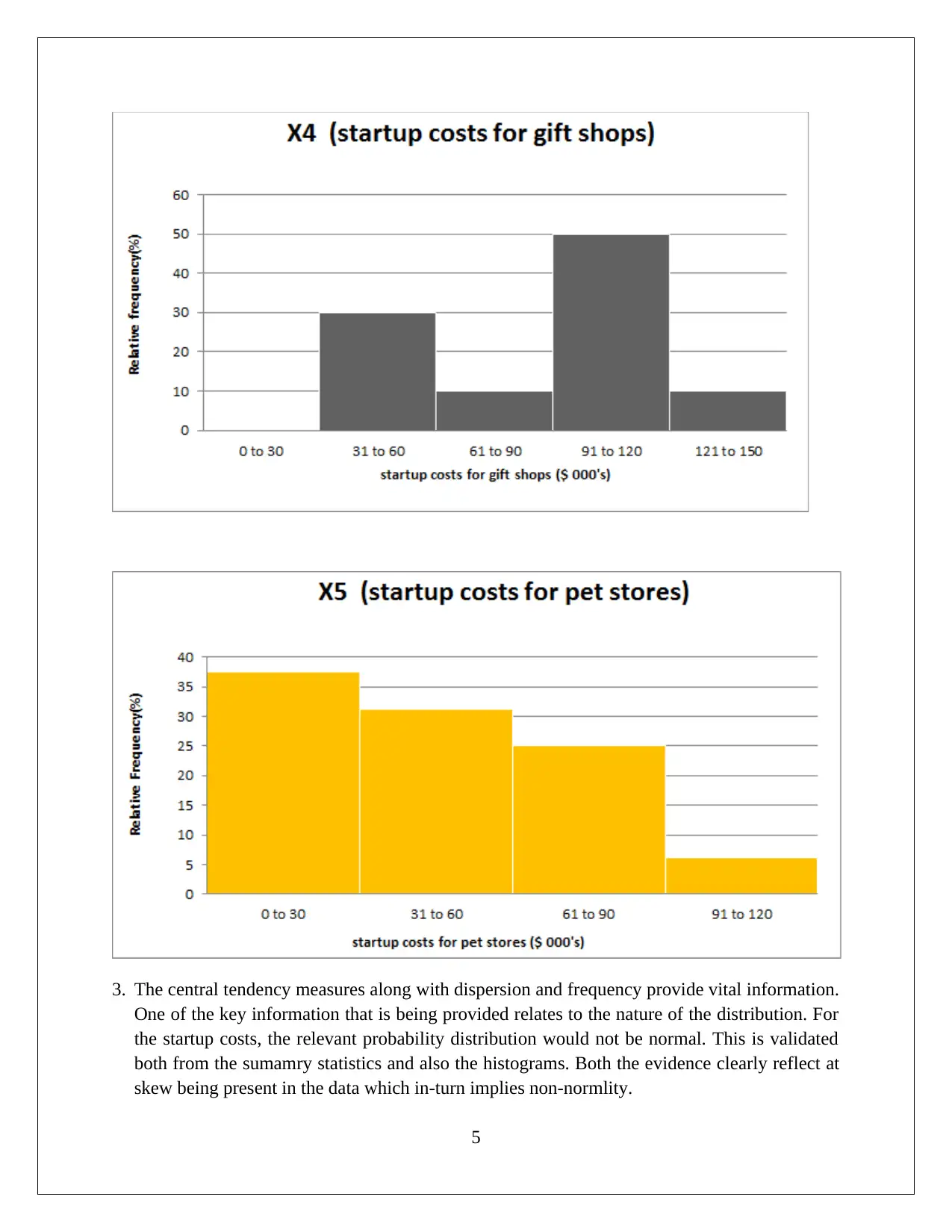
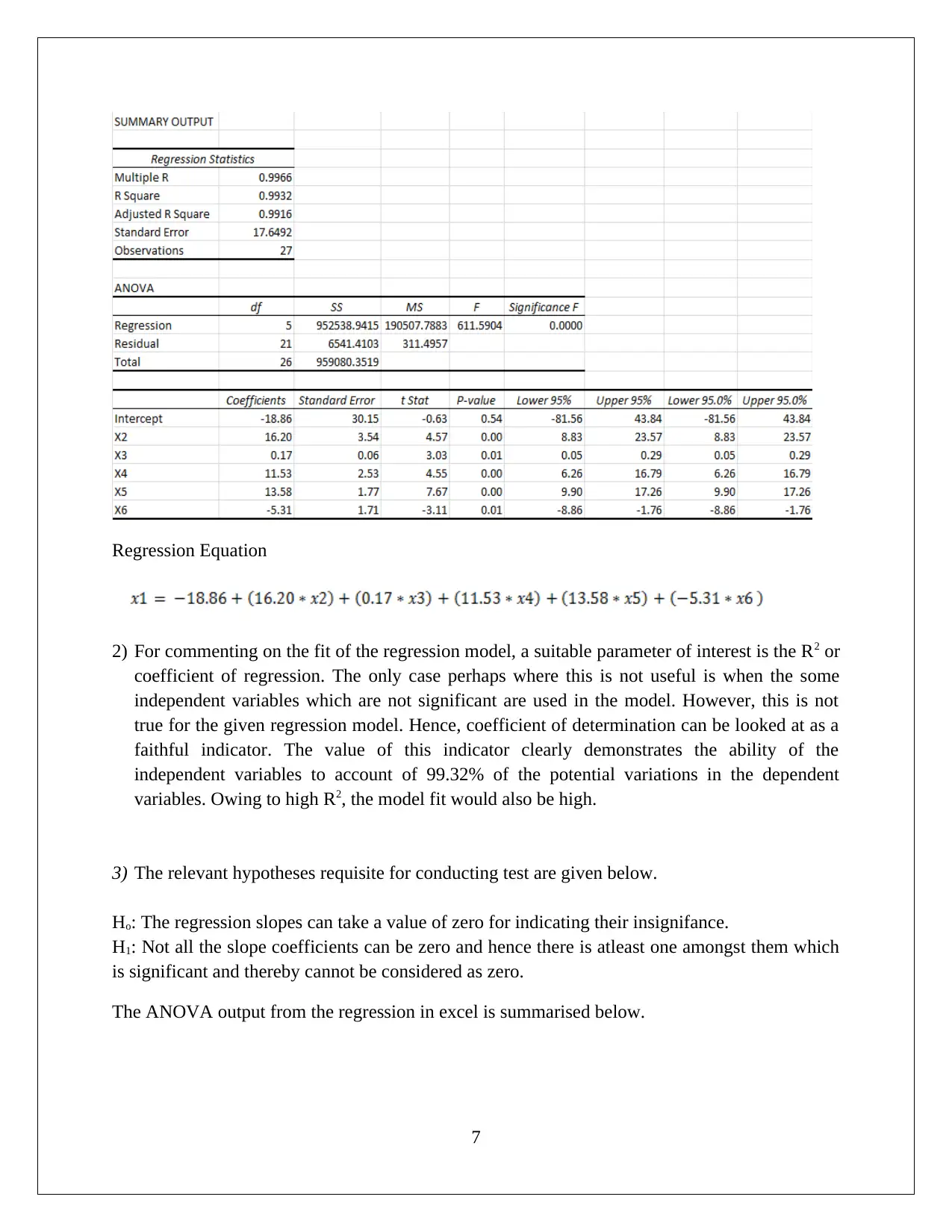
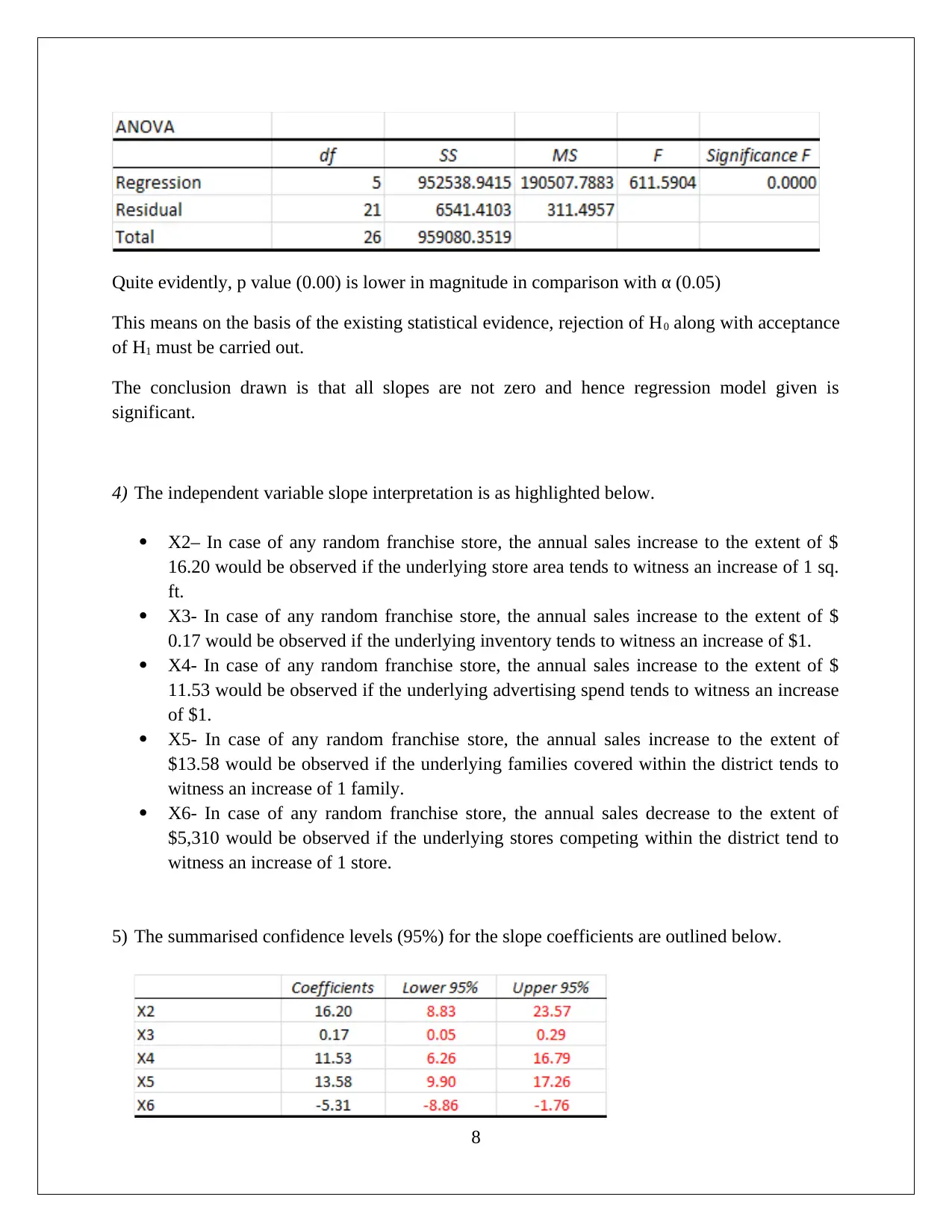
|1066
|159
Homework Assignment
AI Summary
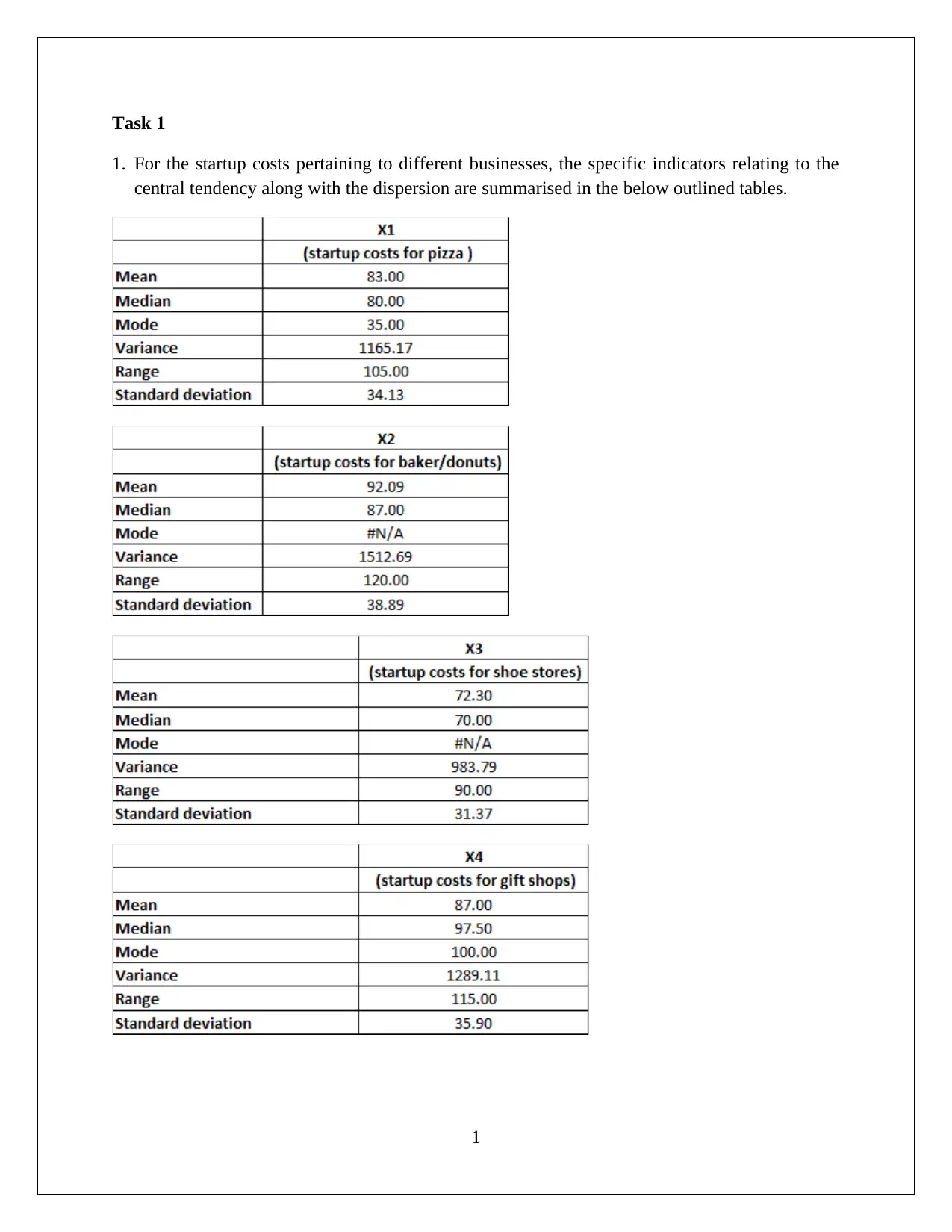
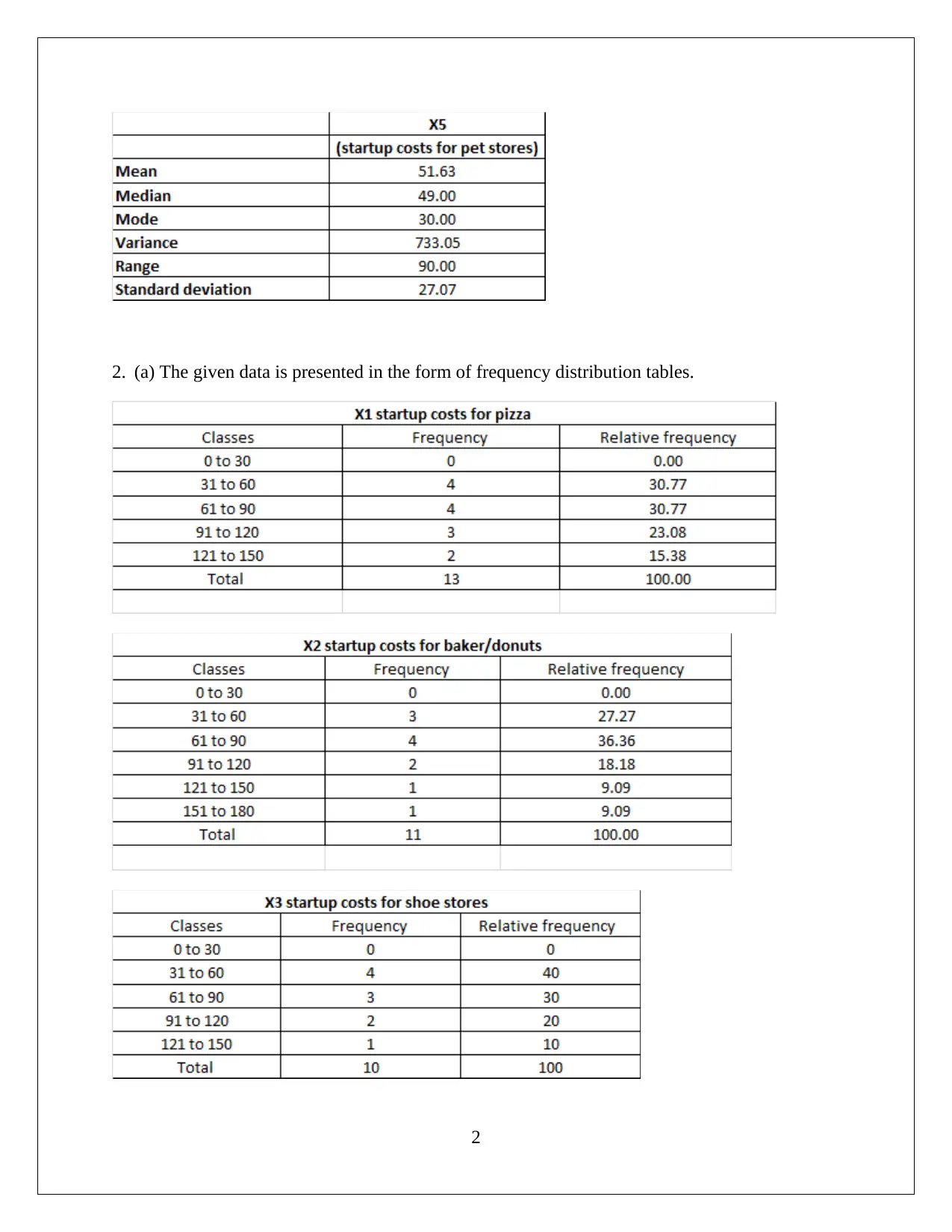
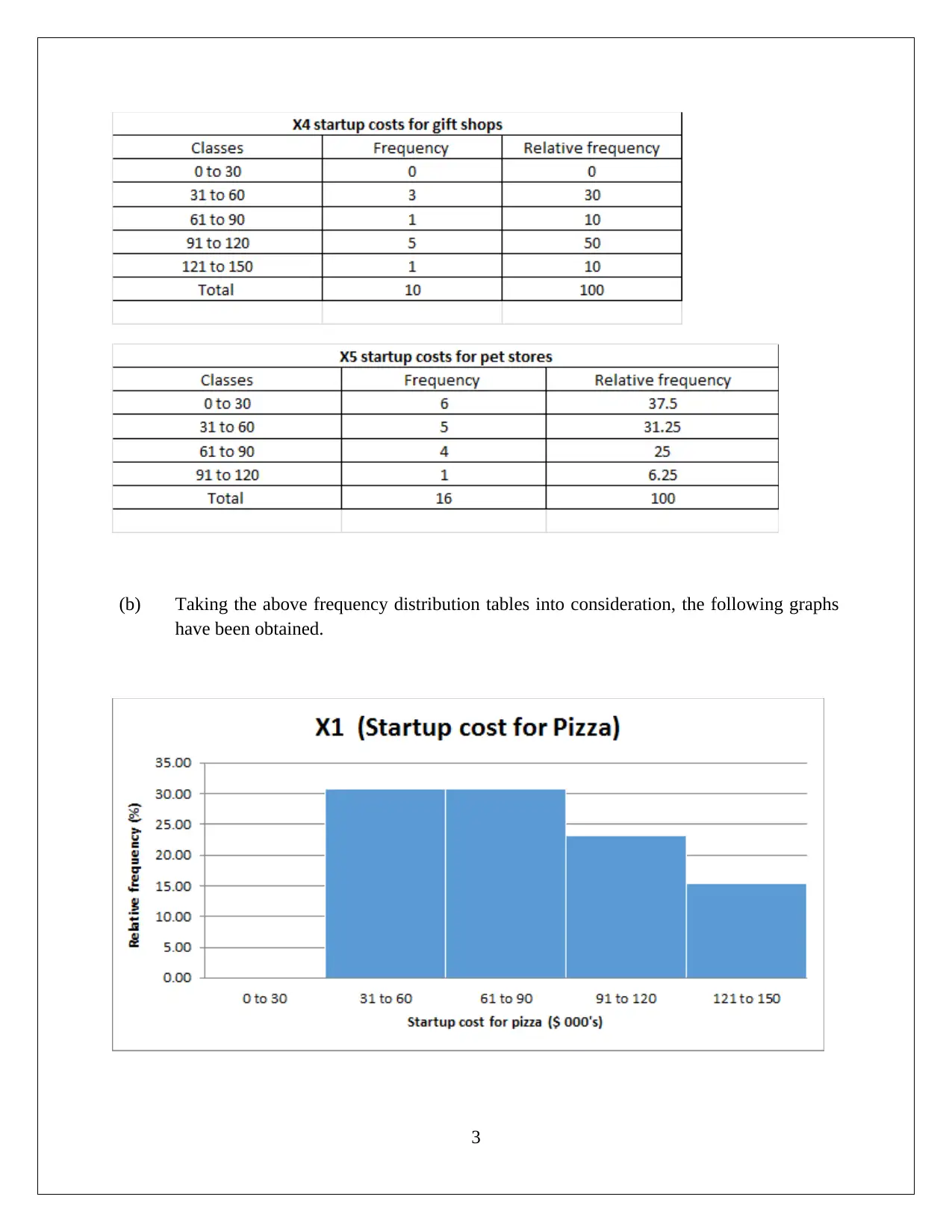
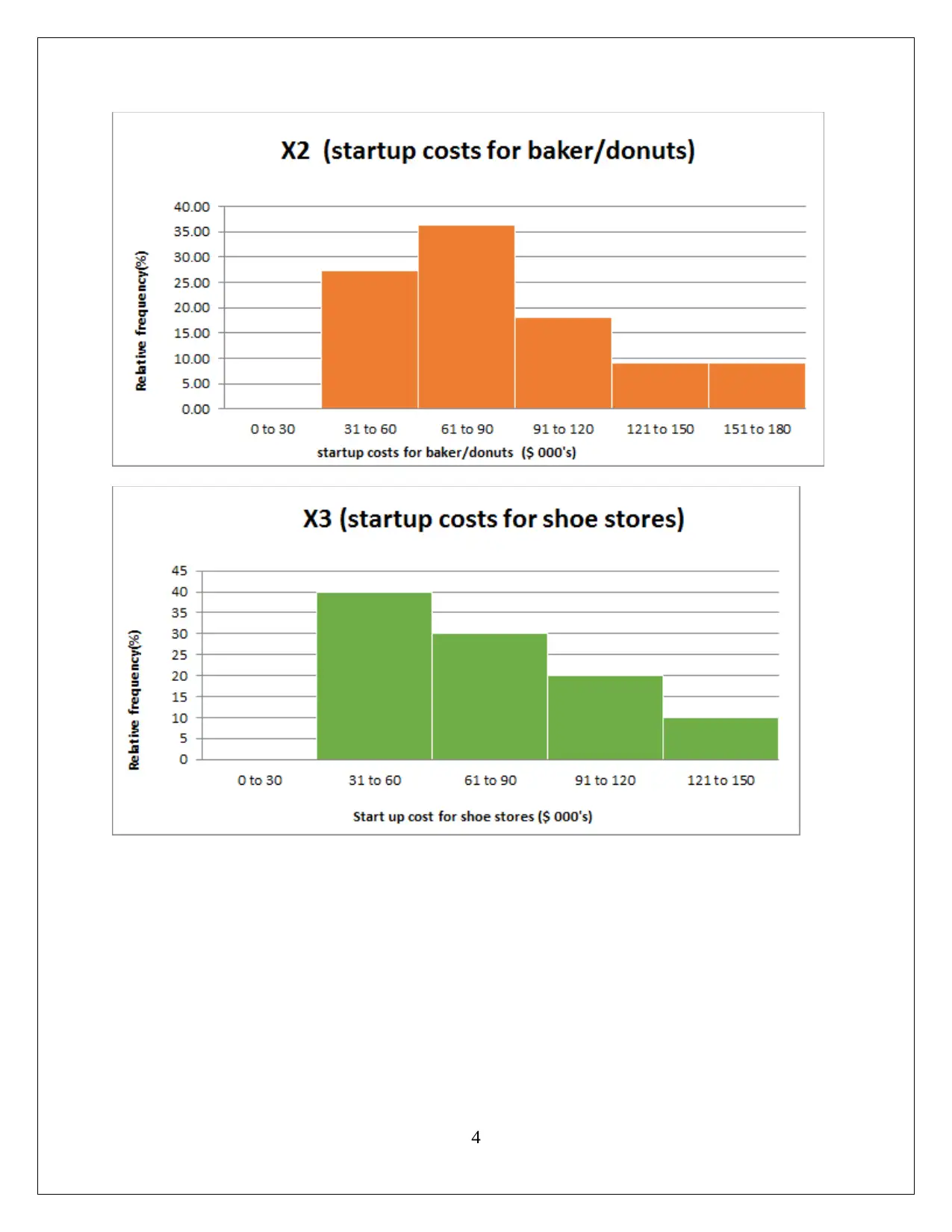
This statistics assignment analyzes startup costs across various businesses using frequency distribution tables and graphical representations to assess data normality and central tendency. The analysis includes hypothesis testing using ANOVA to compare average startup costs across different businesses, revealing significant variations. Additionally, a regression model is developed to explore the relationship between annual sales and various factors like store area, inventory, advertising spend, families covered, and competing stores. The regression model's high R-squared value indicates a strong fit, and hypothesis testing confirms the significance of all slope coefficients. The assignment provides detailed interpretations of the slope coefficients and confidence intervals, offering insights into how different variables impact sales. The student concludes that the model is significant and all slopes are significant.



1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.