Analysis of Station Usage Data: Eccleston Park (2009-2018) Report
VerifiedAdded on 2021/02/21
|10
|1435
|29
Report
AI Summary
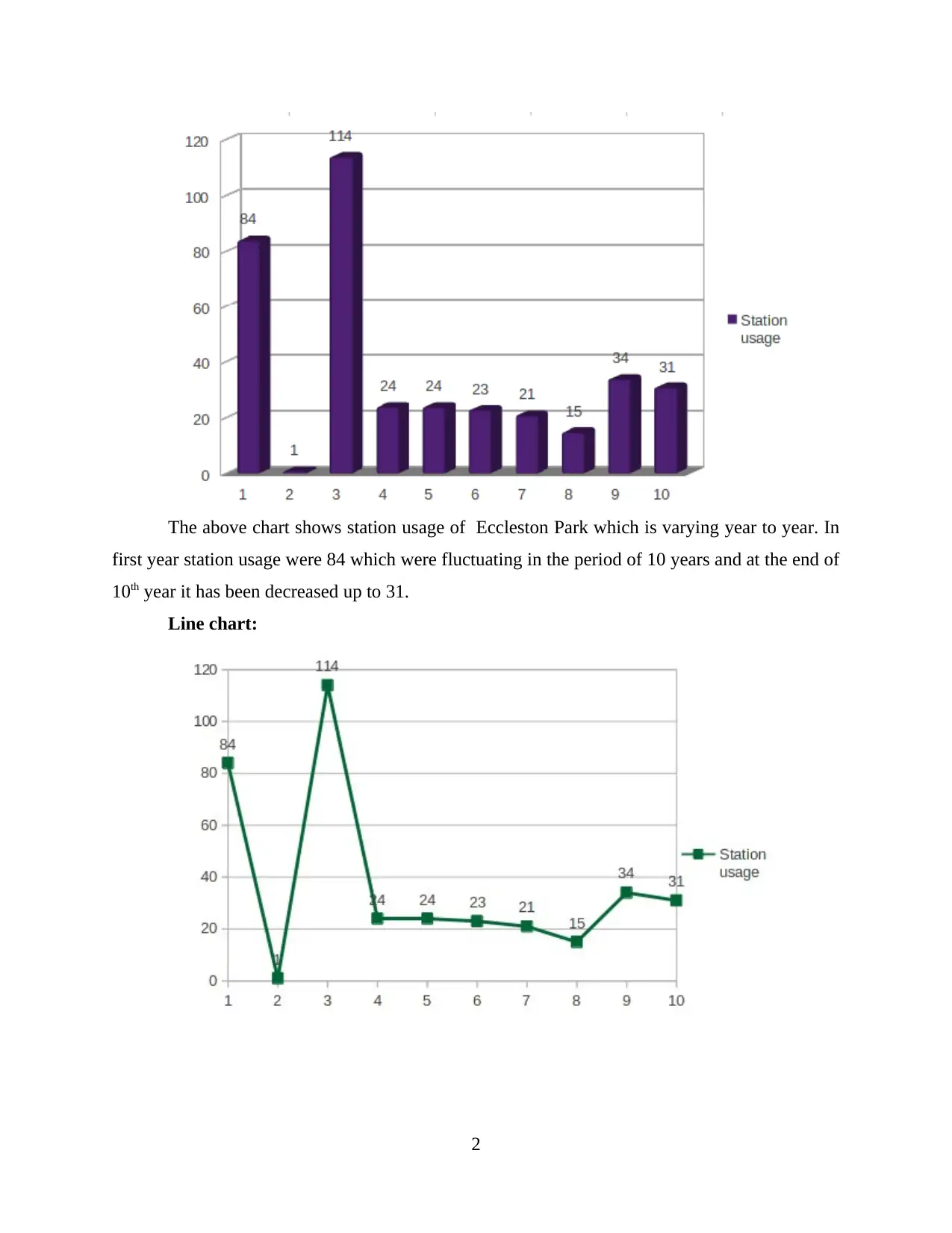
This report provides a comprehensive data analysis of Eccleston Park station usage from 2009 to 2018. It begins with an introduction to data analysis, followed by a presentation of the data in tabular form. The report includes the use of column and line charts to visually represent the data. Furthermore, it calculates and explains key statistical measures such as mean, median, mode, range, and standard deviation. A significant part of the report focuses on the application of a linear forecasting model to predict future station usage. The report concludes with a summary of the findings and a list of cited references. This report is designed to demonstrate the application of various data analysis techniques to real-world data, providing valuable insights into station usage trends.









1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.