Statistics Assignment: Data Analysis, Regression, and Model Evaluation
VerifiedAdded on 2020/03/16
|13
|1605
|225
Homework Assignment
AI Summary
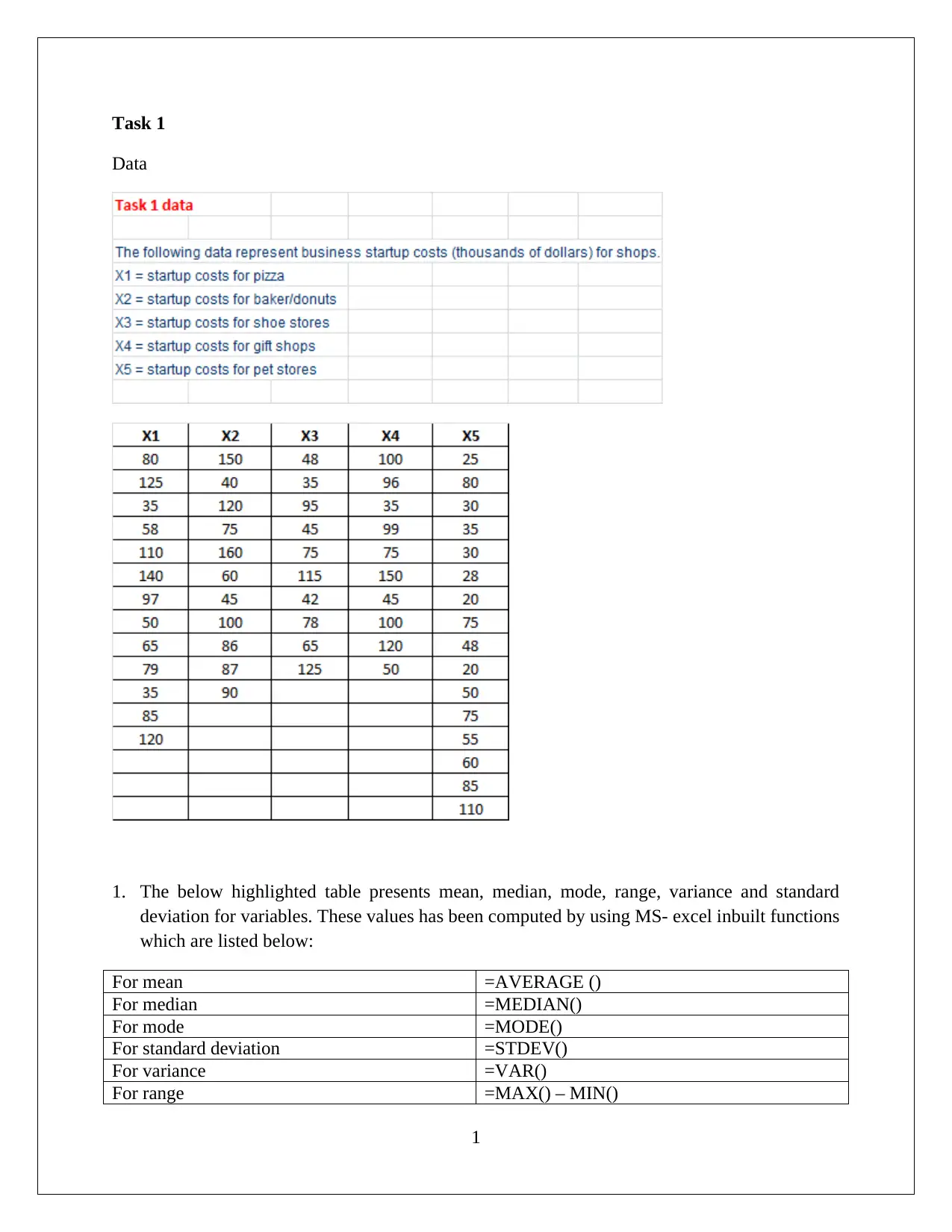
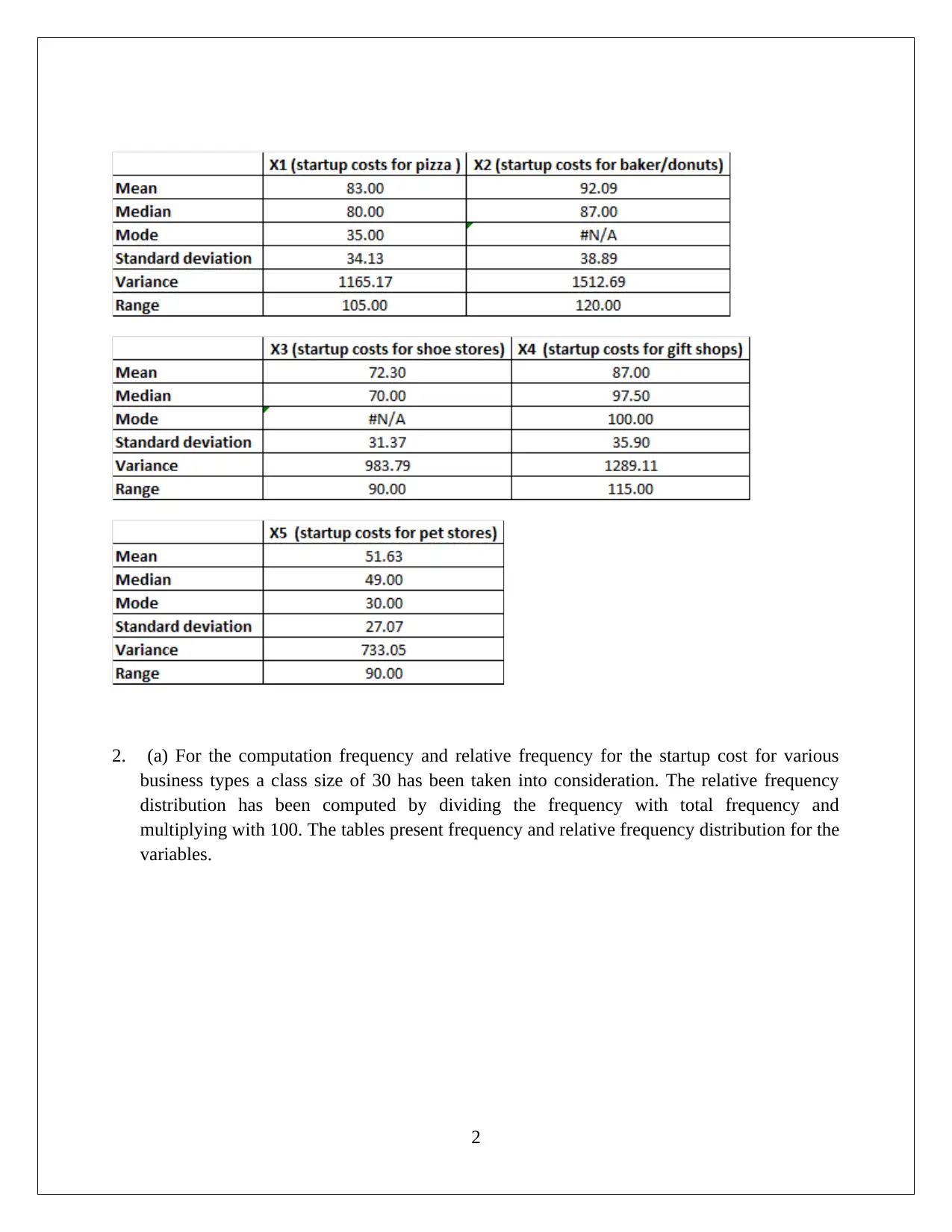
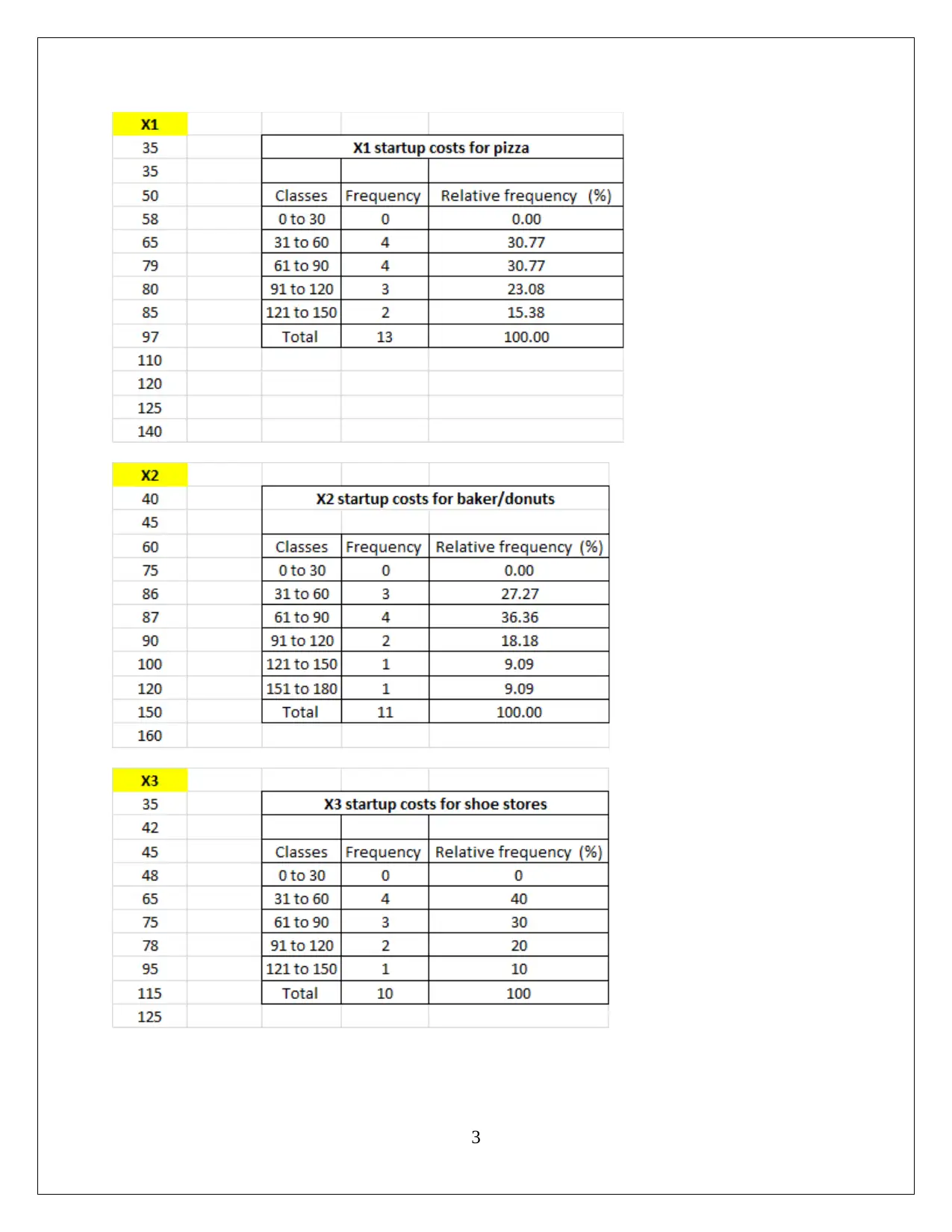
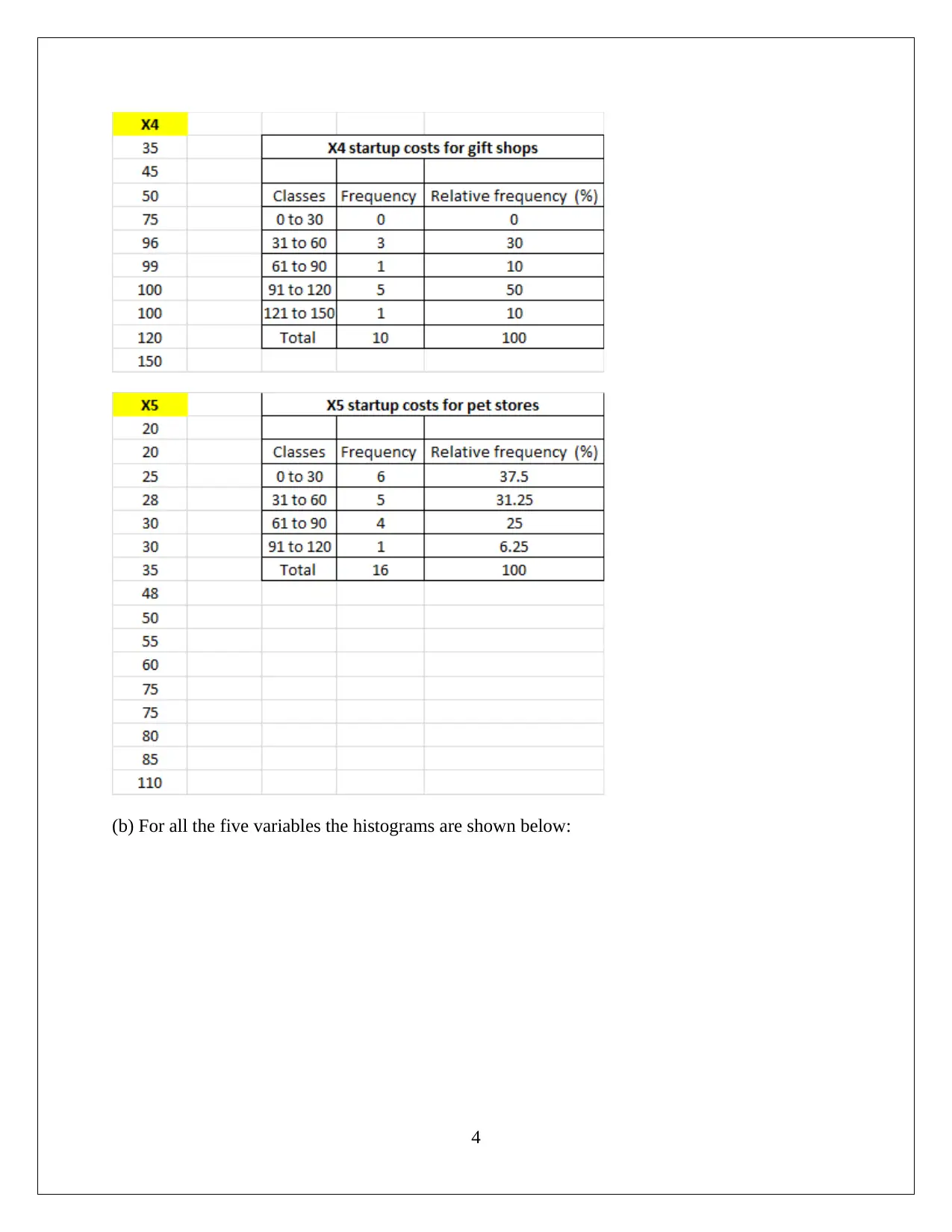
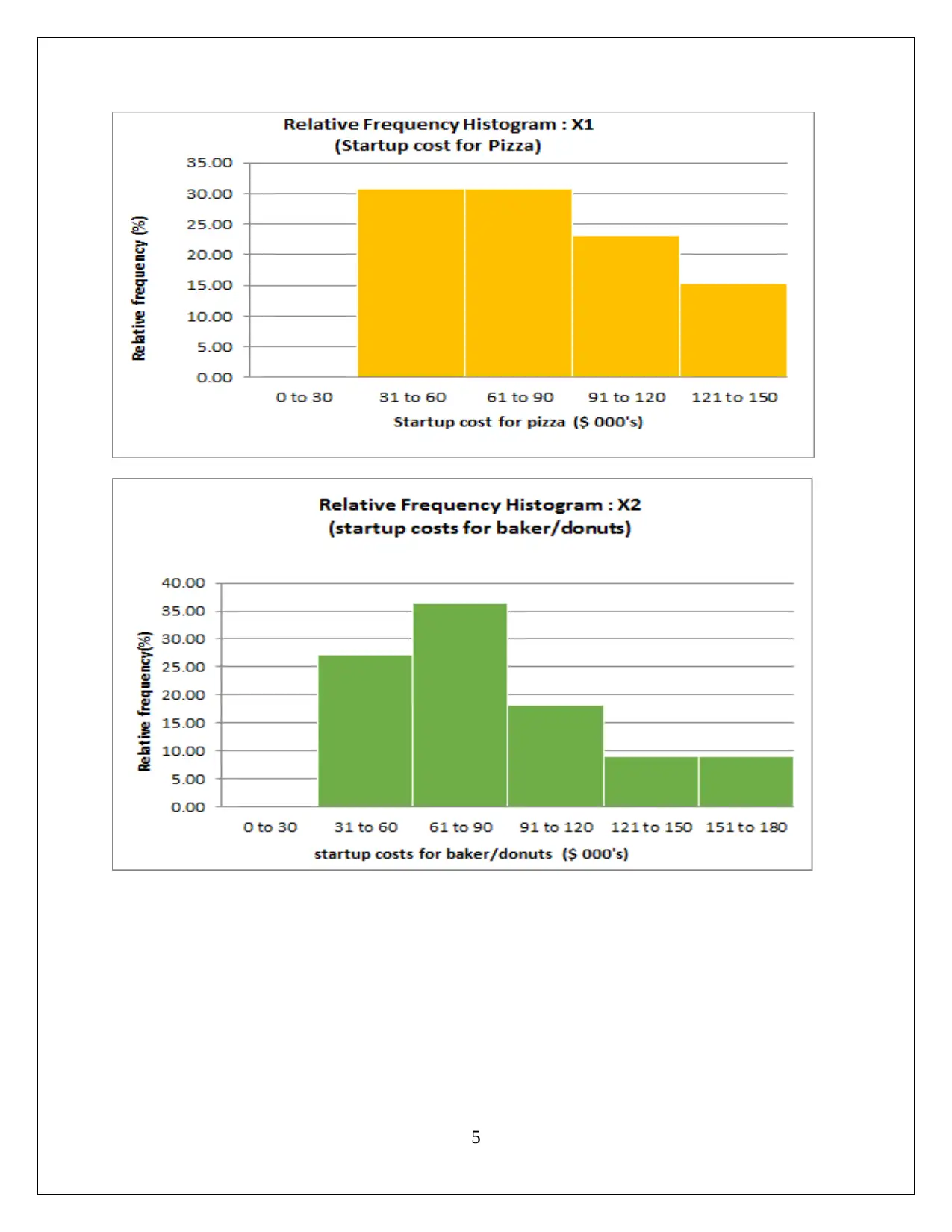
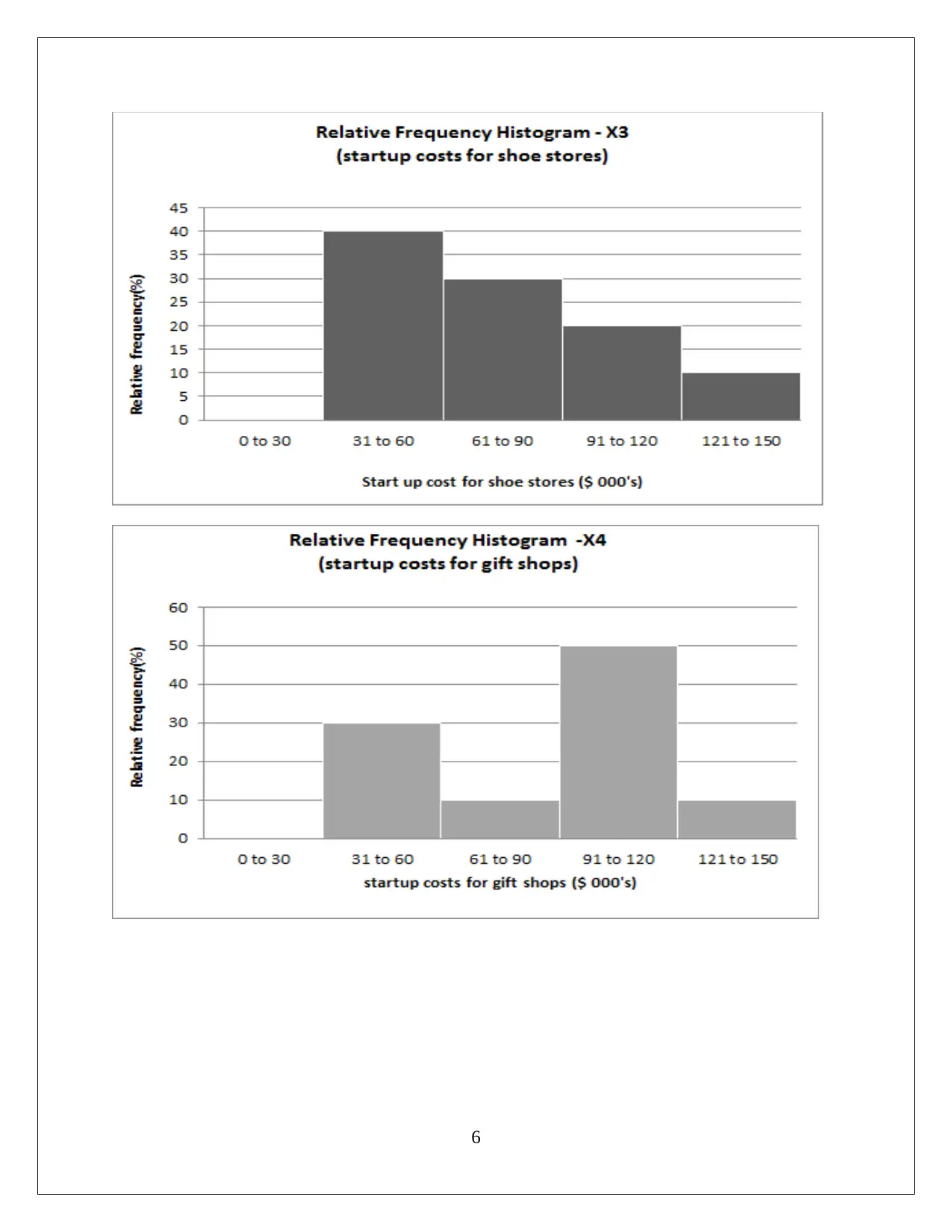
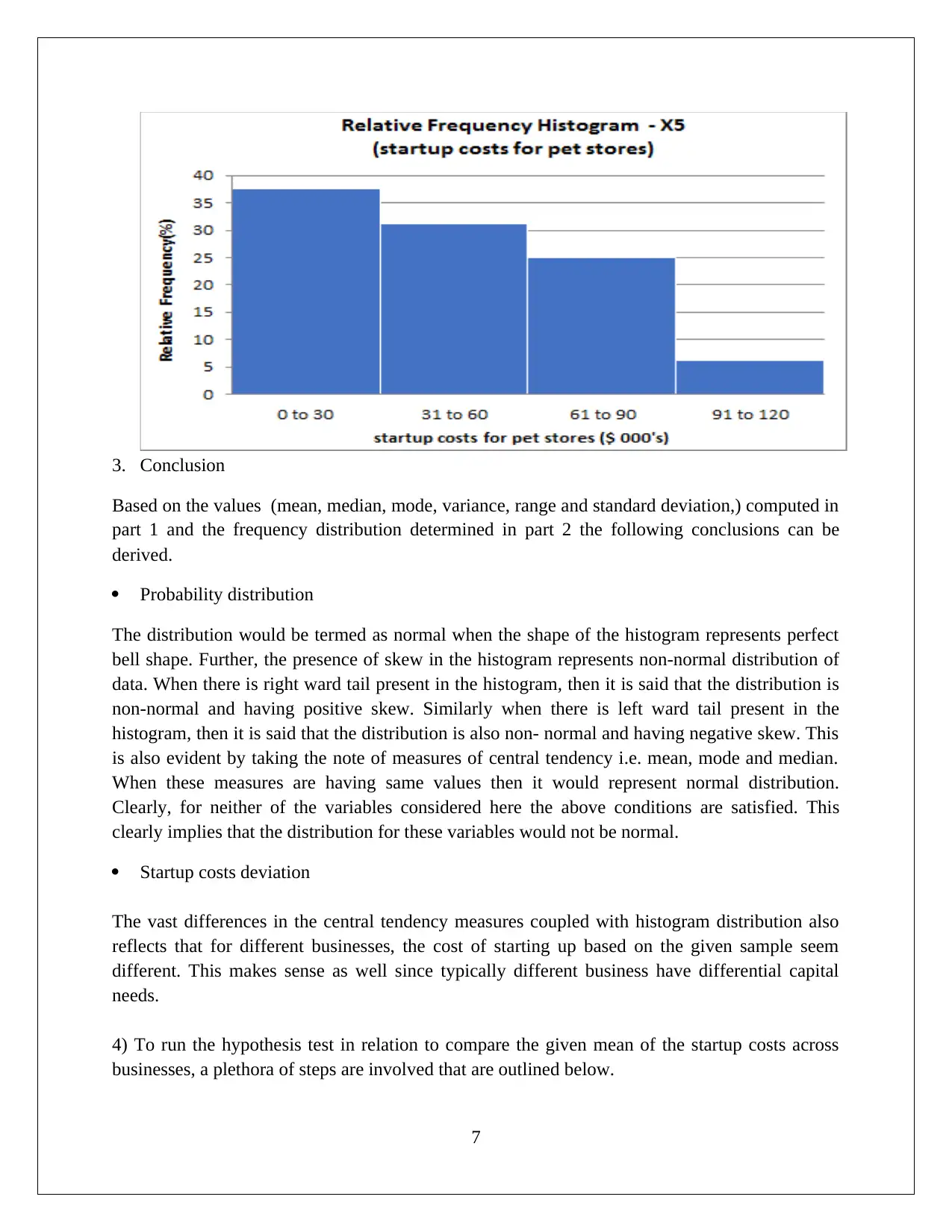
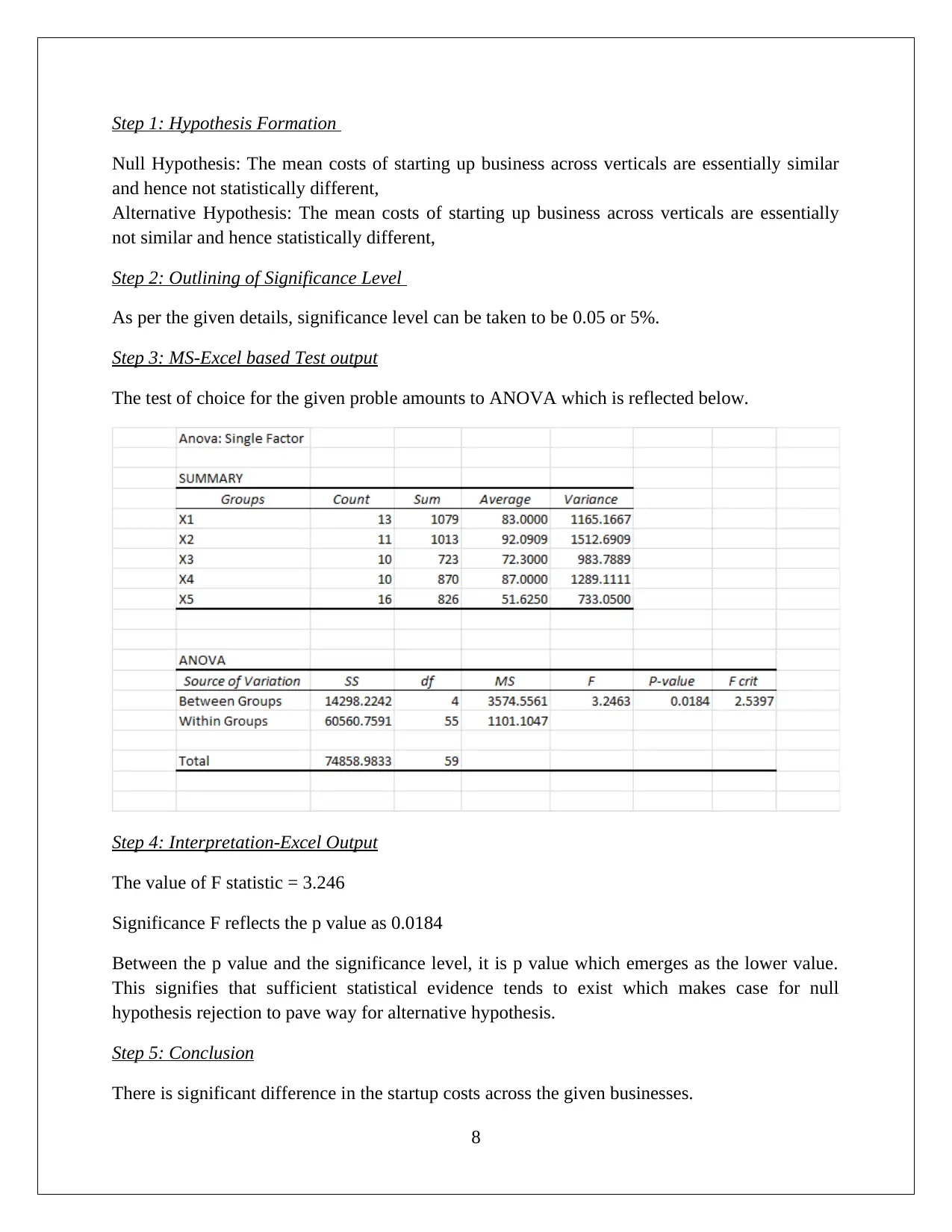
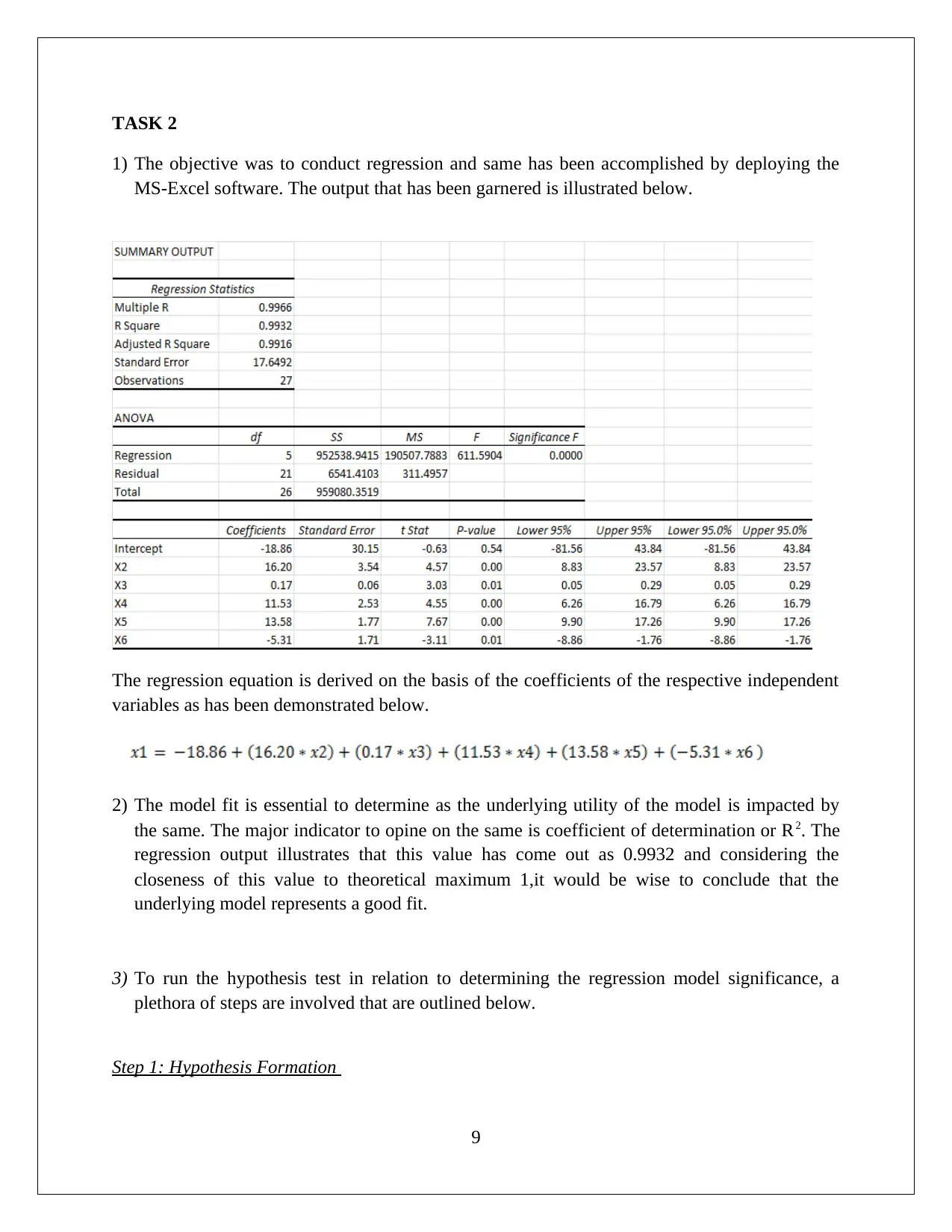
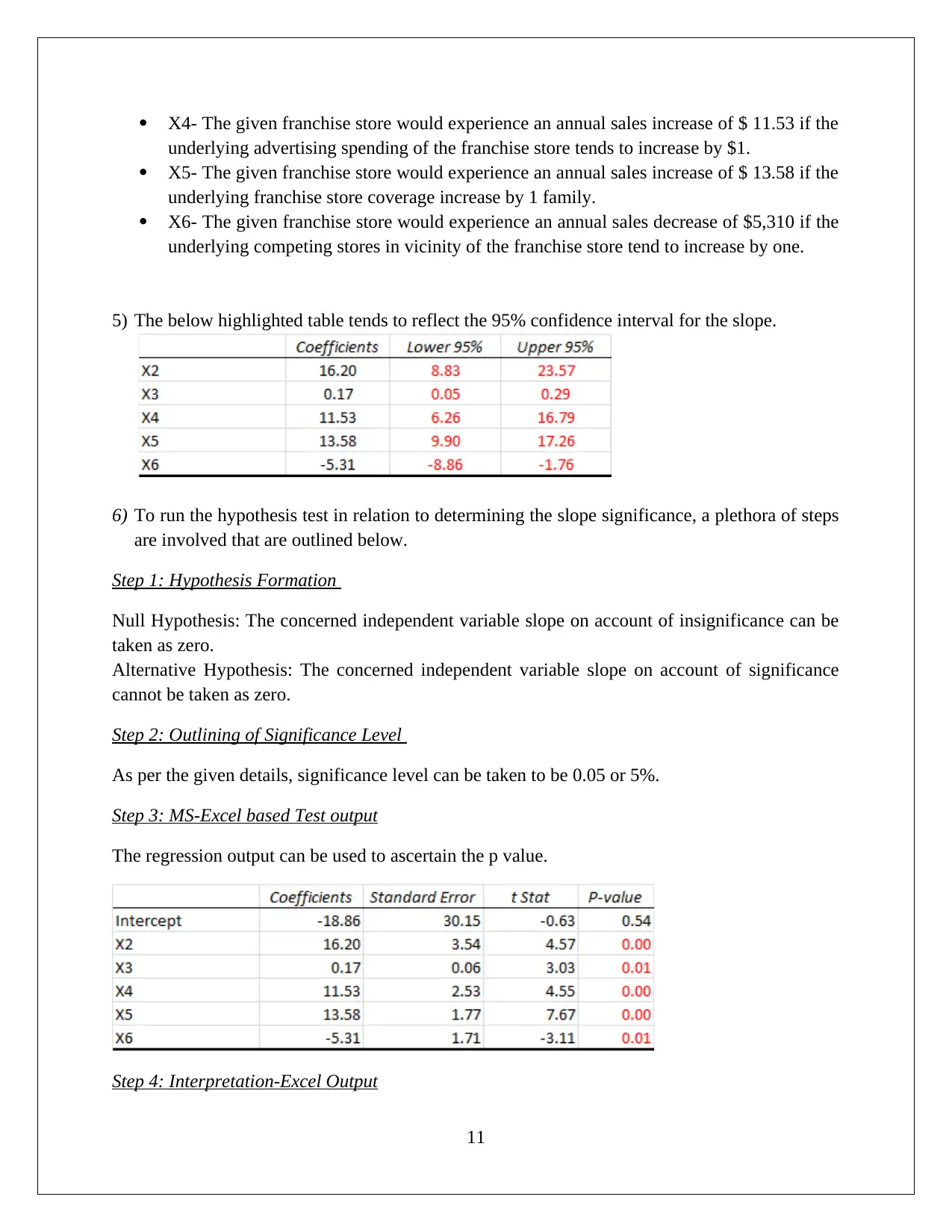
This statistics assignment presents a comprehensive analysis of data, encompassing descriptive statistics, hypothesis testing, and regression analysis. The assignment begins with the computation of descriptive statistics (mean, median, mode, range, variance, and standard deviation) using MS Excel, followed by frequency and relative frequency distributions and the creation of histograms. The first task focuses on comparing startup costs across different business types, including ANOVA and hypothesis testing to determine if there are significant differences in startup costs. The second task delves into regression analysis, utilizing MS Excel to develop a regression model. The solution includes the regression equation, model fit assessment, and hypothesis testing for both the overall model and individual slopes of the independent variables. The interpretation of coefficients, confidence intervals, and conclusions regarding variable significance are also provided. The conclusion affirms the significance of each slope, supporting the inclusion of all independent variables in the regression model.


1 out of 13
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.