Statistical Analysis for Decision Making: STAT1060 Assignment 2
VerifiedAdded on 2022/11/11
|10
|1087
|152
Homework Assignment
AI Summary
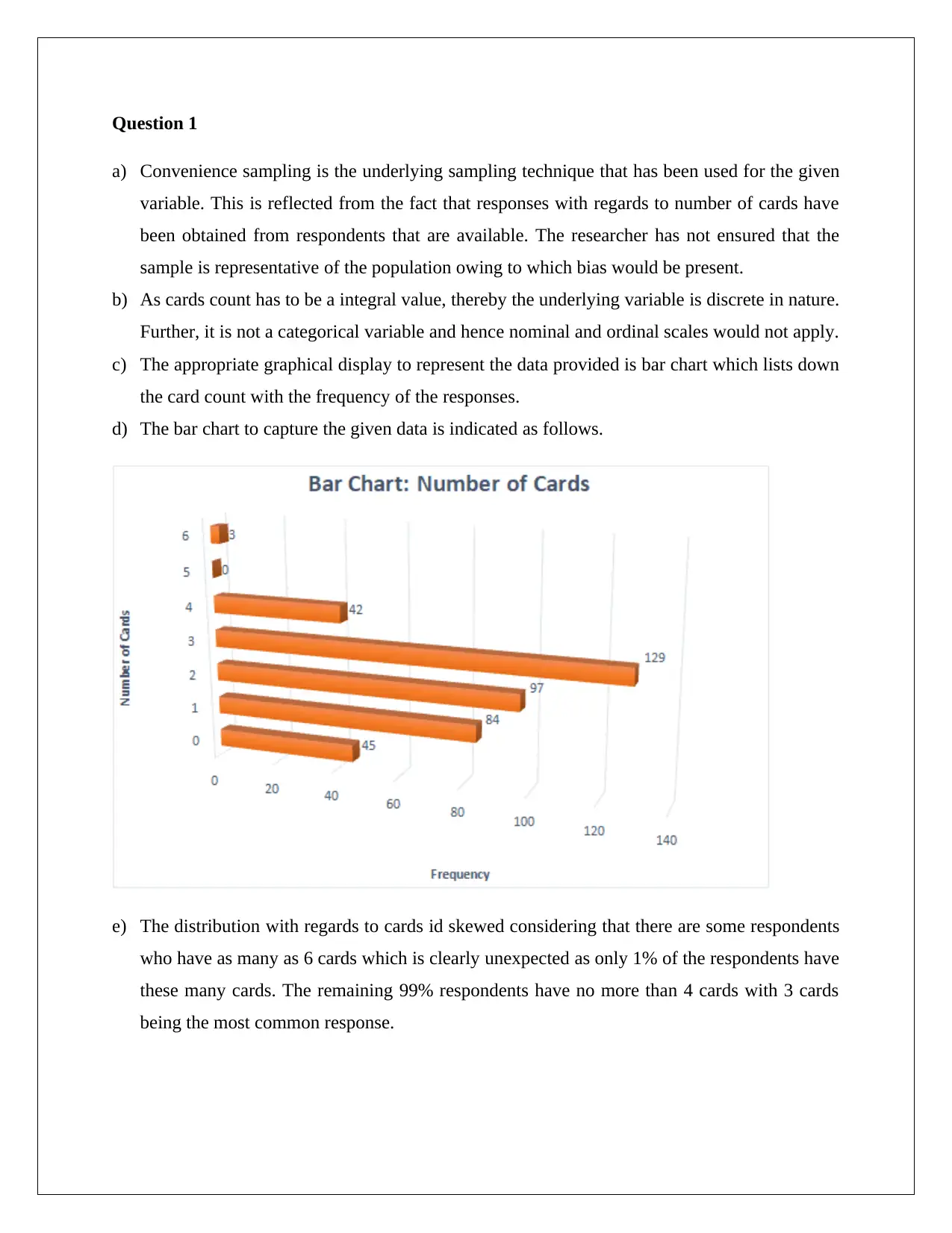
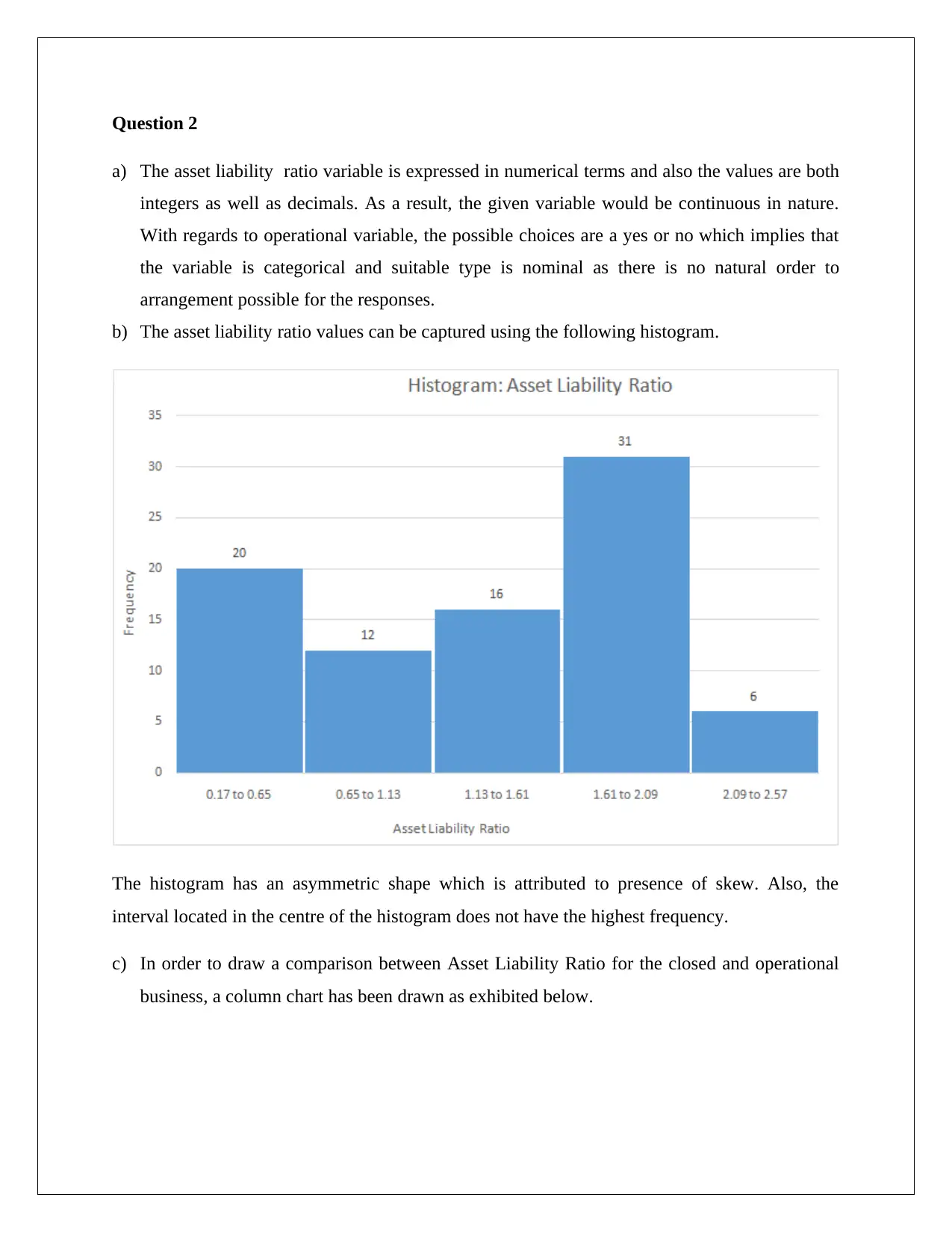
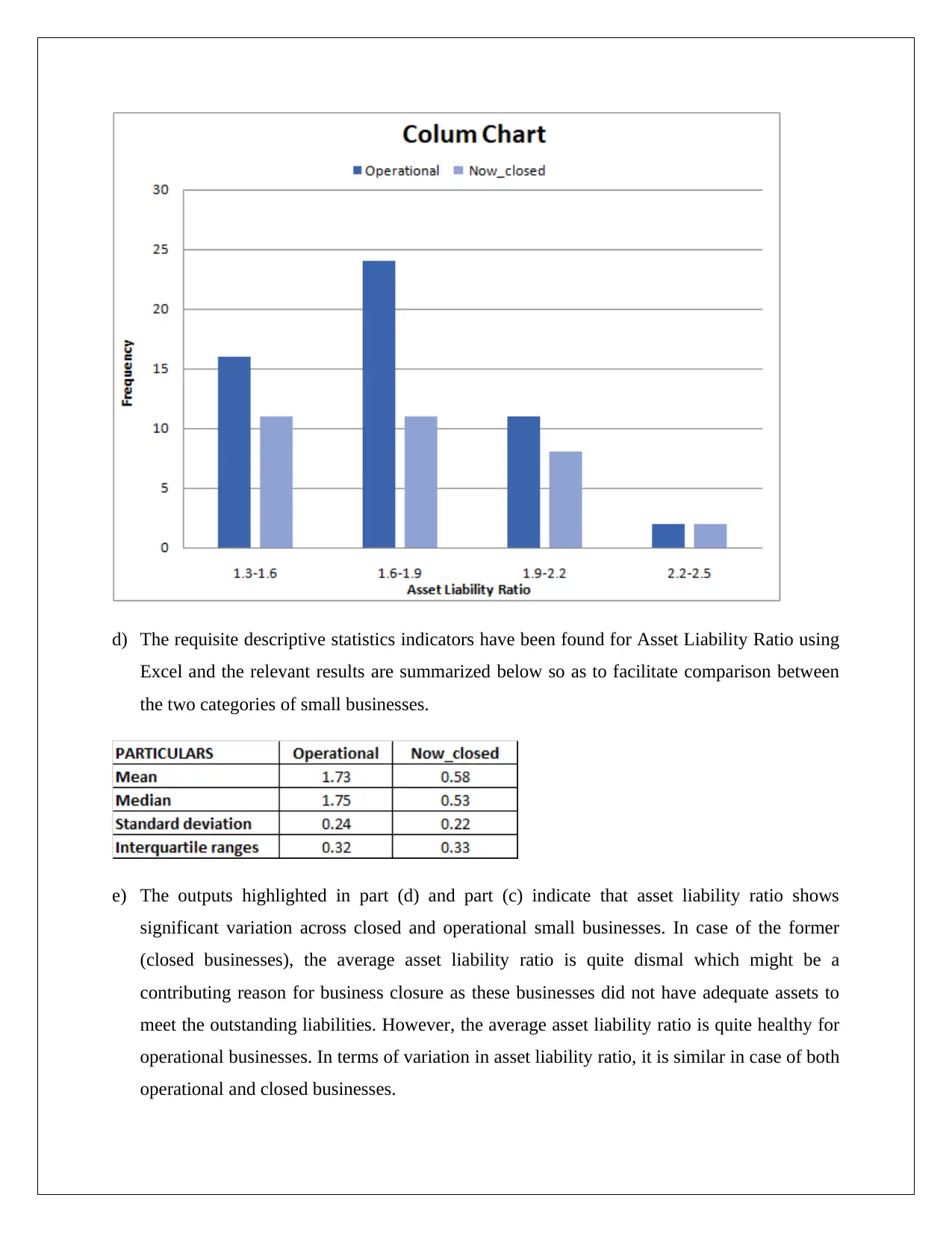
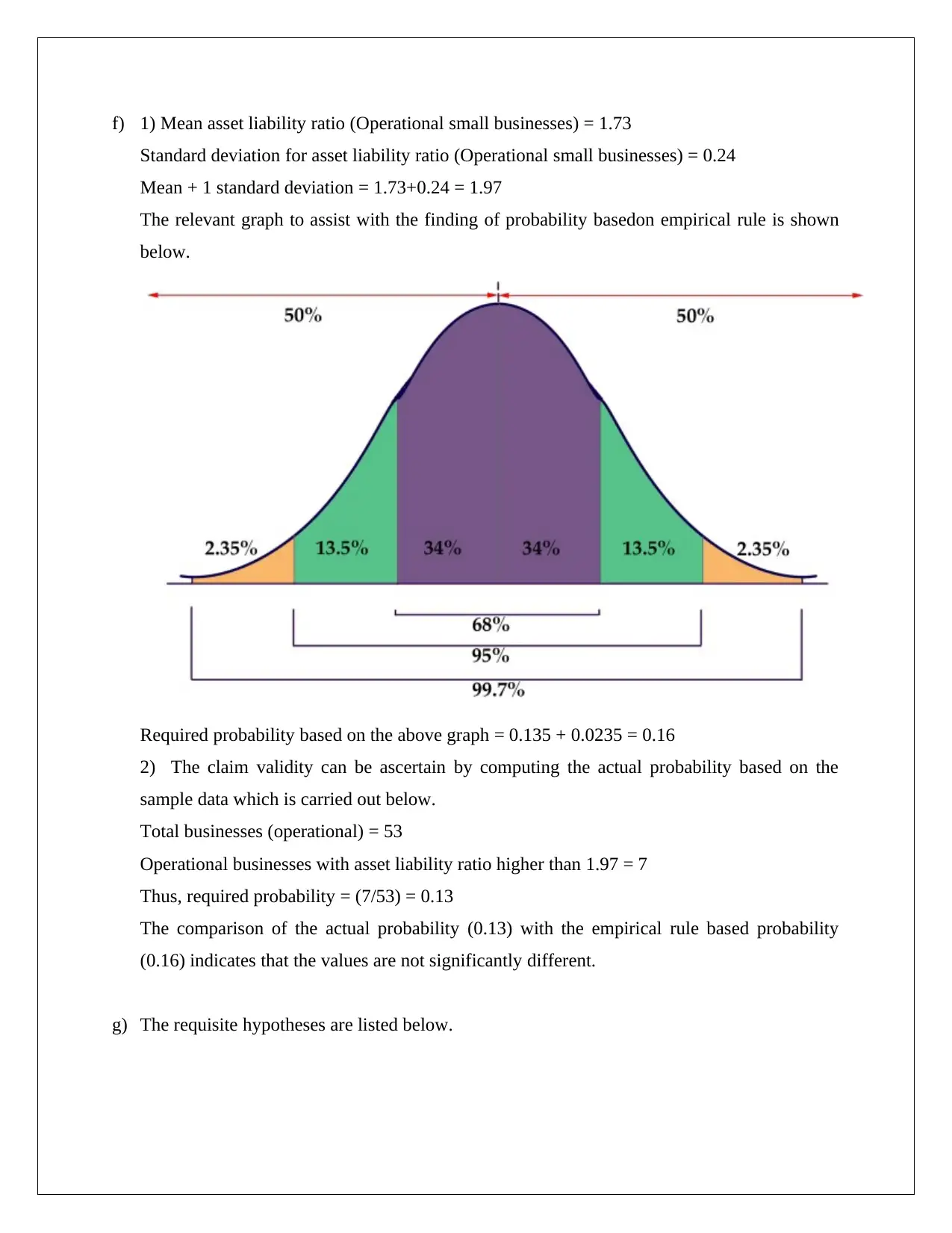
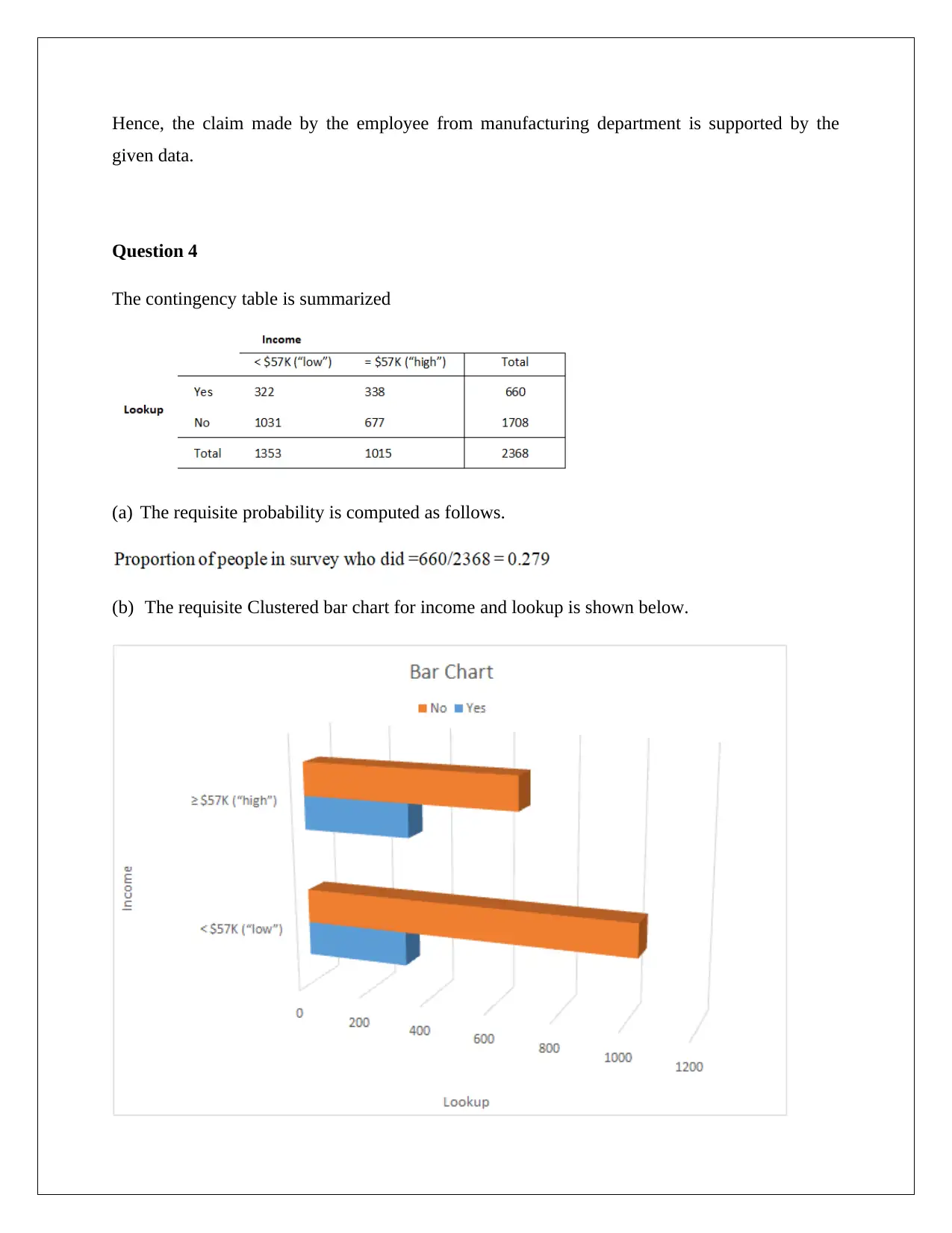
This assignment solution for STAT1060, focusing on statistical analysis for decision-making, addresses four key questions. Question 1 explores convenience sampling, data types (discrete), and appropriate graphical representations (bar charts) to analyze card counts. Question 2 delves into continuous and categorical variables, using histograms and column charts to compare asset liability ratios for closed and operational businesses, incorporating descriptive statistics and hypothesis testing with t-tests. Question 3 involves hypothesis testing to compare packaging abilities using t-tests. Question 4 analyzes a contingency table and calculates probabilities, employing chi-square tests to determine the relationship between income and lookup variables, providing a comprehensive statistical analysis with Excel output and interpretations.





1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.