Statistical Analysis and Data Interpretation Homework Assignment
VerifiedAdded on 2023/01/19
|9
|1545
|75
Homework Assignment
AI Summary
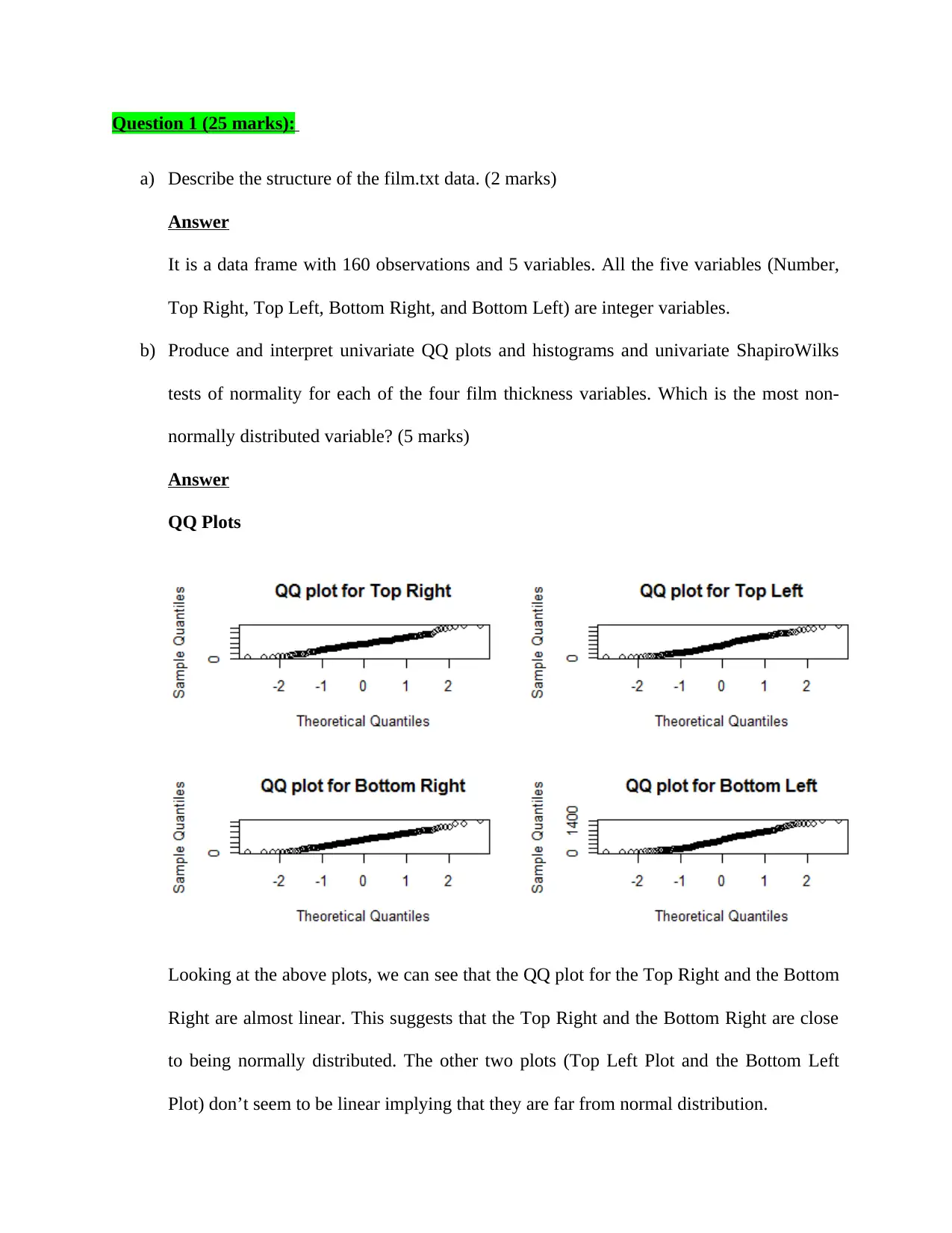
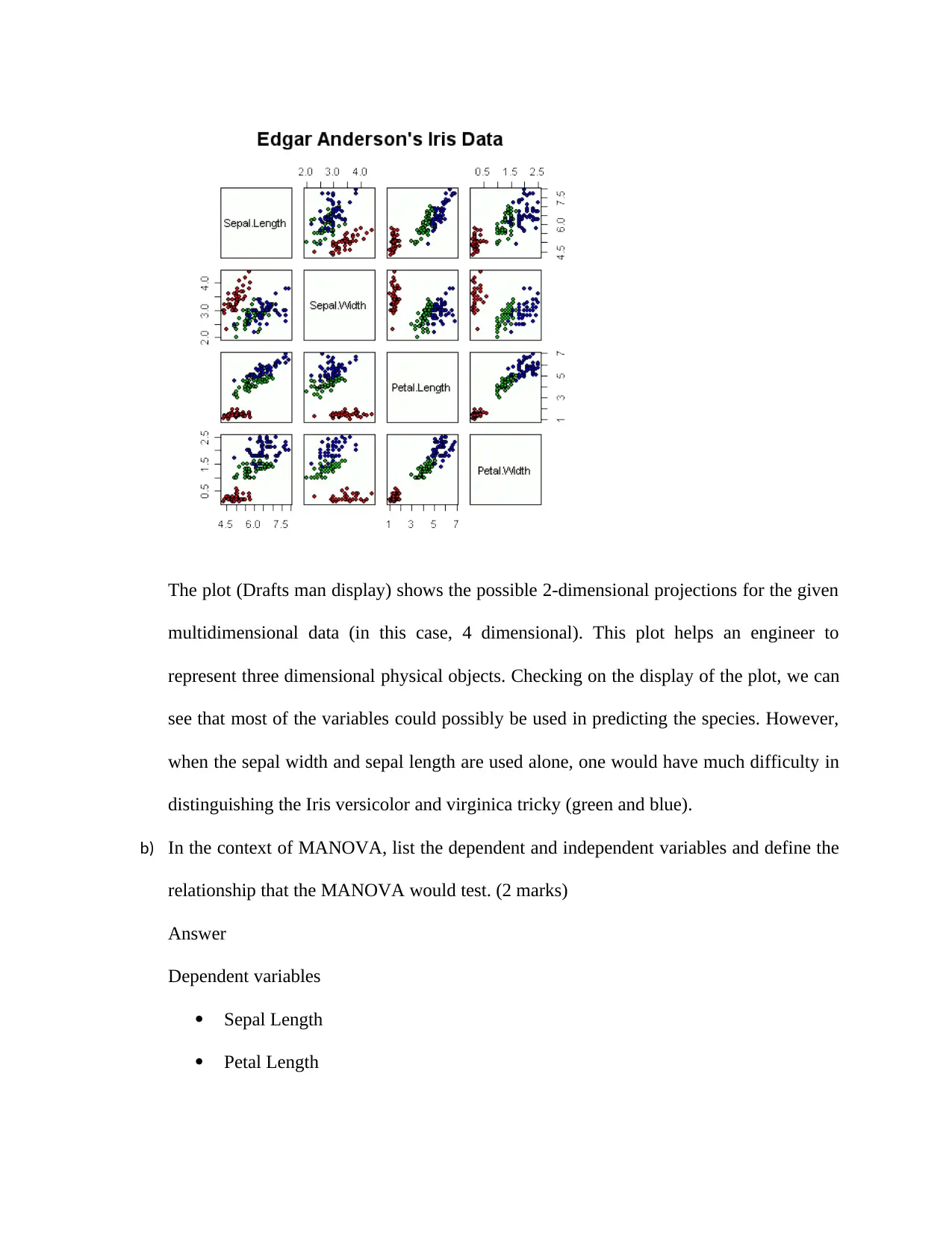
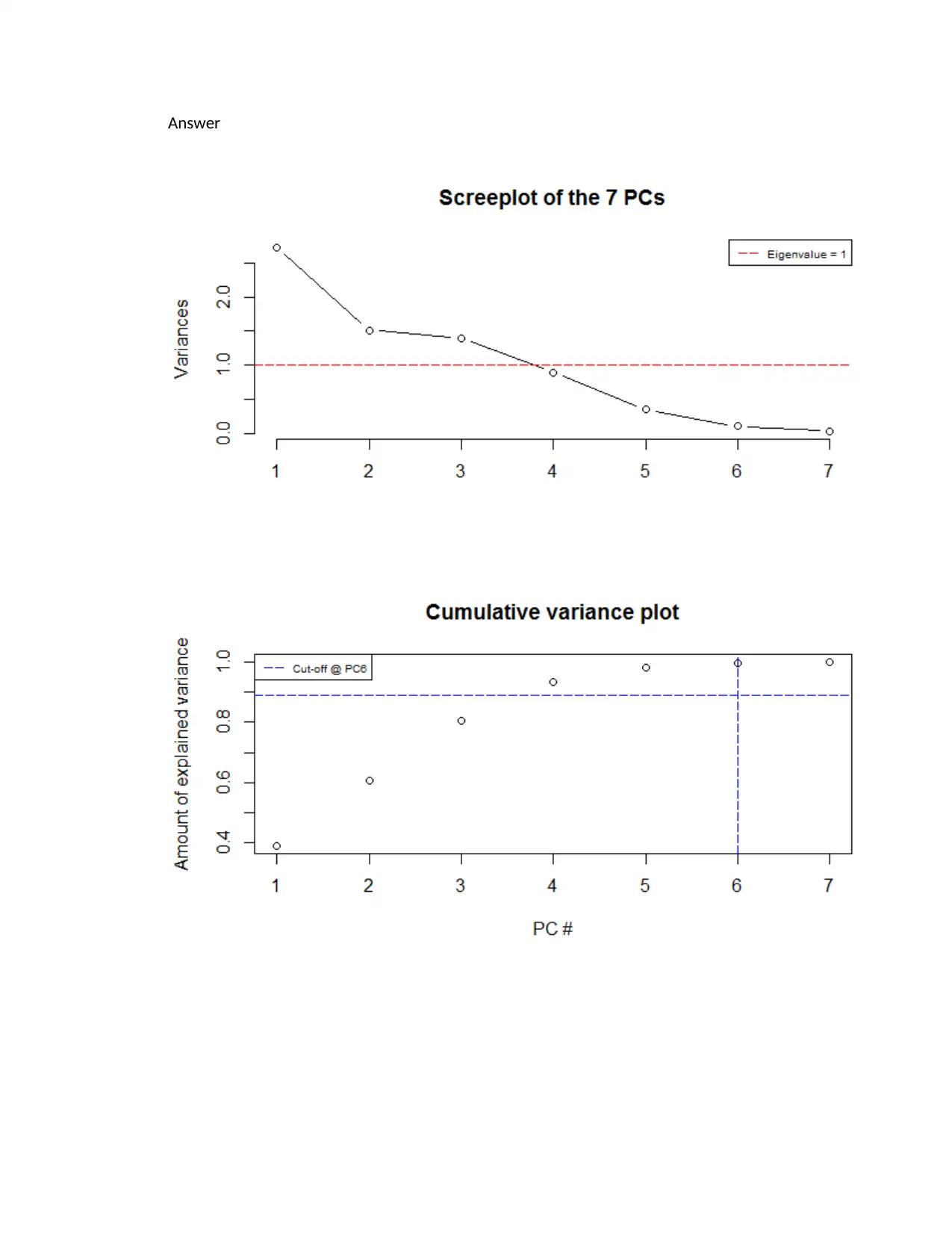
This homework assignment provides a comprehensive analysis of two datasets using various statistical techniques. The first question focuses on assessing the normality of film thickness variables using QQ plots, histograms, and Shapiro-Wilk tests, followed by multivariate normality tests (Mardia, Henze-Zirkler, and Royston tests) and discussions on improving normality. The second question involves analyzing flower characteristics using MANOVA, including a draftsman display, correlation matrix interpretation, and Hotelling's T2 tests for group comparisons. The third question delves into PCA, covering the correlation and covariance matrices, eigenvalue analysis, scree plots, and their impact on determining the number of principal components to interpret. The assignment emphasizes the interpretation of statistical outputs and the practical application of these techniques in data analysis.






1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.