STAT1060 Assignment 2: Using Statistical Analysis for Decisions
VerifiedAdded on 2023/06/07
|11
|1469
|492
Homework Assignment
AI Summary
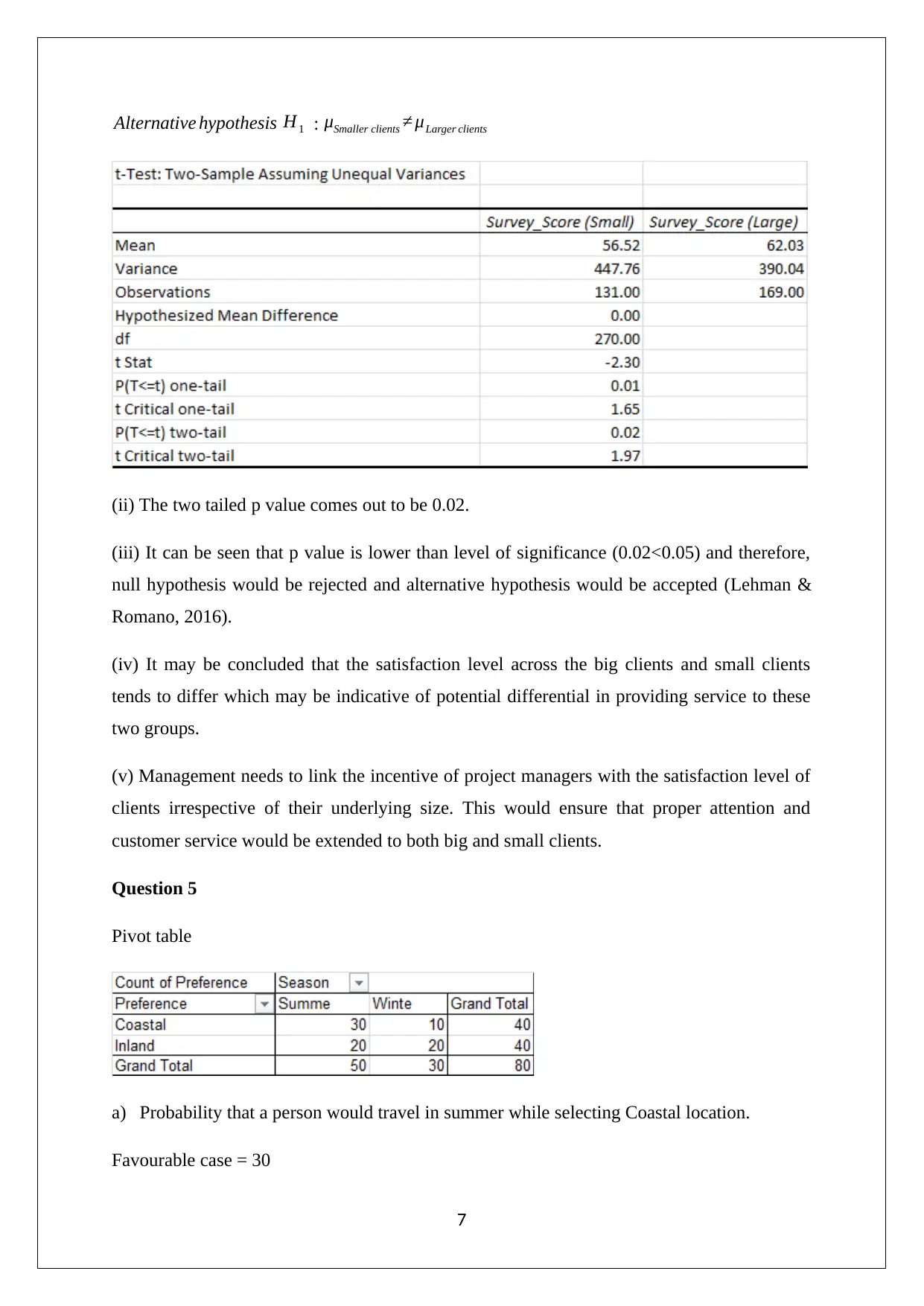
This assignment solution focuses on applying statistical analysis to support decision-making, covering topics from data types and graphical representations to hypothesis testing. It addresses questions related to identifying variable types, creating appropriate graphs (like bar charts and histograms), and interpreting statistical results. The solution includes analysis of lost-time injury causes, weight distribution of ball packets, and client satisfaction survey scores. Hypothesis testing is performed to determine if the average satisfaction score differs from a hypothesized value and whether there's a difference in satisfaction levels between large and small clients. The assignment also explores the association between travel season and preferred location using pivot tables and chi-square tests. The final recommendation emphasizes the importance of aligning project manager incentives with client satisfaction levels, irrespective of client size. Desklib offers a wealth of similar solved assignments and past papers for students.






1 out of 11
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.