Statistical Analysis Homework: Problem Set #1 - University Name
VerifiedAdded on 2022/08/09
|9
|1385
|180
Homework Assignment
AI Summary
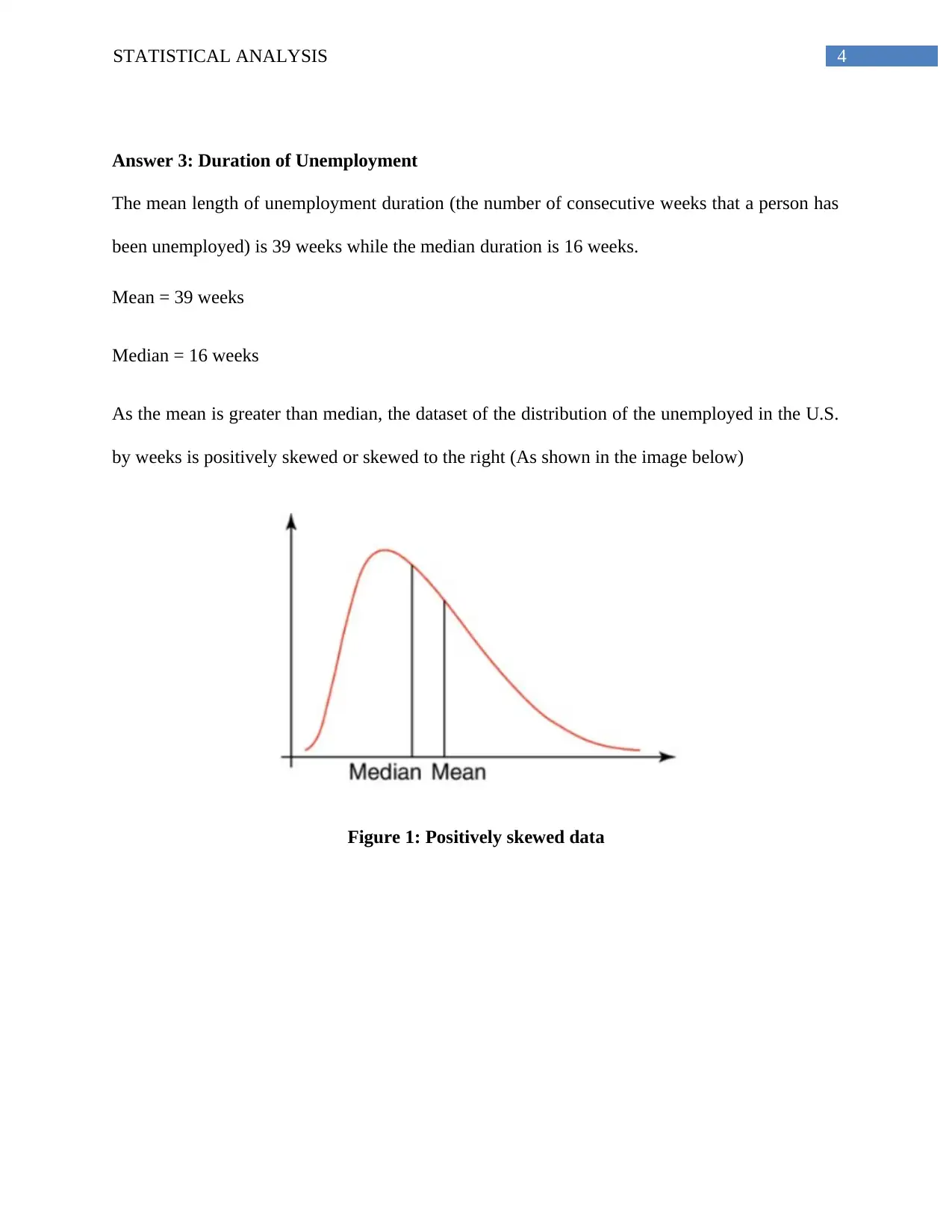
This document presents a comprehensive solution to a statistical analysis homework assignment. The assignment covers various statistical concepts, including hypothesis testing for the impact of red wine on heart disease, analysis of poll data on Brexit, interpretation of unemployment duration statistics (mean and median), calculations involving food expenditure, GRE score analysis, and probability calculations related to weather forecasting. The solution provides detailed explanations, calculations, and interpretations for each problem, demonstrating a strong understanding of statistical principles and their application to real-world scenarios. The document effectively addresses sampling errors, confounding variables, and external validity, providing a well-rounded analysis of the statistical concepts presented in the assignment. The solution also includes examples of positively skewed data and normal distribution.








1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.