Public Health: Statistical Analysis of Healthy Lifestyle Data Report
VerifiedAdded on 2022/12/23
|21
|4018
|78
Report
AI Summary
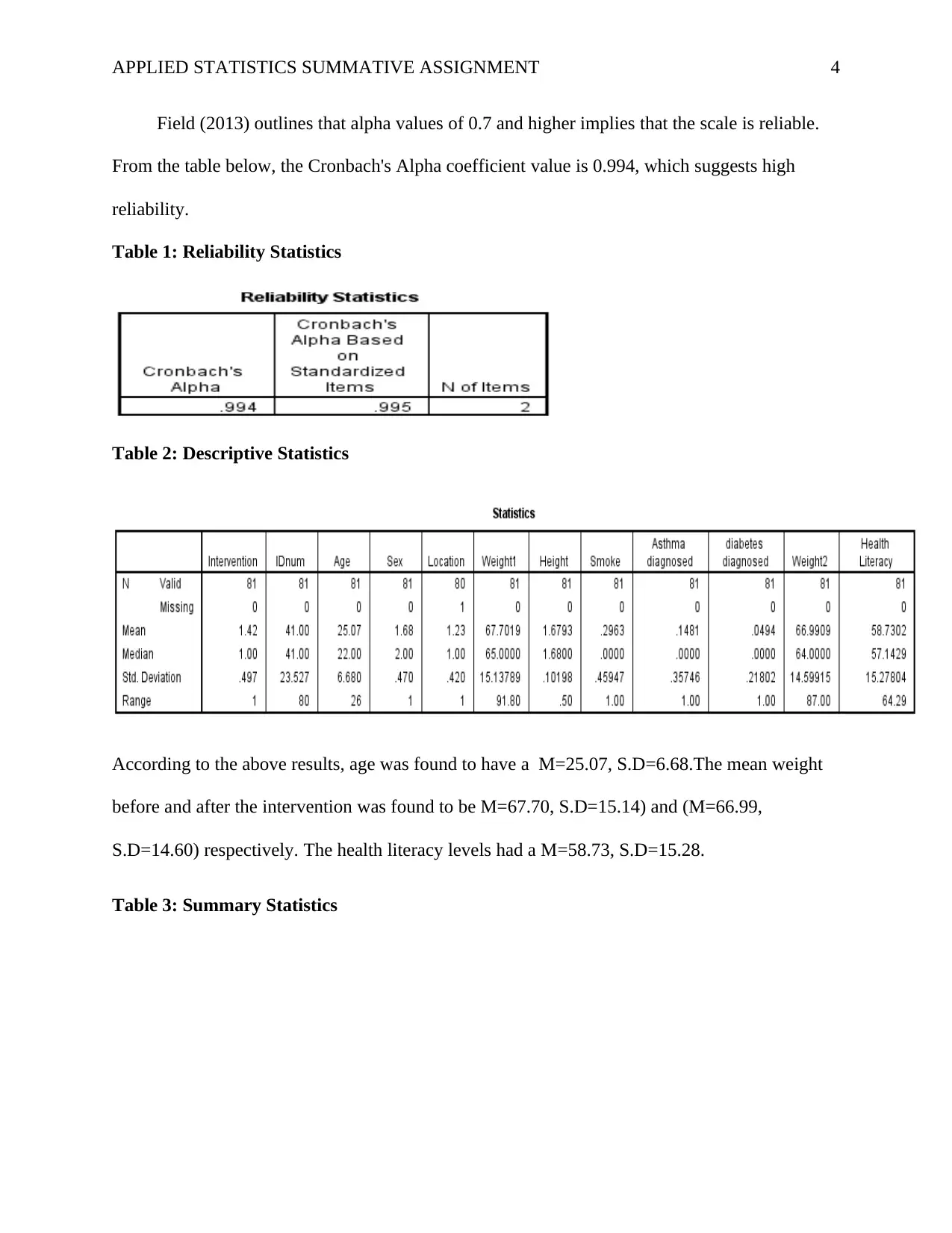
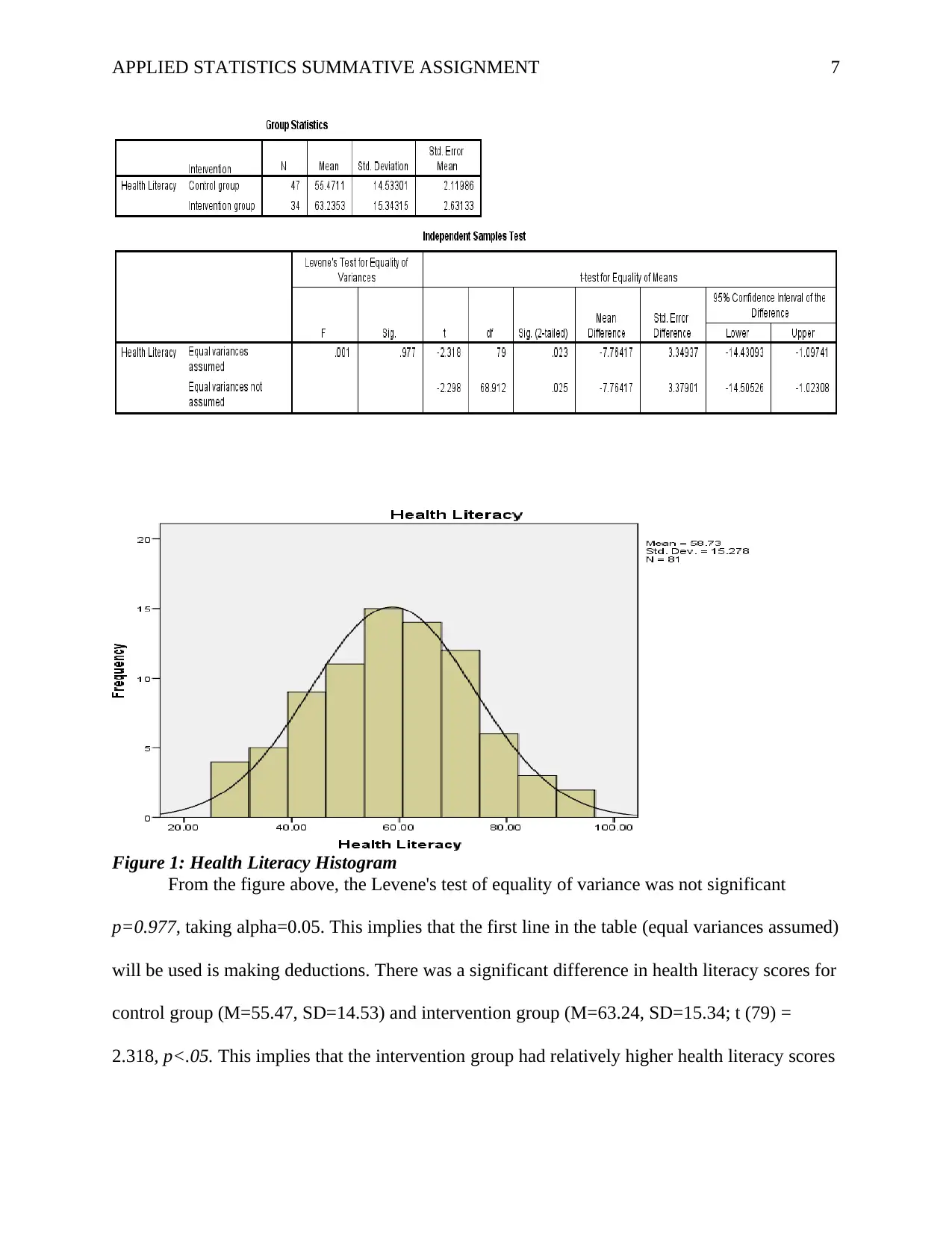
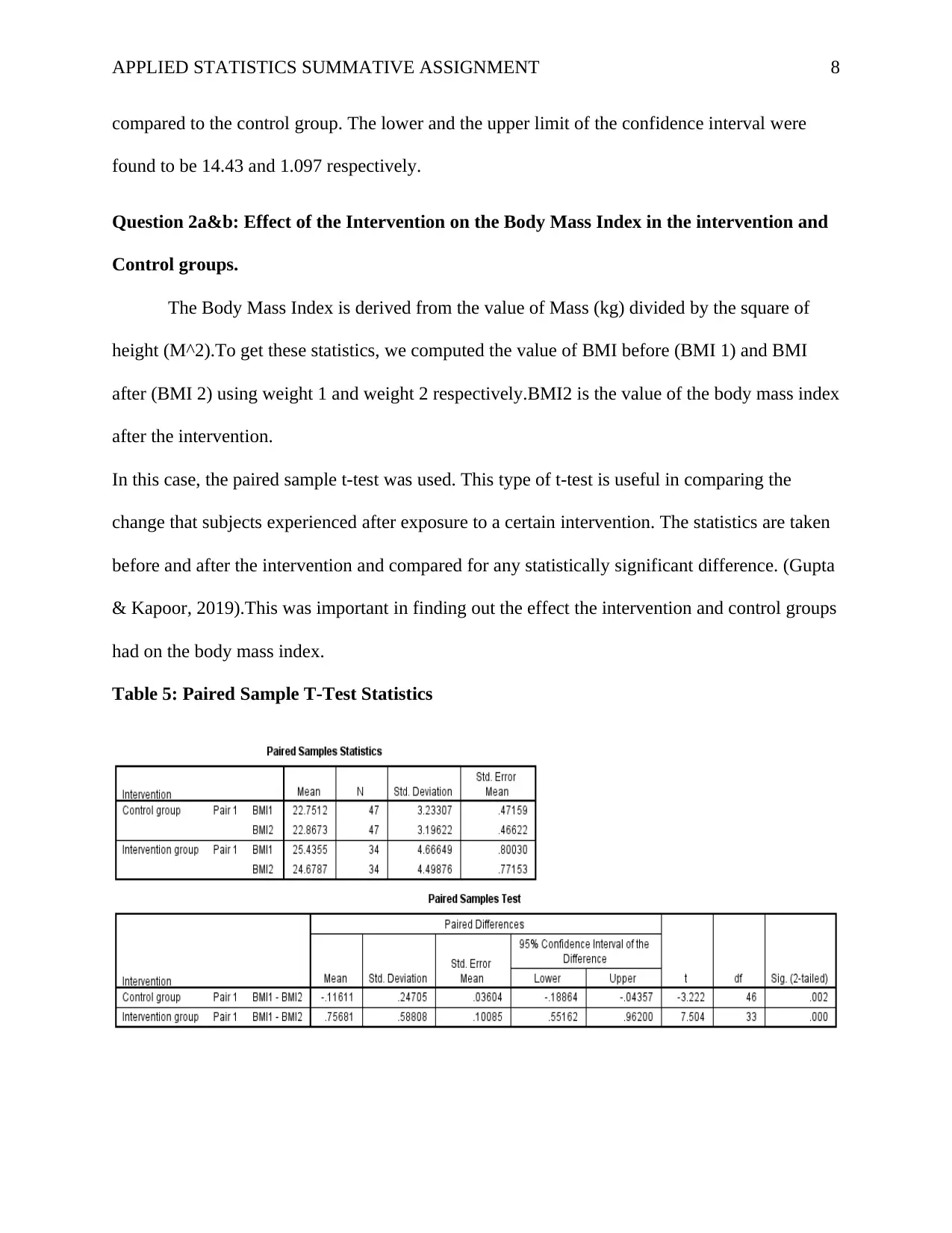
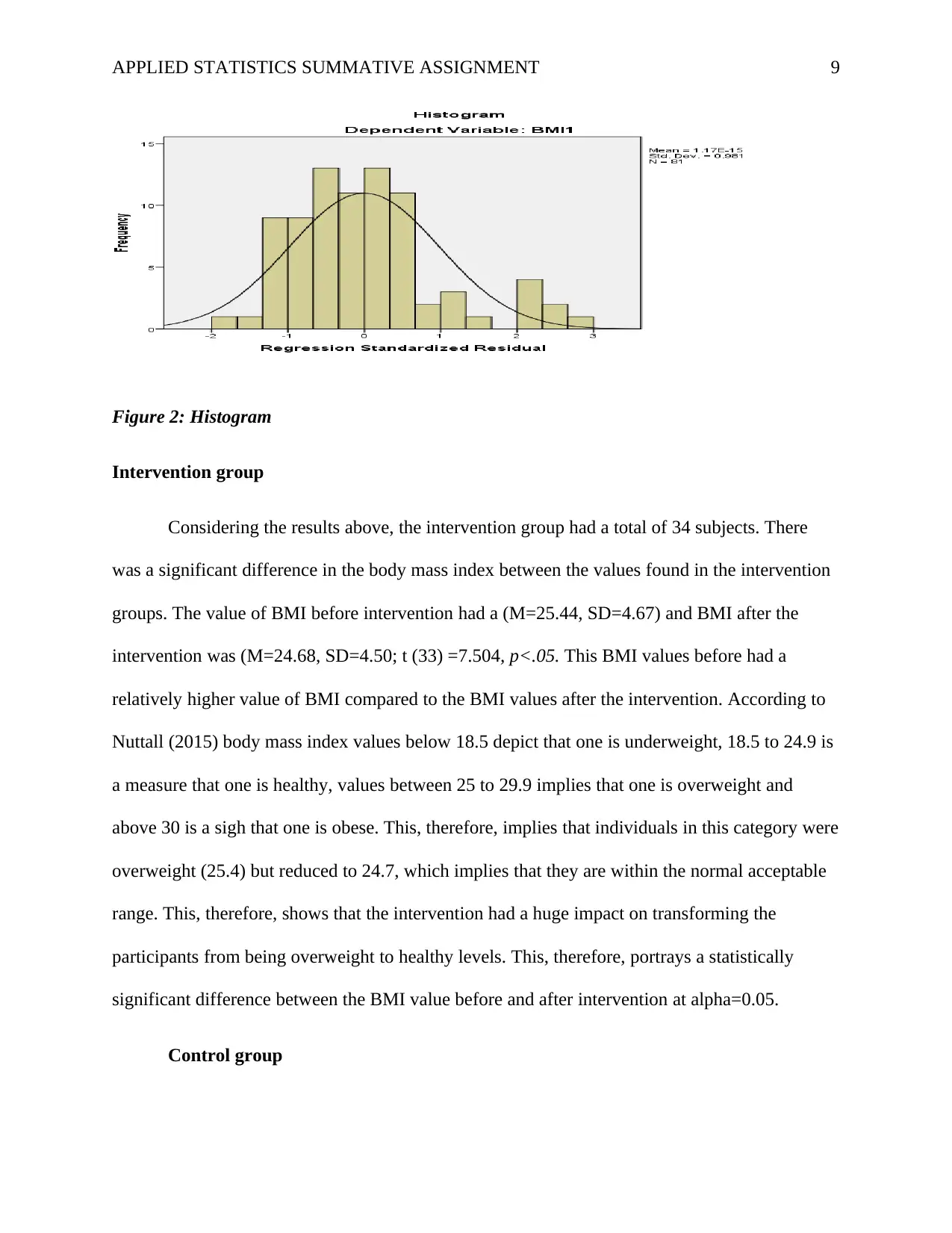
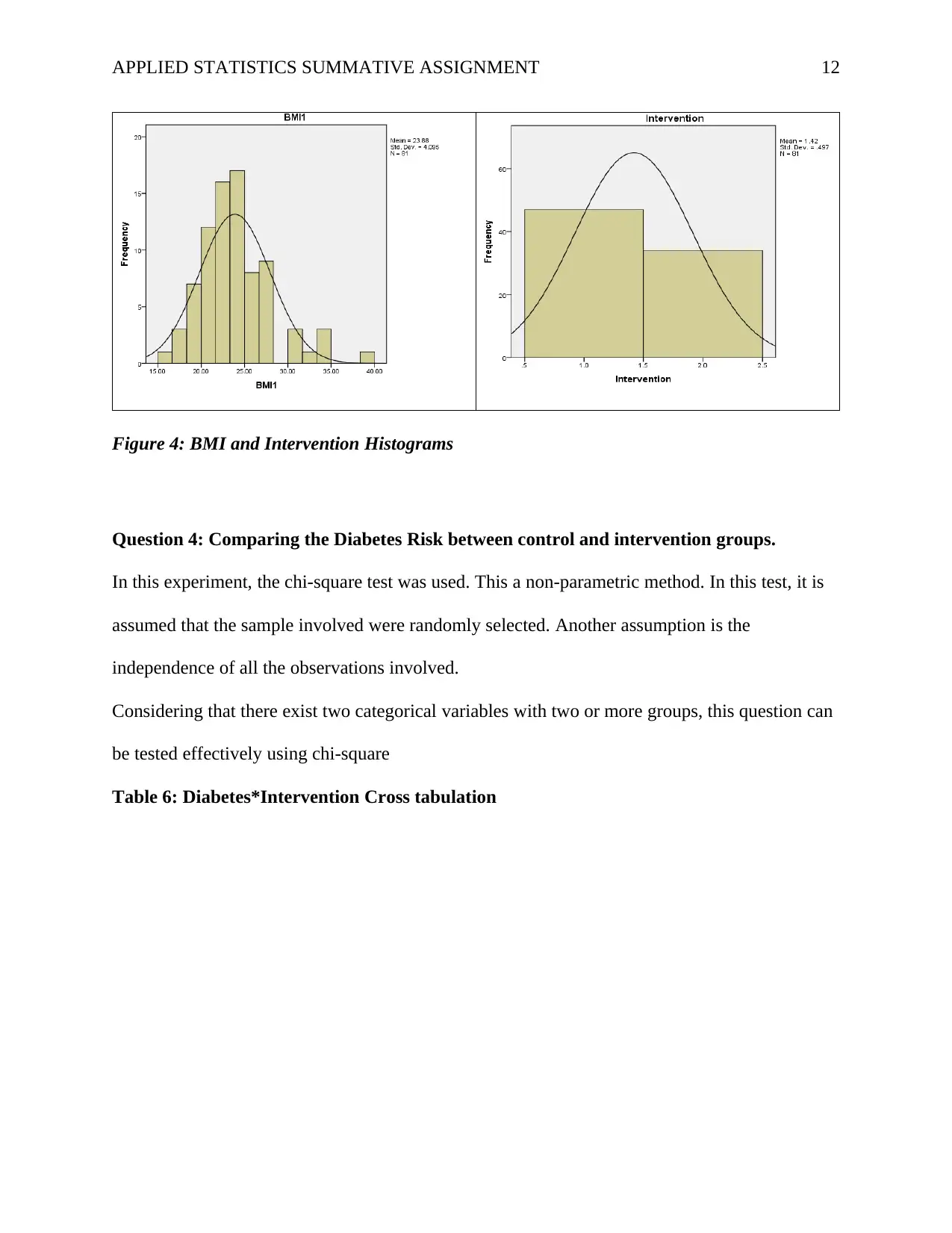
This report presents a statistical analysis of a healthy lifestyle intervention aimed at university students, focusing on improving health literacy and reducing weight. The study involved 81 participants, divided into intervention and control groups, with data collected on age, gender, height, smoking status, health literacy, and health conditions. The analysis employed both descriptive and inferential statistics, using SPSS software. Reliability was assessed using Cronbach's Alpha, demonstrating high internal consistency. Key findings include significant differences in health literacy between the intervention and control groups, with the intervention group showing higher scores. Additionally, the intervention group exhibited a significant reduction in BMI, indicating a positive impact on weight management. The report also explores the effects of the intervention on BMI compared to the control group, as well as the diabetes risk between the two groups, utilizing t-tests, Mann-Whitney U Test and Chi-square tests. Finally, the report investigates the predictive power of health literacy, age, and sex on changes in BMI. The report provides detailed statistical results, including tables and figures, to support the conclusions drawn regarding the effectiveness of the intervention.







1 out of 21
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.