STM4PSD: Assignment 4 - Statistical Analysis and Interpretation
VerifiedAdded on 2022/10/02
|8
|2130
|172
Homework Assignment
AI Summary
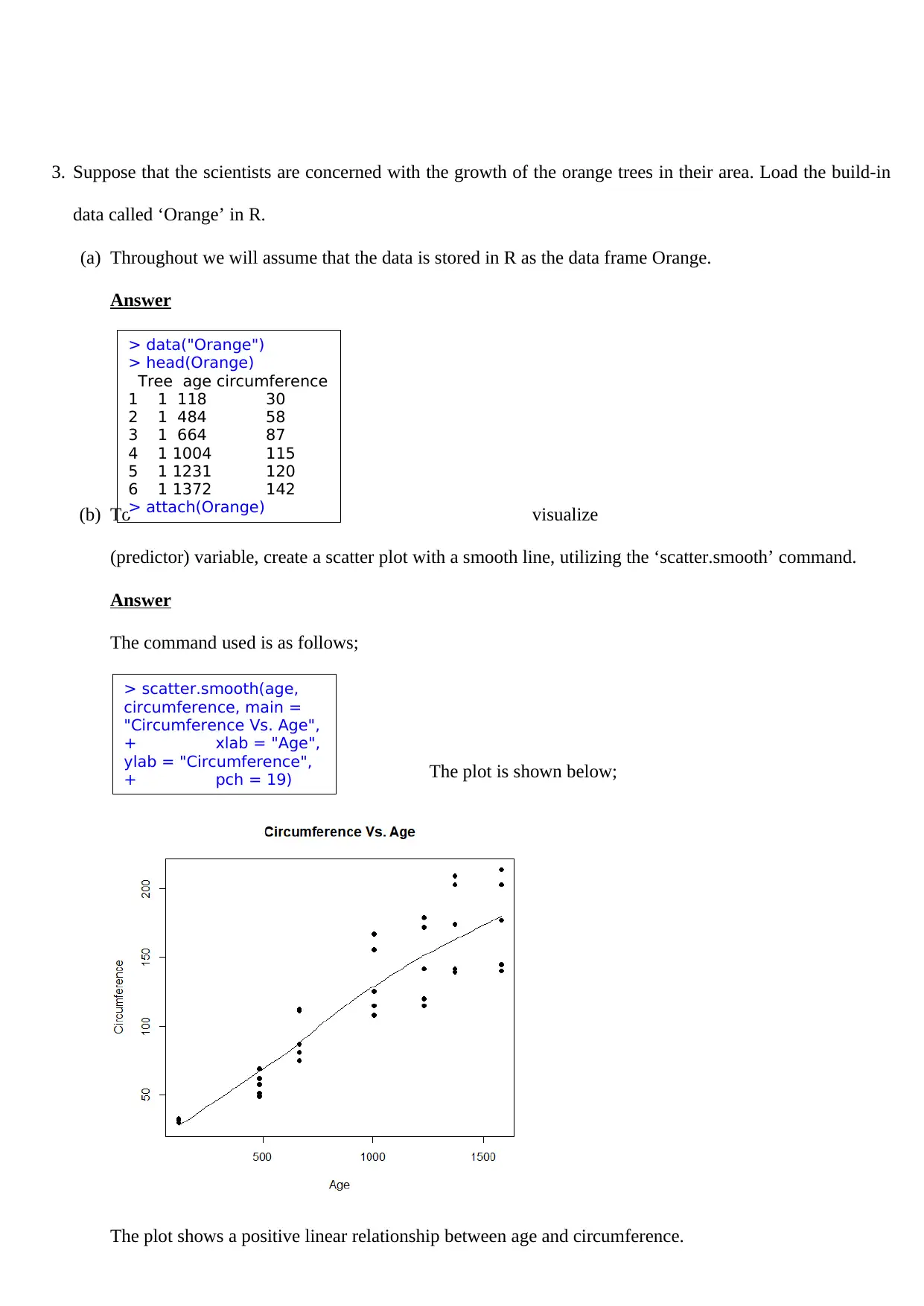
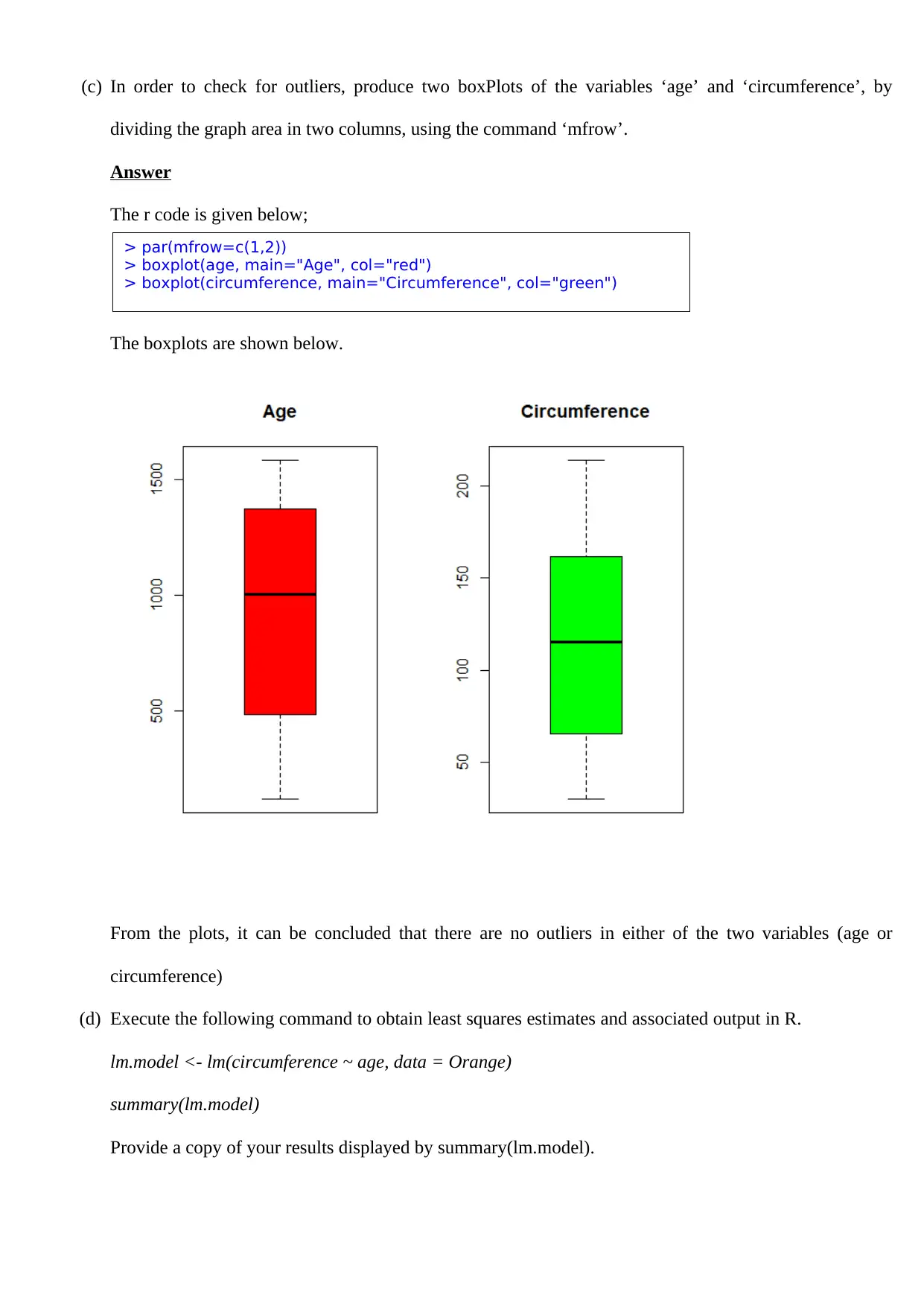
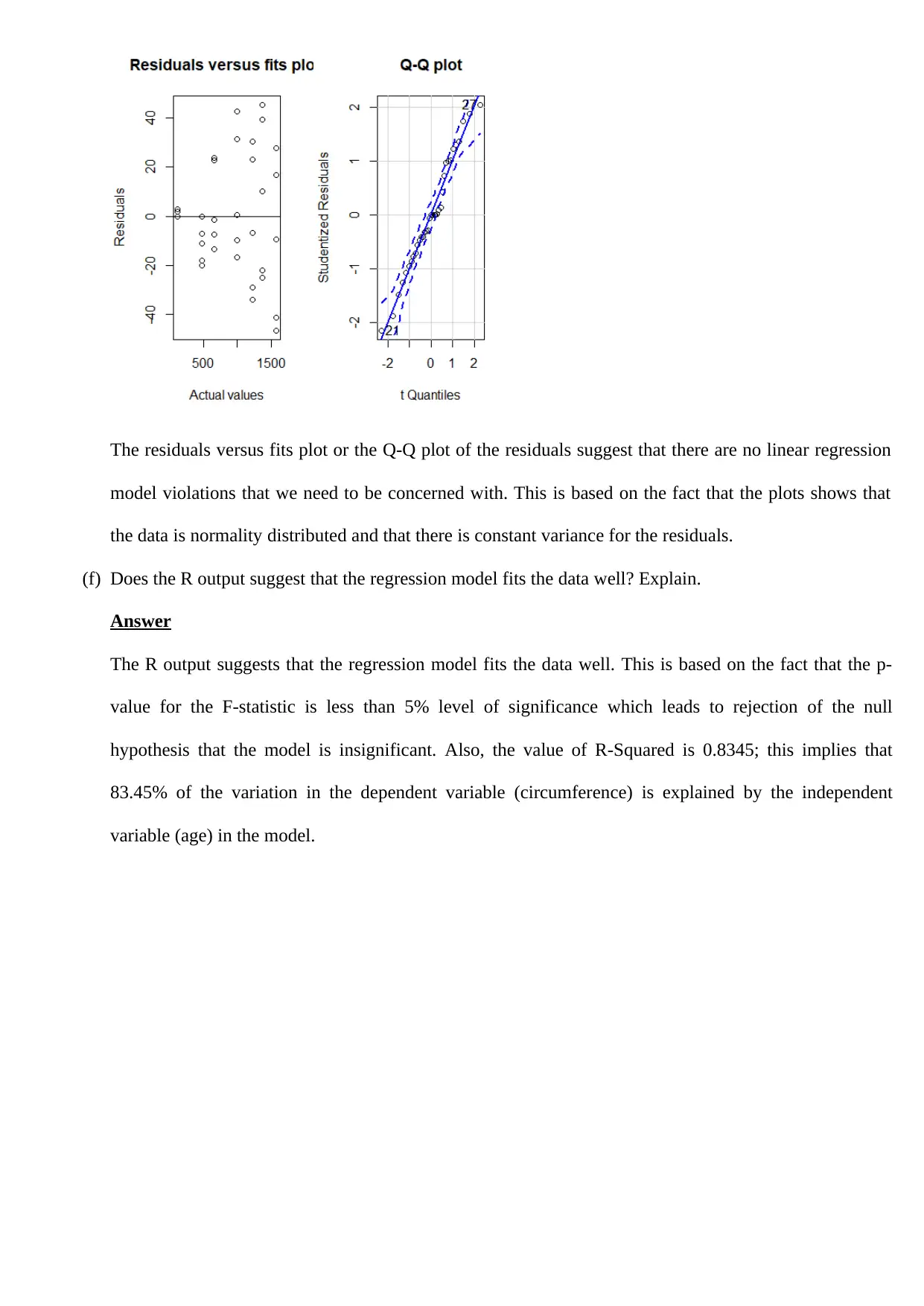
This assignment solution for STM4PSD Assignment 4 addresses several statistical problems. It begins by calculating a 95% confidence interval for the mean service time of a photocopier company's technicians, testing the company's claim. The solution then performs a hypothesis test to compare the proportions of jobs failing to meet quality standards between two concreting companies, utilizing the R function prop.test and interpreting the results. Finally, the assignment analyzes the 'Orange' dataset in R, creating scatter plots, boxplots, and performing linear regression to model the relationship between the age and circumference of orange trees, including residual analysis and interpretation of the regression model's fit. The document includes R code, outputs, and interpretations for all analyses, providing a comprehensive solution to the assignment's requirements.





1 out of 8
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.