Statistics Report: Statistical Data Analysis and Interpretation
VerifiedAdded on 2020/03/23
|8
|1296
|53
Report
AI Summary
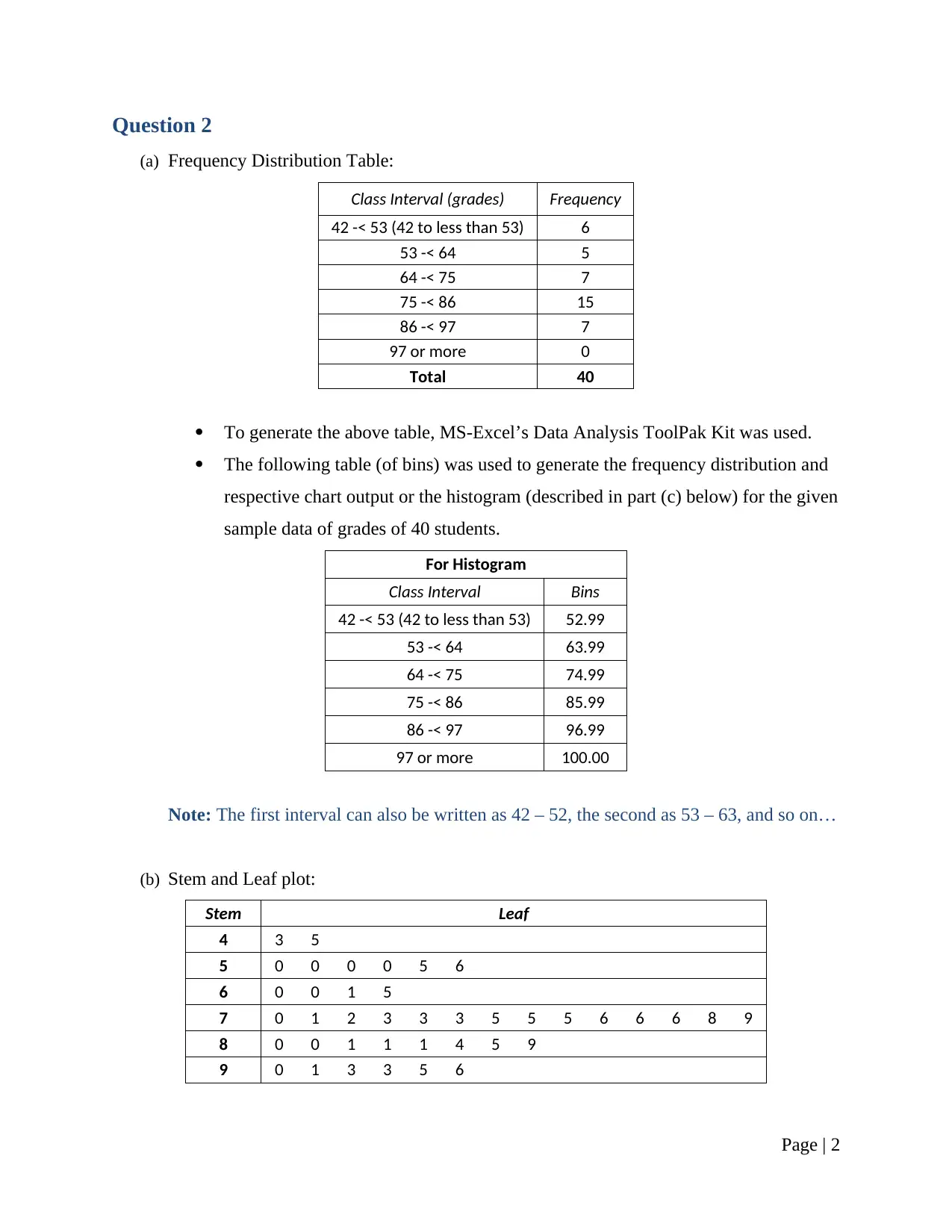
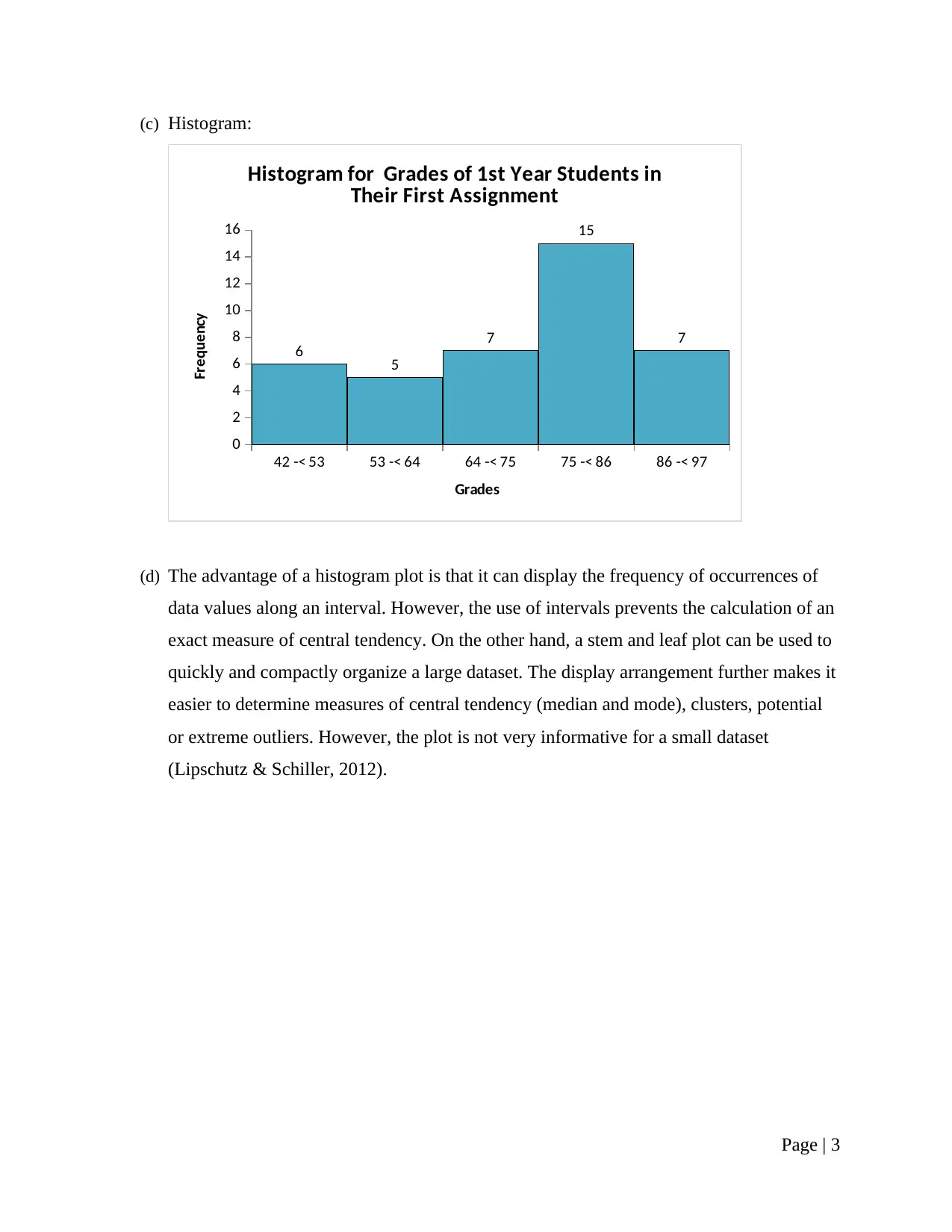
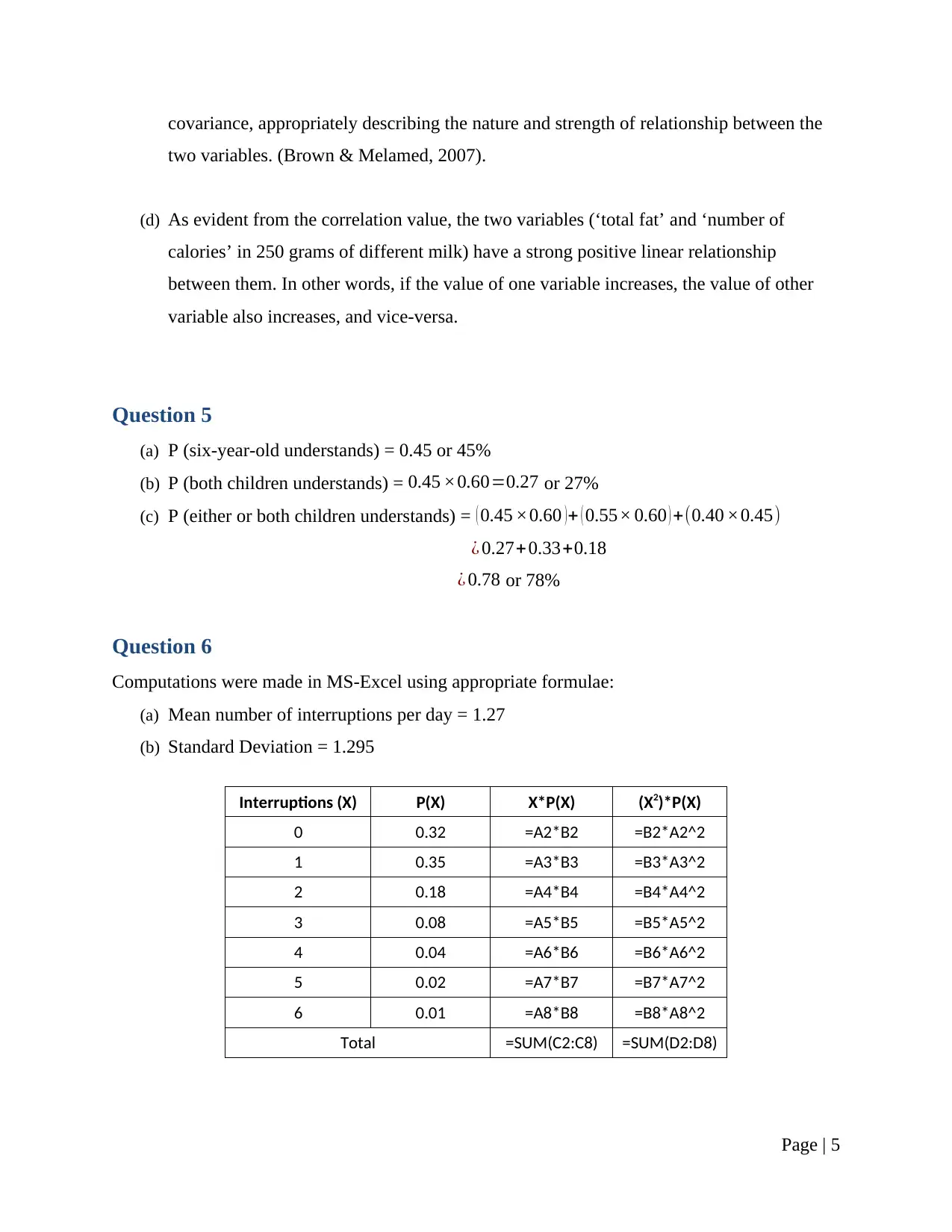
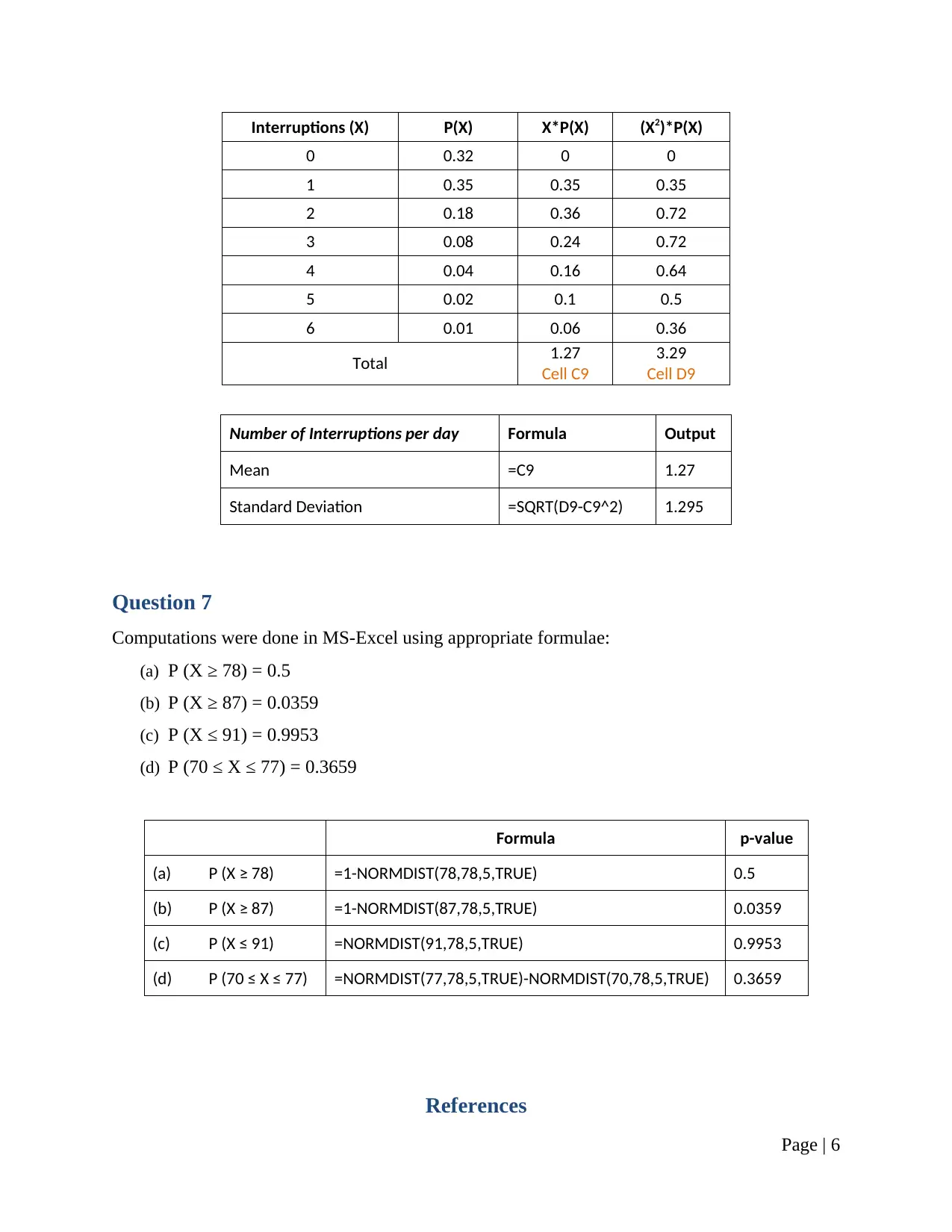
This research report presents a comprehensive analysis of statistical concepts and methods, addressing various aspects of data analysis and interpretation. The report begins with a discussion on sampling techniques, specifically stratified simple random sampling, and considerations for survey design. It then delves into frequency distributions, using MS-Excel to create tables and histograms. Stem and leaf plots are also utilized for data visualization, highlighting their advantages and limitations. The report proceeds to calculate and interpret measures of central tendency, including mean, mode, and standard deviation, using provided sample data. Correlation and covariance are computed to express the relationship between variables, with an emphasis on the interpretation of the correlation statistic. Probability calculations are performed, addressing scenarios involving conditional probabilities. Finally, the report explores probability distributions, computing probabilities using the normal distribution. The analysis is supported by MS-Excel computations and relevant statistical formulas, providing a practical demonstration of statistical principles. The report concludes with a list of cited references.




1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.