Statistical Methods in Engineering Homework - University, 2018
VerifiedAdded on 2020/05/28
|8
|1027
|277
Homework Assignment
AI Summary
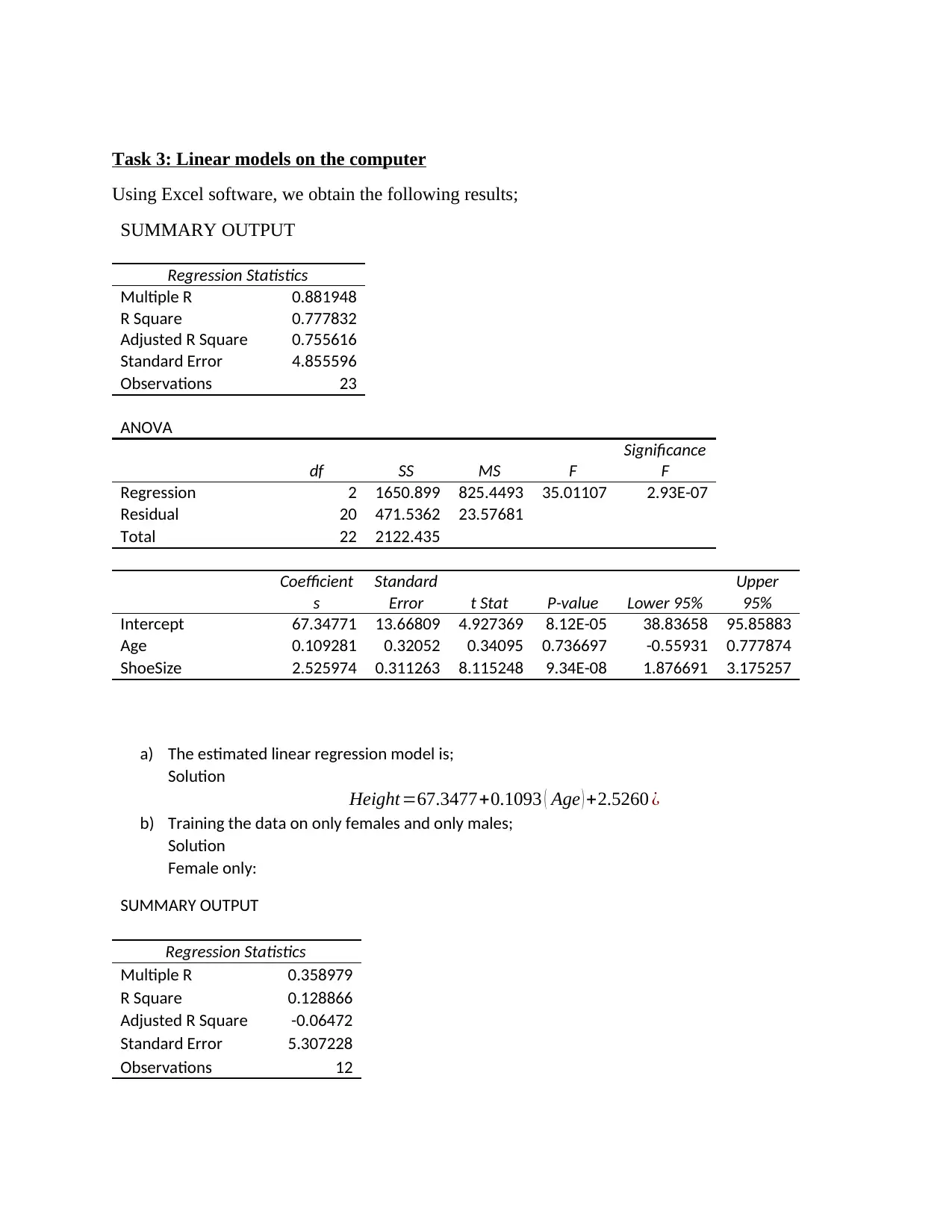
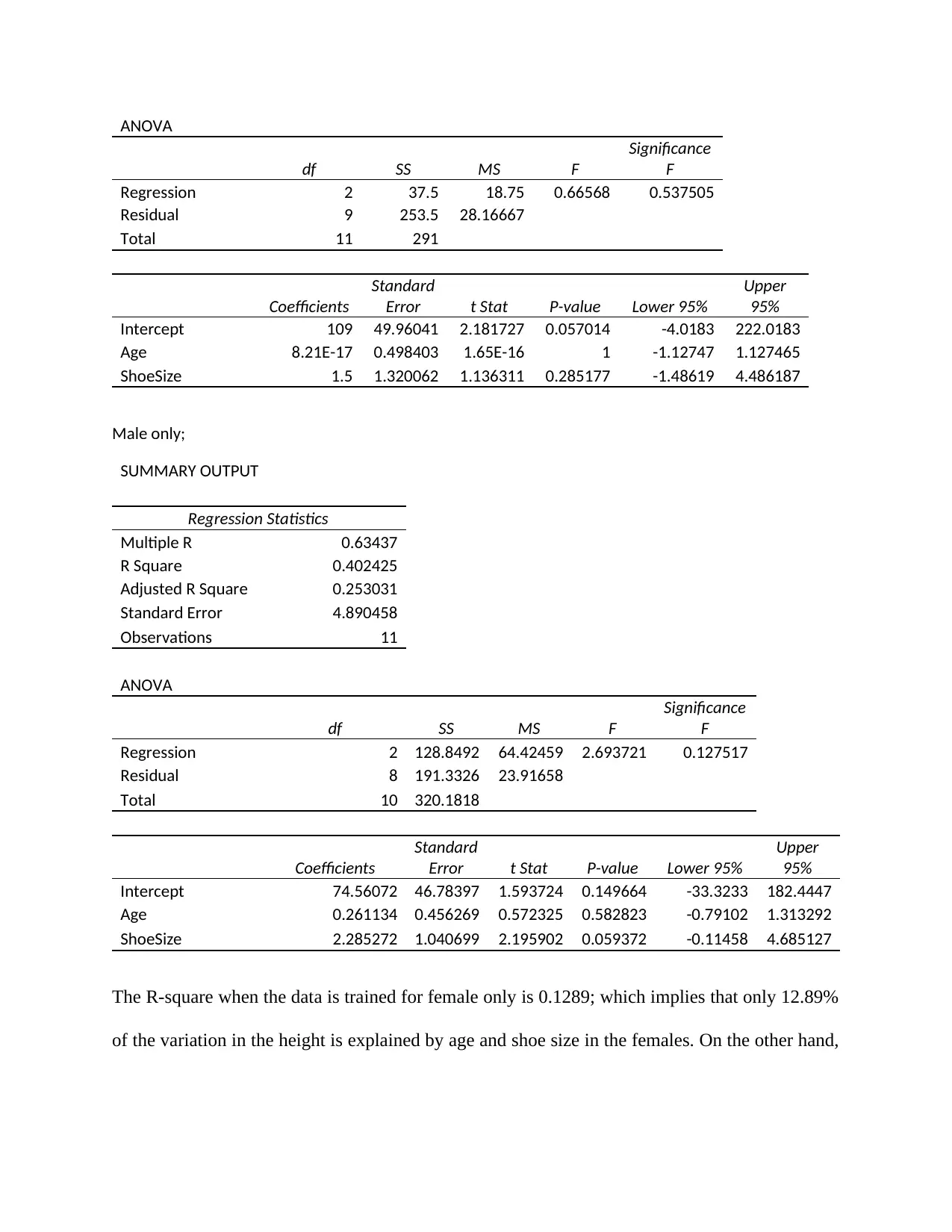
This document presents a comprehensive solution to a statistical methods in engineering assignment. It begins with an explanation of the Gram-Schmidt process for orthogonalization. The assignment then delves into linear models, including finding the equation of a least-squares line and analyzing data using Excel. The Excel portion includes regression statistics, ANOVA tables, and the development of estimated linear regression models, with separate analyses for male and female data. The document also explores Pearson correlation. Finally, the assignment addresses fitting a linear model to a curve using R, including interpreting regression output and estimating the velocity of a plane using derivatives. The solution provides detailed steps and interpretations for each task, offering a complete understanding of the statistical concepts involved.






1 out of 8
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.