Statistical Hydrology Project: Bridge Design and Flood Analysis Report
VerifiedAdded on 2022/09/28
|21
|3516
|23
Project
AI Summary
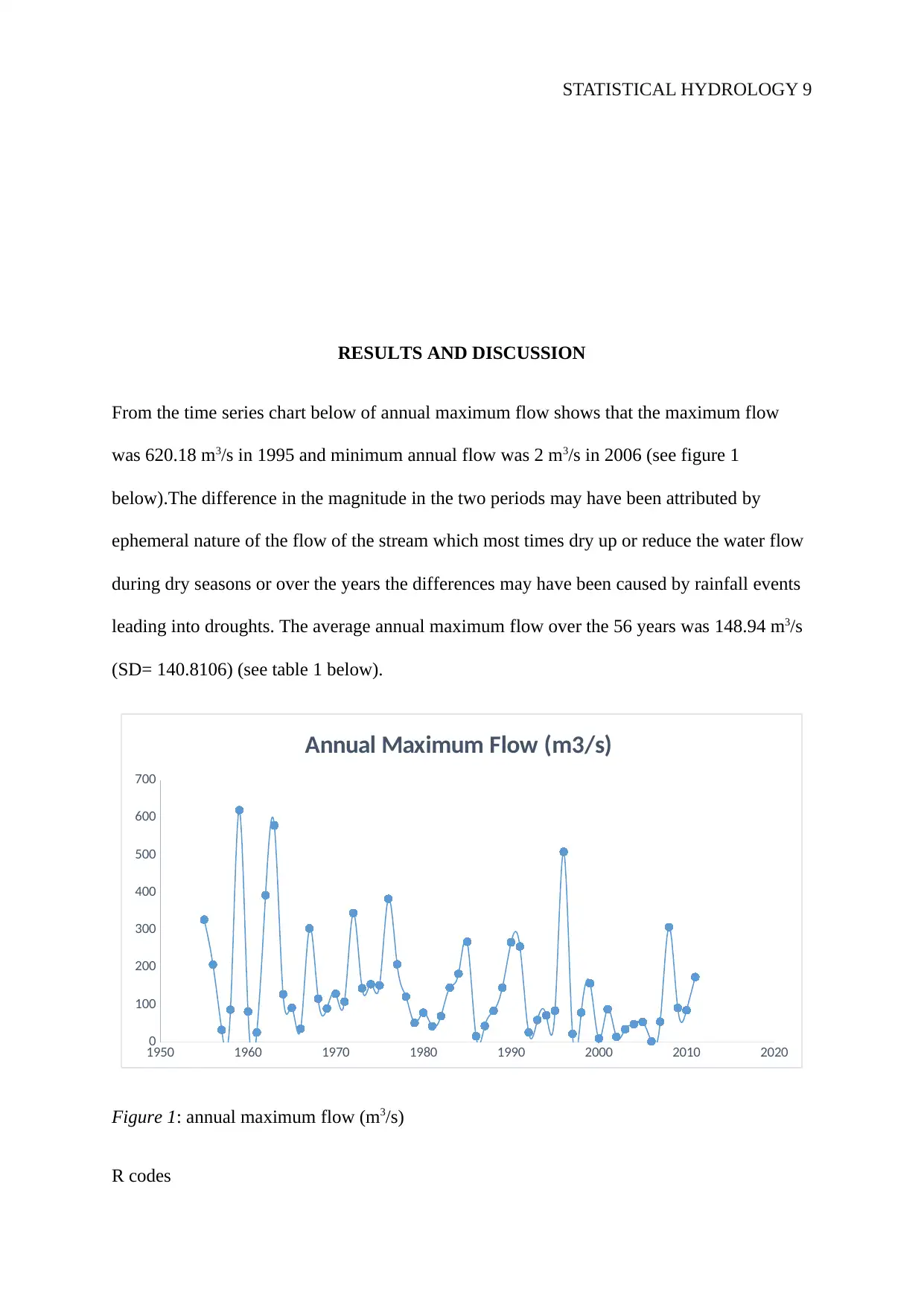
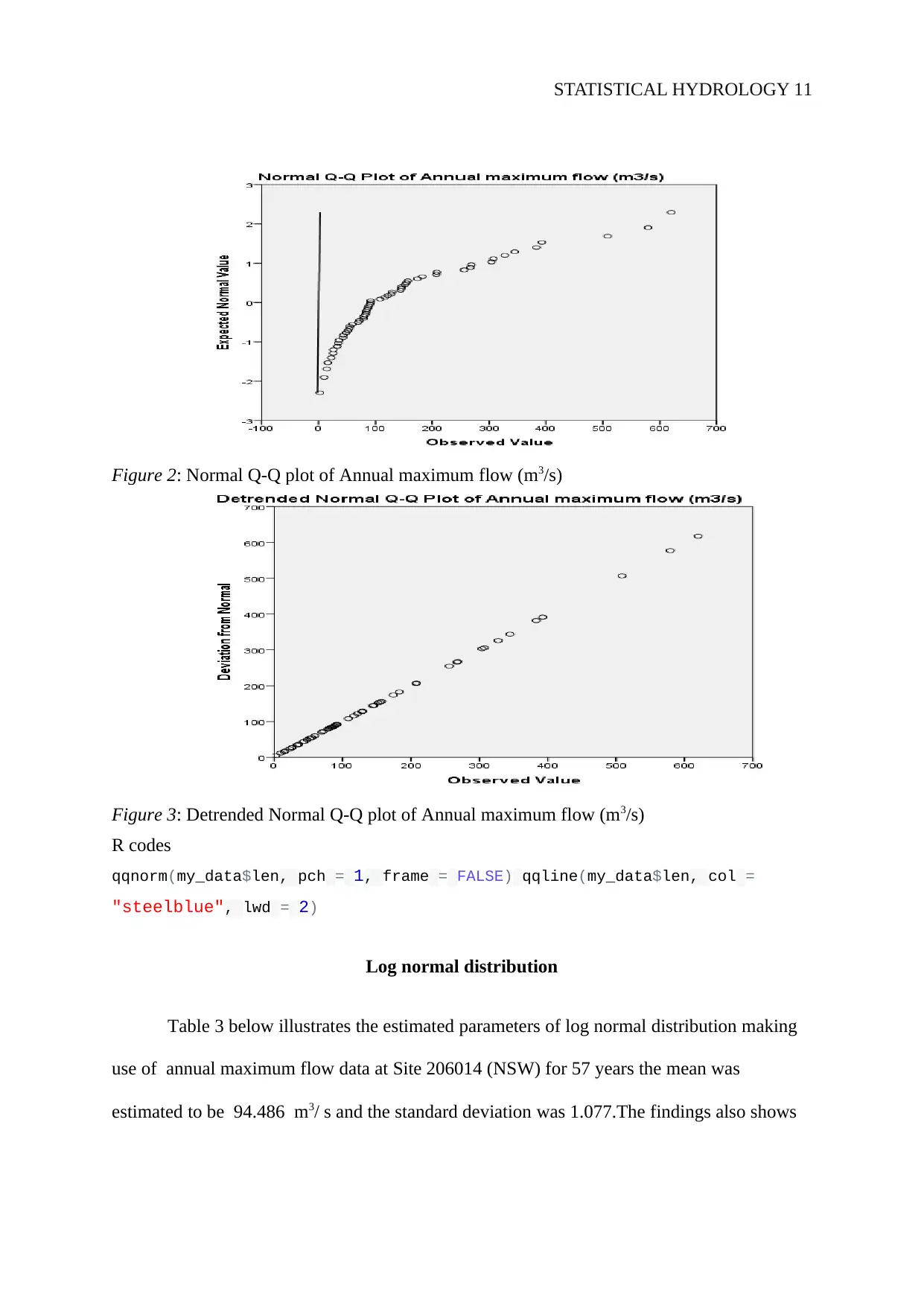
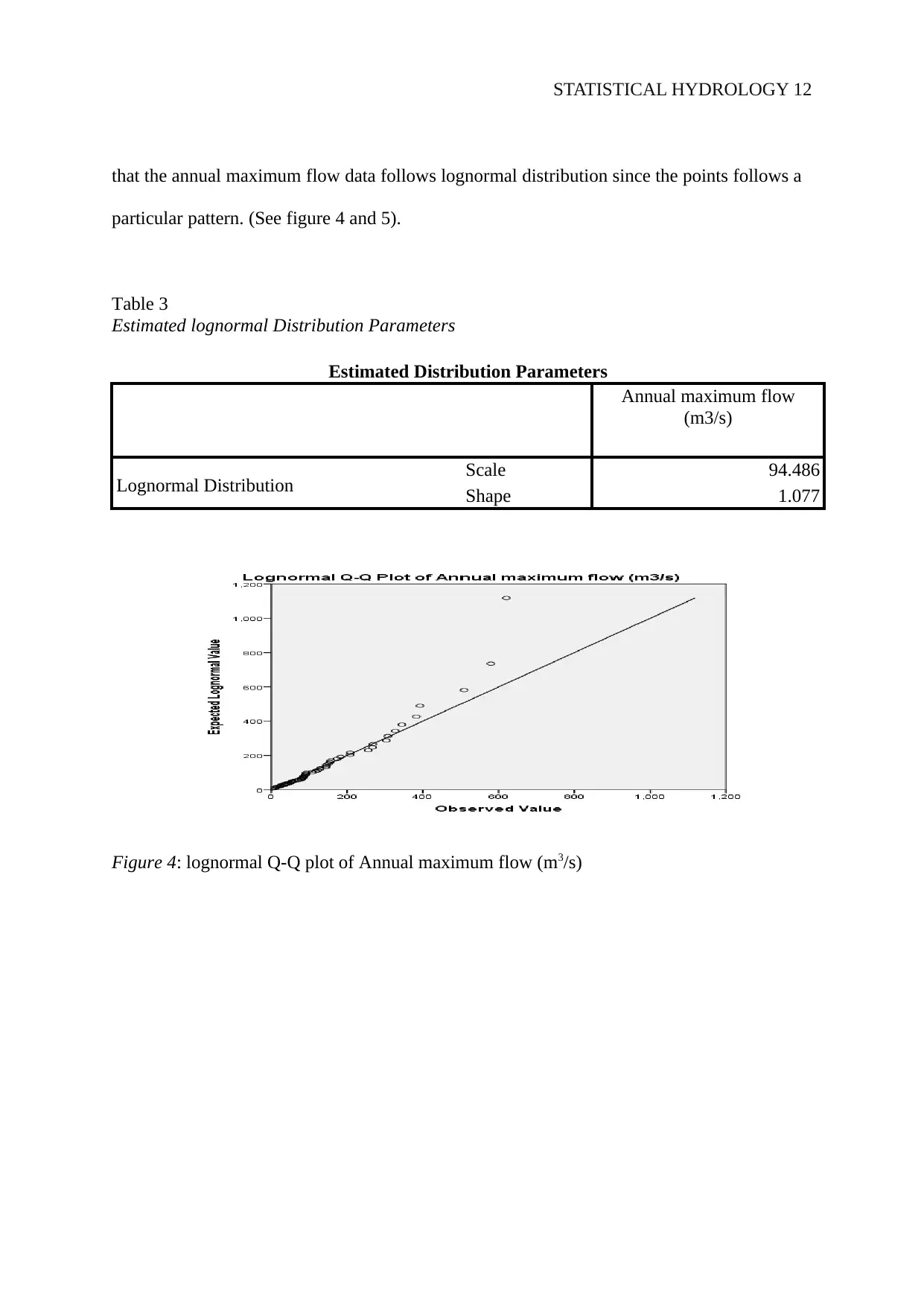
This project is a comprehensive statistical hydrology analysis focused on determining a suitable flood discharge for the design of a bridge upstream of the Wollomombi River in NSW, Australia. The study utilizes annual maximum flow data from Station 206014, spanning from 1955 to 2011, to estimate the Q50 and recommend a Q100 flood discharge. The methodology involves fitting Normal, Log Normal, Gumbel (EV1), and Gamma distributions to the data, followed by a comparison of the estimated flood quantiles using a non-parametric flood frequency analysis. The report includes a literature review of relevant studies, detailed methodologies for each distribution, and results presented through charts and tables, including QQ plots. The findings indicate that the data follows both normal and lognormal distributions. The project concludes with a recommendation for a suitable flood discharge for bridge design, acknowledging limitations and suggesting areas for future improvement.








1 out of 21
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.