Applied Statistical Methods: Data Analysis and Interpretation
VerifiedAdded on 2022/09/26
|9
|714
|19
Homework Assignment
AI Summary
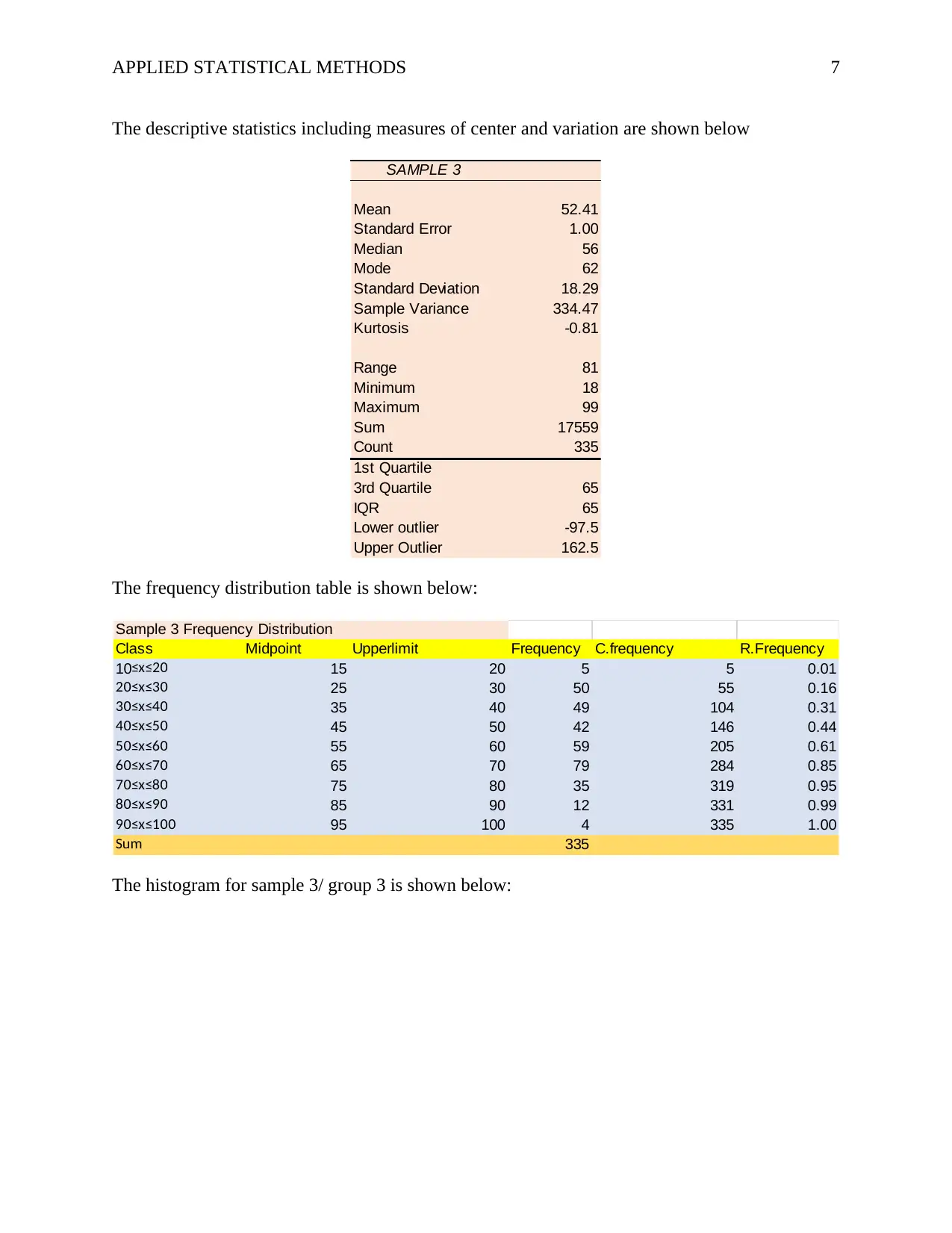
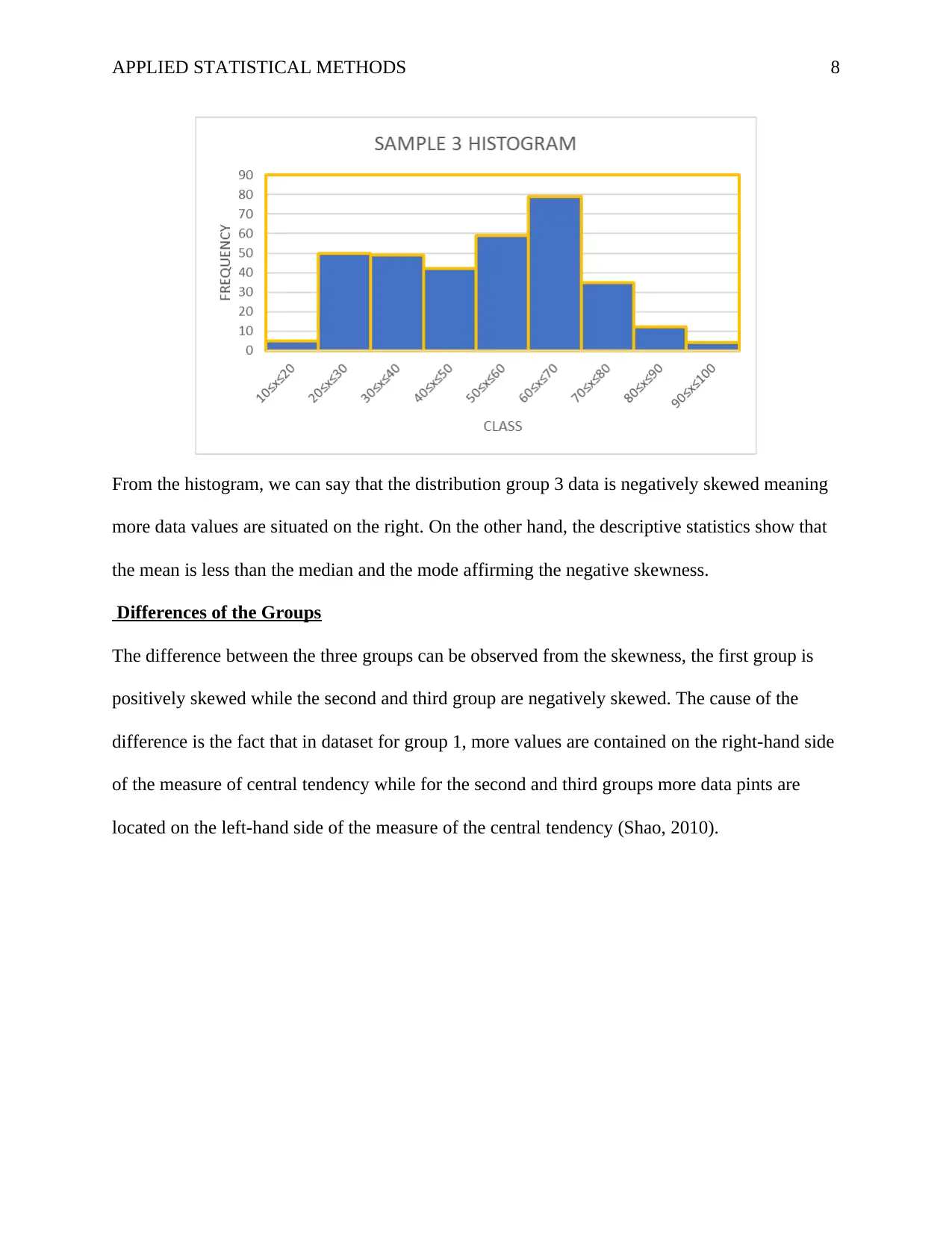
This assignment focuses on applied statistical methods, utilizing a provided dataset to analyze a continuous quantitative variable, "z7". The solution develops descriptive statistics, frequency tables, and histograms for the entire dataset and for three subgroups created by dividing the data. The analysis includes measures of central tendency (mean, median, mode), variation (standard deviation, variance), and skewness. The assignment identifies the shape of the distribution for each group, contrasts the groups based on their statistical properties and visual representations (histograms), and explains the causes of the observed differences in skewness, referencing the position of data values relative to measures of central tendency. The document also includes an introduction, results, and references to support the analysis.



1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.