BUS708 Statistical Modelling Assignment: NSW Transport System Analysis
VerifiedAdded on 2023/06/04
|8
|1811
|170
Report
AI Summary
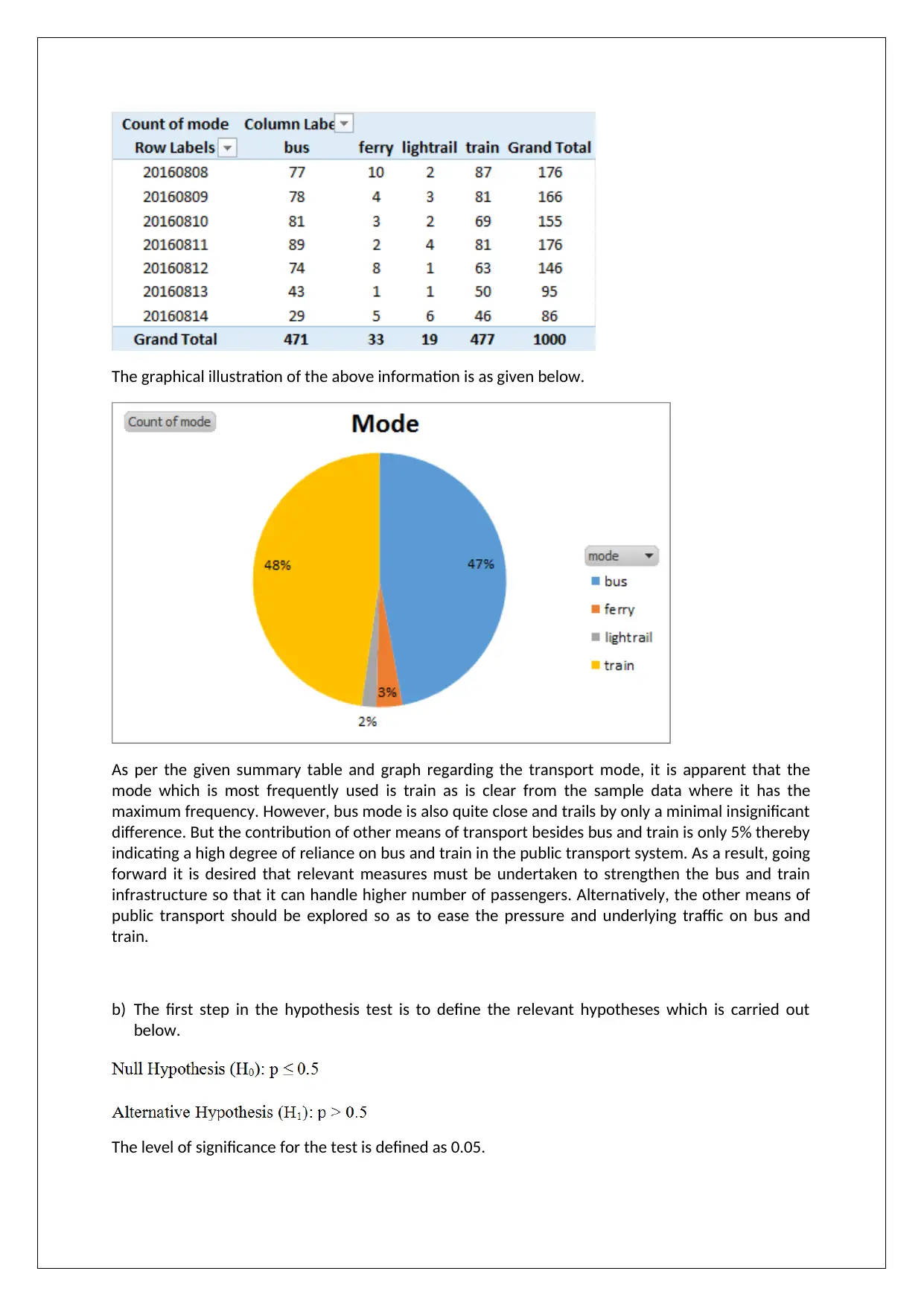
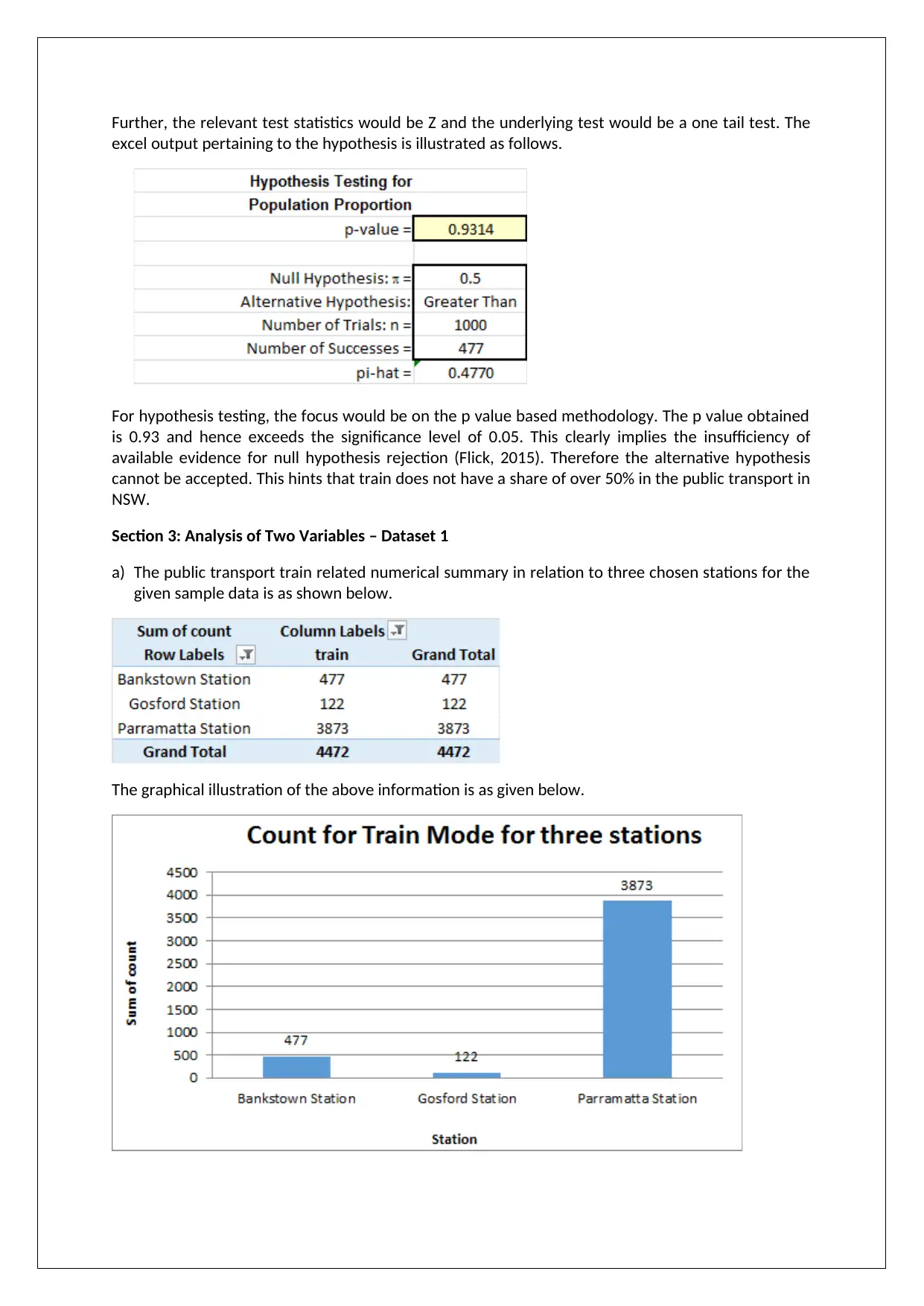
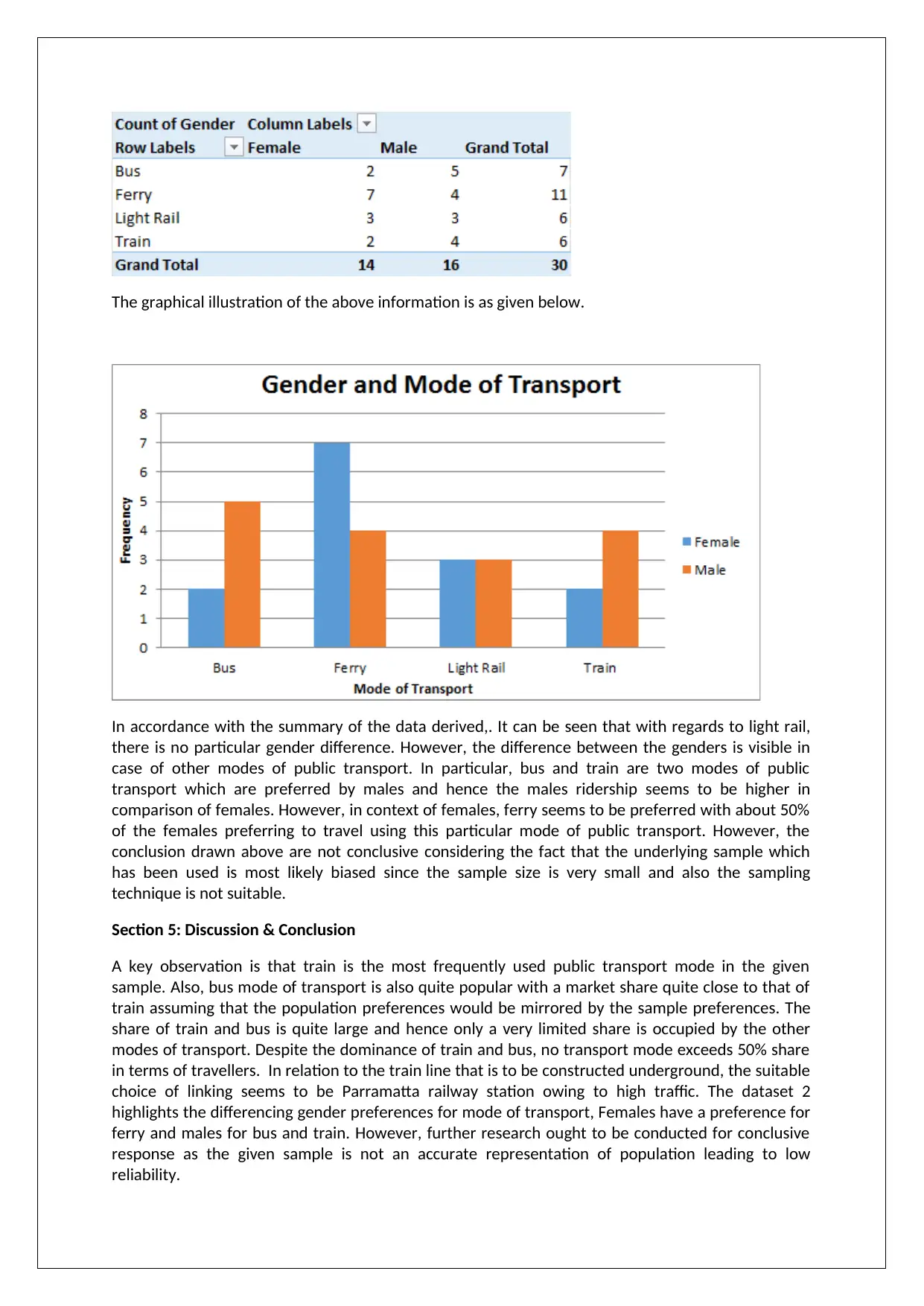
This report presents a comprehensive analysis of the NSW transport system using statistical modeling techniques, based on the BUS708 assignment. The report begins with an introduction, providing context and defining the datasets used: Dataset 1 (secondary data) and Dataset 2 (primary data). It then proceeds to analyze single variables within Dataset 1, focusing on the usage of different public transport modes, and performs hypothesis testing to determine the share of train usage. The analysis extends to two variables in Dataset 1, examining the relationship between train usage and different stations, also including hypothesis testing. Finally, the report analyzes Dataset 2, focusing on gender preferences for different transport modes, and concludes with a discussion of findings, limitations, and recommendations for future research, including the suggestion of connecting Parramatta station to the proposed train line.





1 out of 8
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.