ECON 380: Comprehensive Solutions to Statistical Problems
VerifiedAdded on 2023/06/04
|8
|1638
|262
Homework Assignment
AI Summary
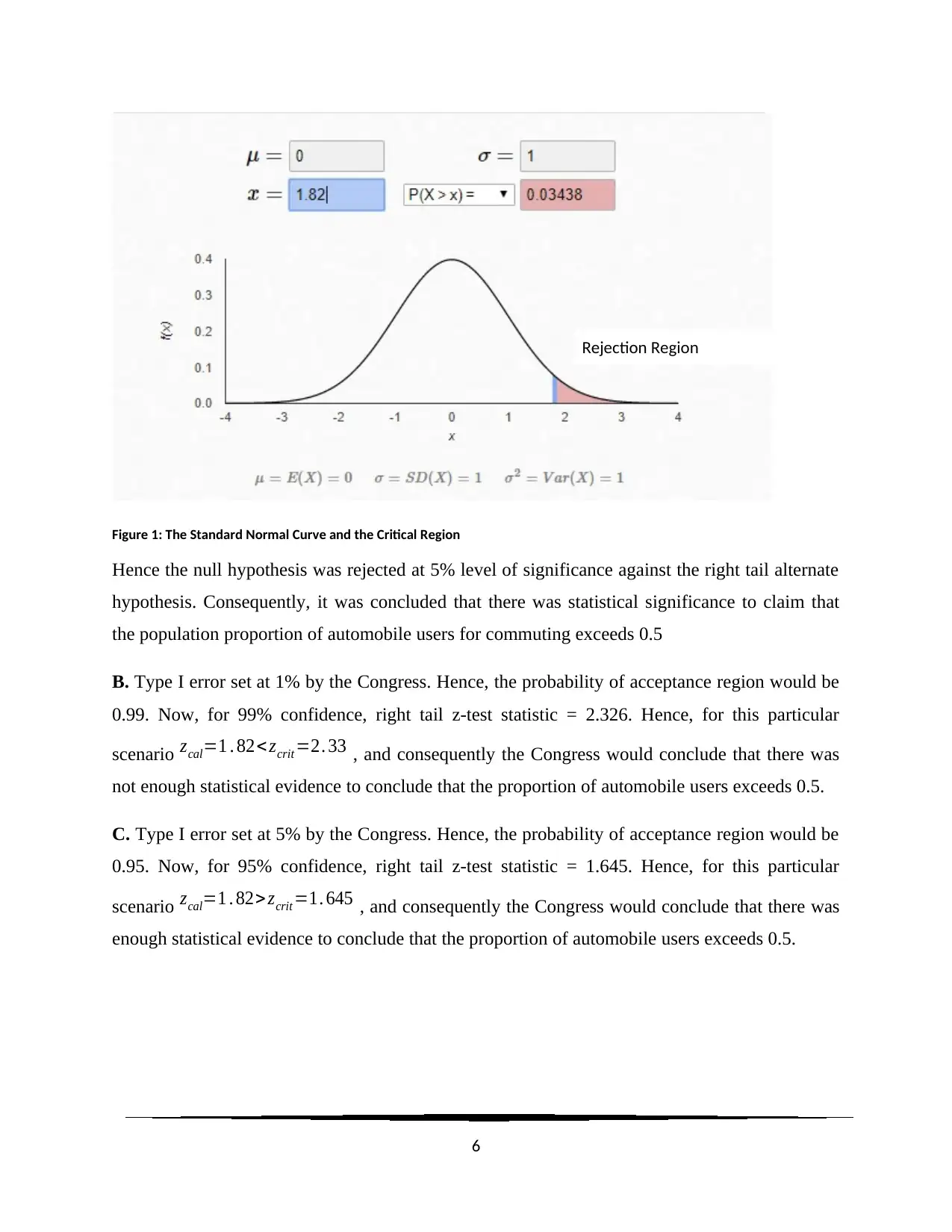
This document provides detailed solutions to several statistical problems. The problems cover a range of topics including one-sample t-tests to test claims about population means, two-sample independent t-tests to compare means between two groups, two-sample proportion z-tests to compare proportions, and one-sample proportion z-tests to test claims about population proportions. Additionally, a one-way ANOVA is used to check for differences in average salaries across different major groups. Each solution includes the null and alternative hypotheses, the calculation of test statistics, determination of p-values, and conclusions based on a 5% level of significance. The document also addresses Type I errors and their implications in decision-making. Desklib offers a platform for students to access similar solved assignments and past papers for academic support.







1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.