Statistical Analysis of Business Startup Costs and Sales Prediction
VerifiedAdded on 2020/03/28
|9
|1768
|788
Project
AI Summary
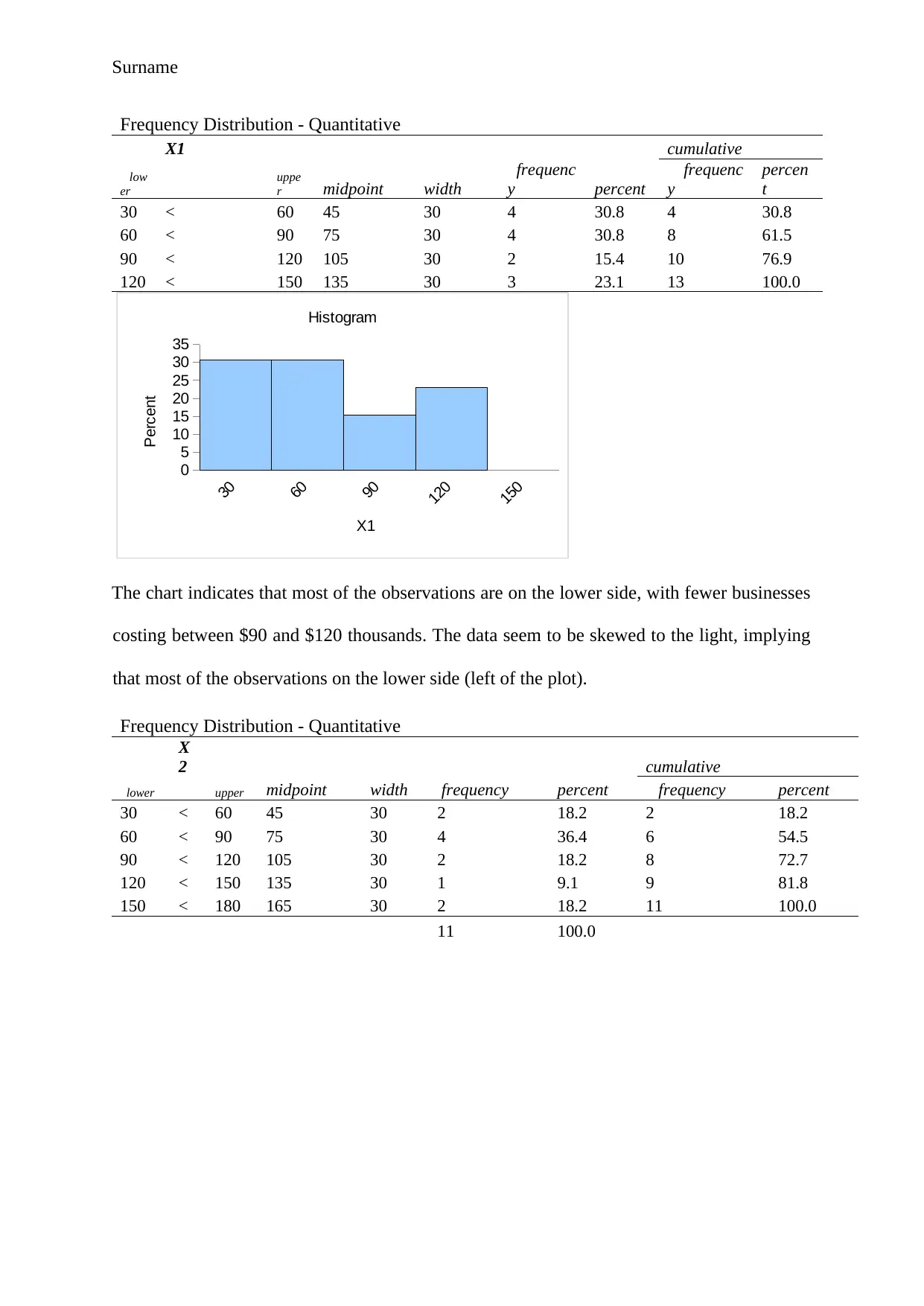
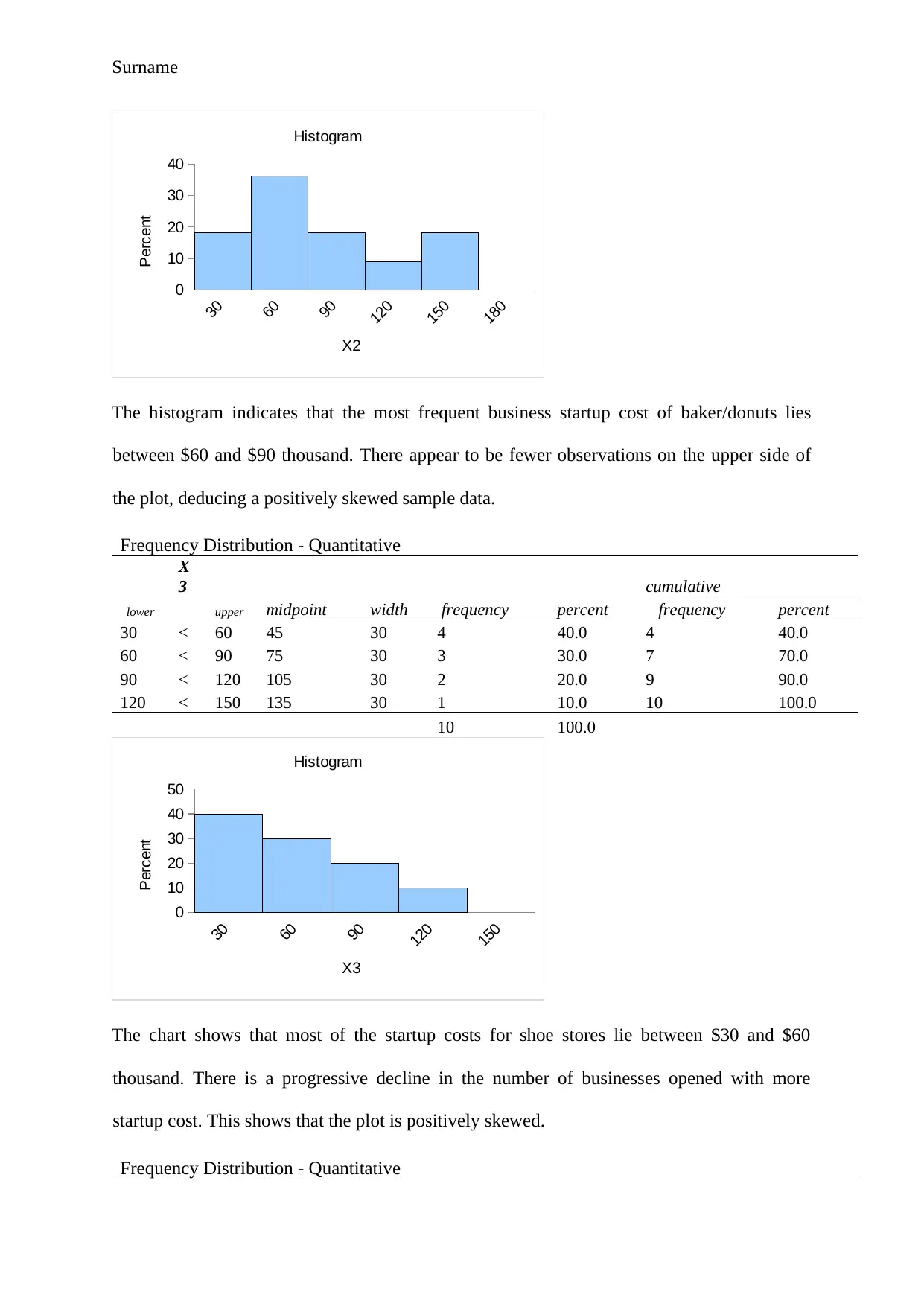
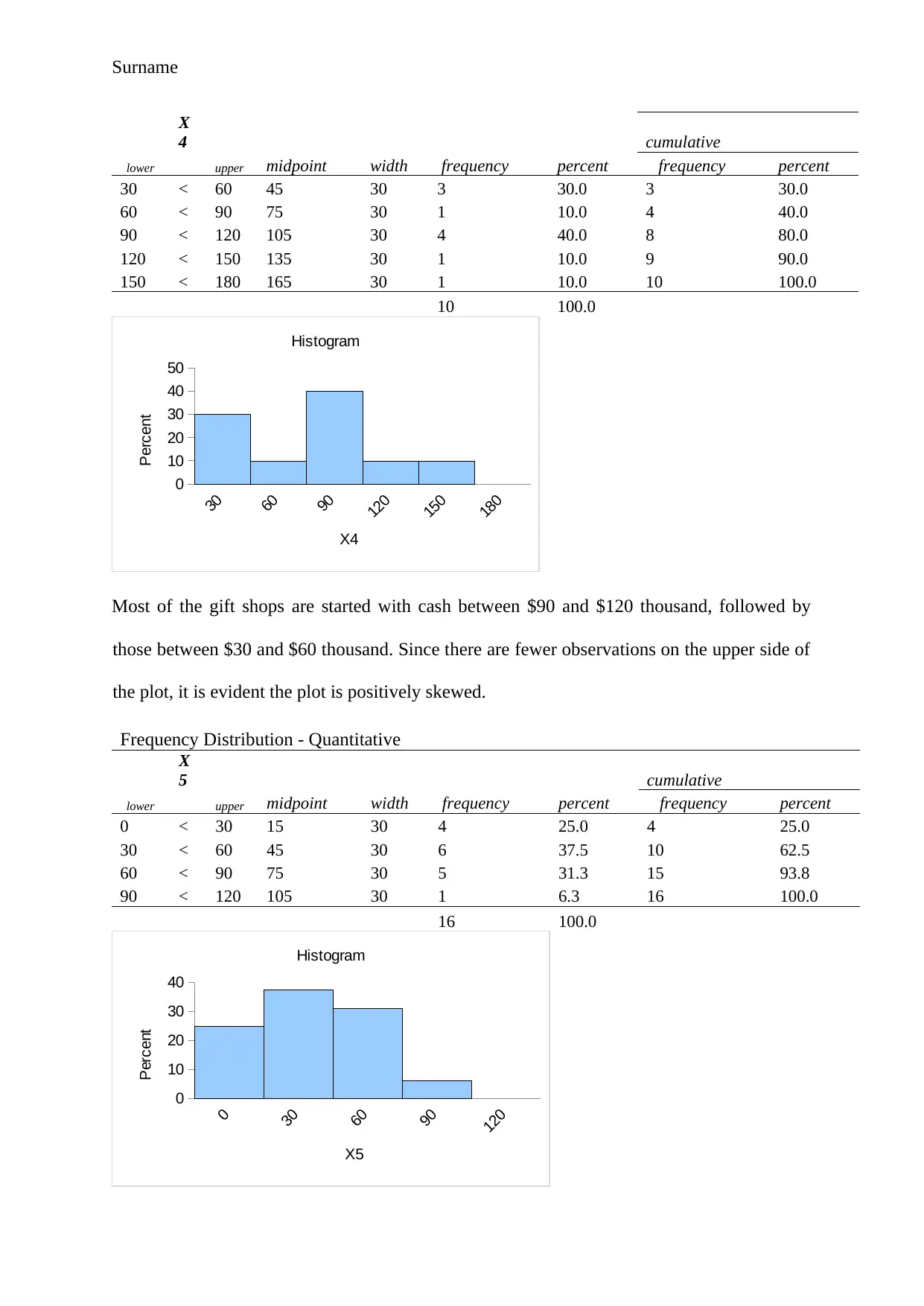
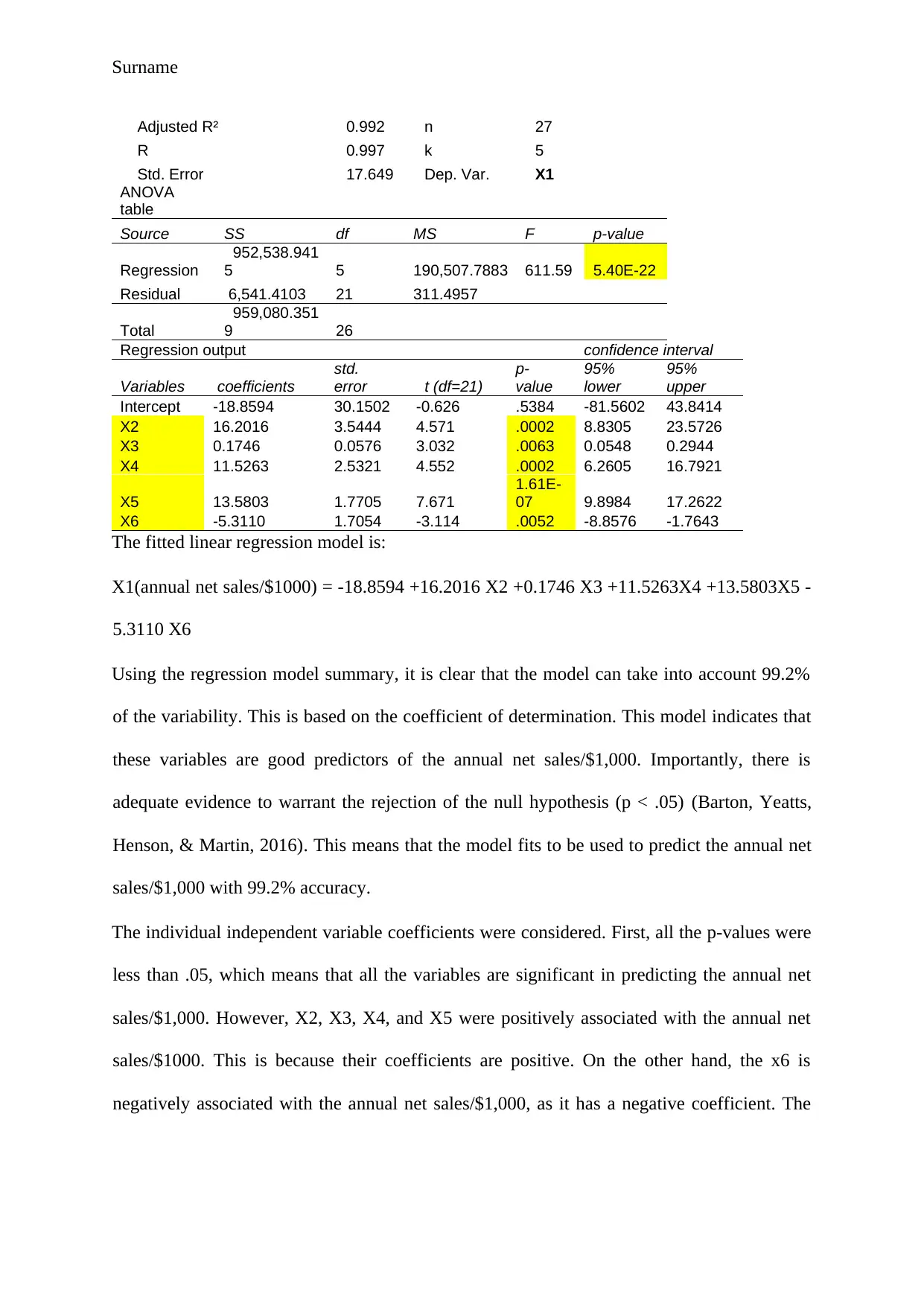
This project delves into a statistical analysis of business startup costs across five different types of shops: pizza, baker/donuts, shoe stores, gift shops, and pet stores. The analysis begins with descriptive statistics, including mean, median, mode, range, variance, standard deviation, and skewness, to understand the central tendencies and distributions of startup costs for each business type. Frequency distributions and histograms are used to visualize the data and identify patterns. An ANOVA test is conducted to determine if there are statistically significant differences in the average startup costs among the five businesses. Furthermore, a regression model is developed to assess the relationship between various factors, such as square footage, inventory, advertising spend, sales district size, and the number of competing stores, with annual net sales. The model's goodness-of-fit, significance of individual variables, and the ability to predict sales are evaluated. The project concludes with a practical application of the regression model to predict annual net sales based on specific input values. The findings highlight the statistical insights gained from the analysis and the predictive power of the regression model.





1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.