HI6007 Statistics Assignment: Frequency, Regression and ANOVA Table
VerifiedAdded on 2023/06/10
|7
|818
|371
Homework Assignment
AI Summary
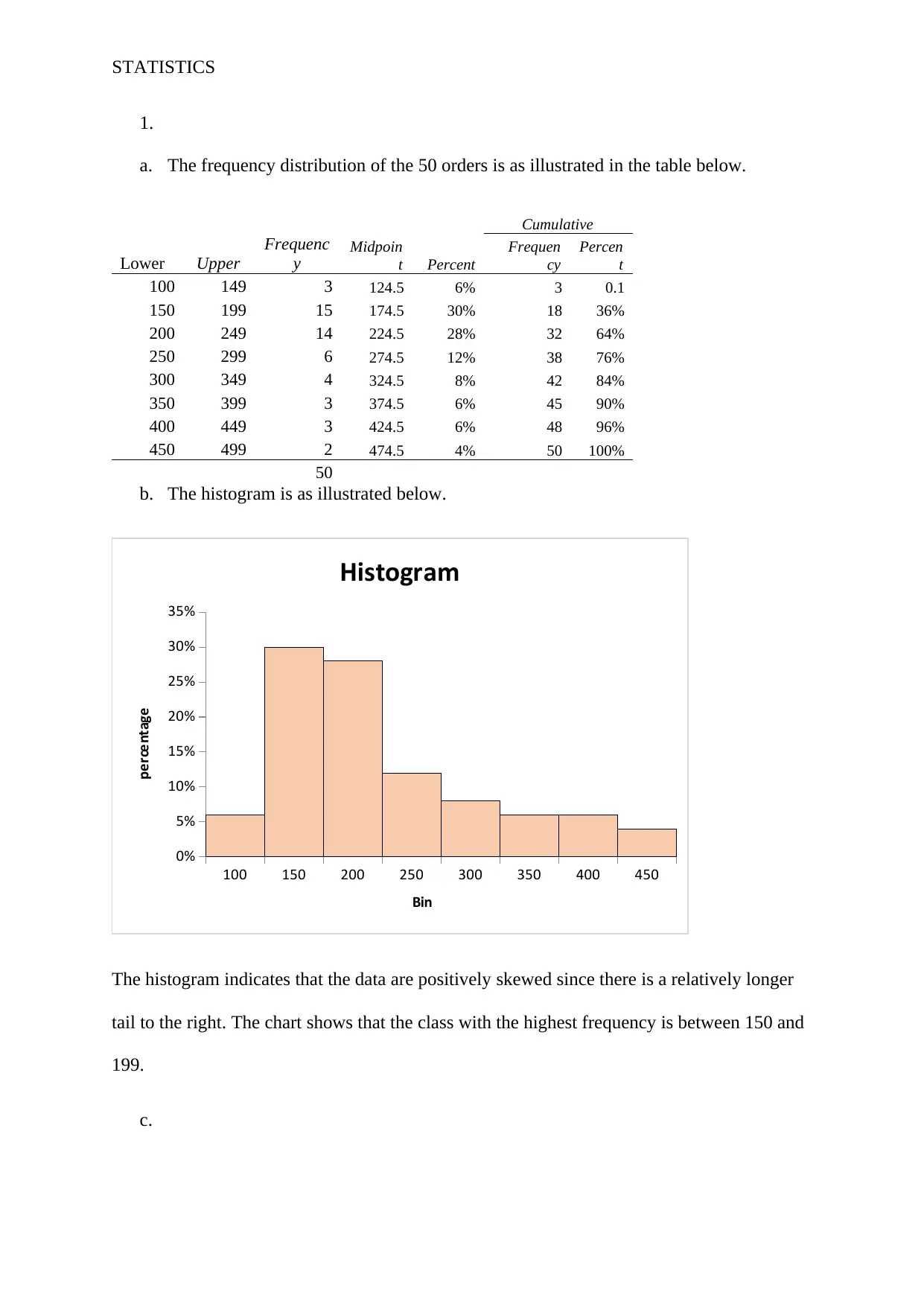
This assignment solution demonstrates statistical analysis techniques, including creating a frequency distribution from order data, interpreting a histogram, and determining the appropriate measure of central tendency for skewed data. It also includes the construction and interpretation of ANOVA tables to assess the significance of relationships between variables, such as demand and unit price. Furthermore, the assignment covers multiple regression analysis, providing a model to predict outcomes based on multiple independent variables and interpreting the coefficients. The solution calculates and interprets R-squared values and p-values to draw conclusions about the statistical significance of the findings. This document is available on Desklib, a platform offering a wealth of student resources.






1 out of 7
Related Documents



Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.