Statistics Assignment: Z-Scores, Regression, and Hypothesis Testing
VerifiedAdded on 2022/09/06
|6
|980
|18
Homework Assignment
AI Summary
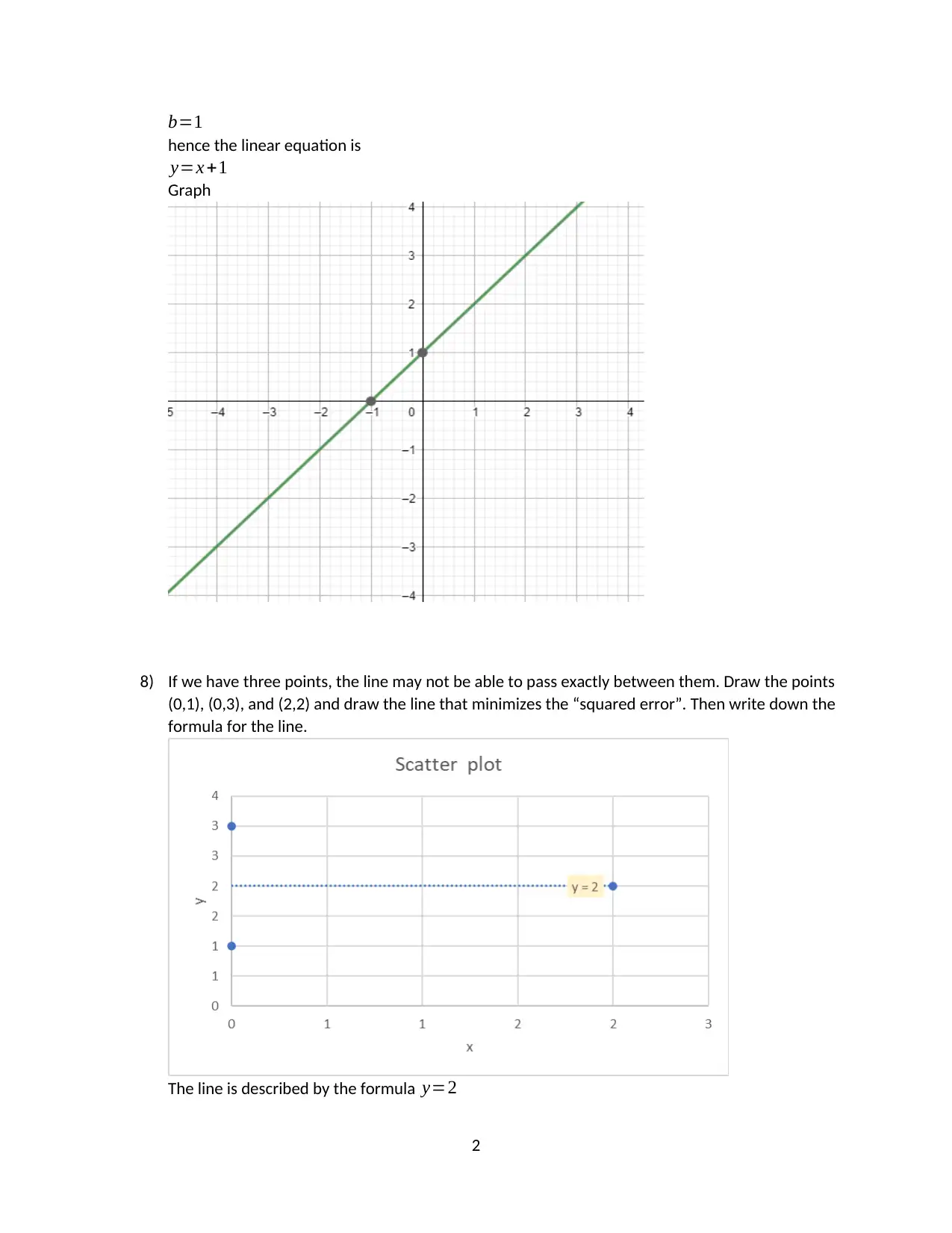
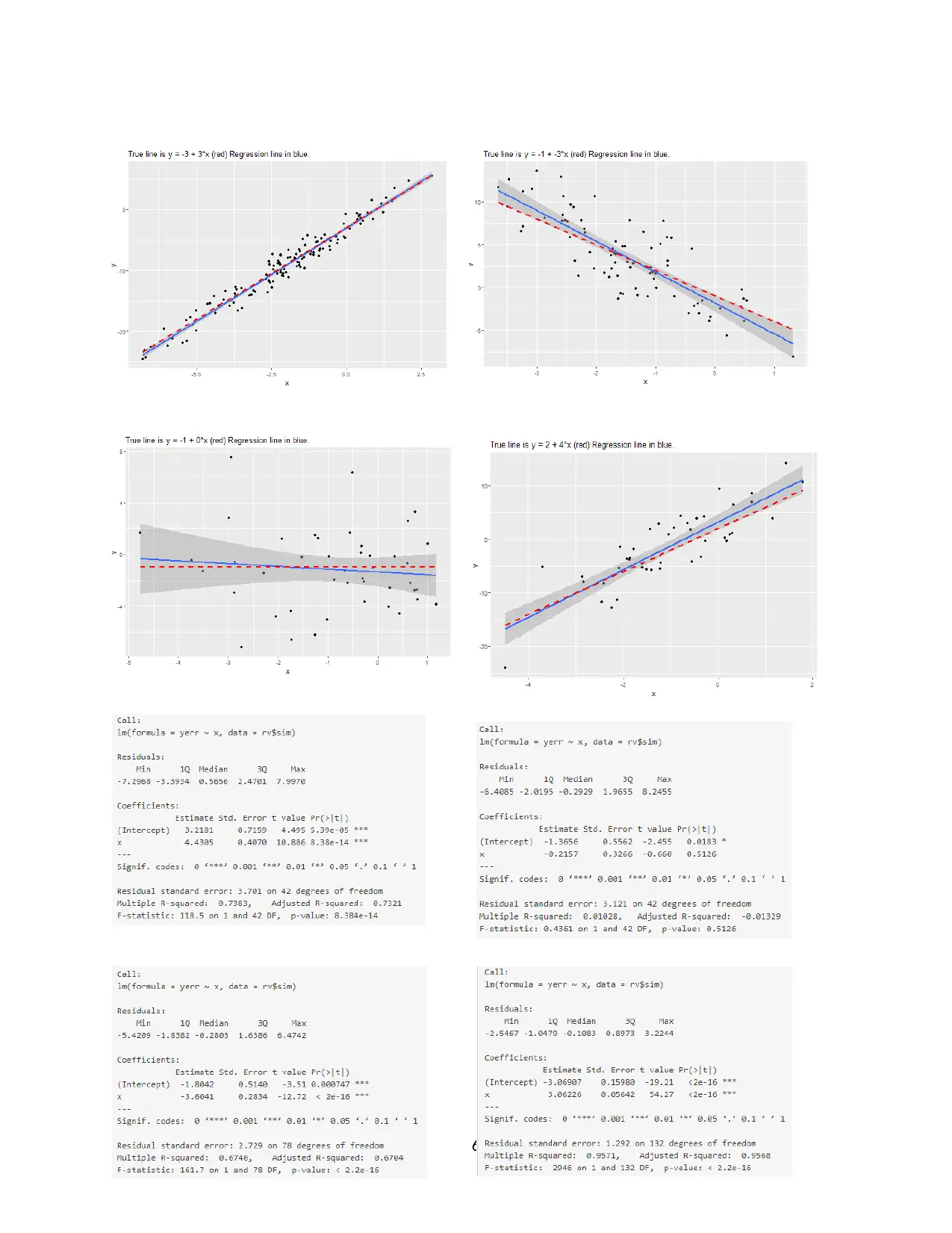
This assignment solution covers fundamental statistical concepts including Z-scores, confidence intervals, and linear regression. It begins with calculating Z-scores for given data points and determining corresponding x-values. The solution then explores linear regression, deriving the formula for a regression line and finding the equation for a line given two points. The assignment further delves into interpreting regression output, including the meaning of R-squared, t-values, and p-values, and how to perform hypothesis testing. The solution also addresses the comparison of average values between two groups using regression analysis and matching graphs to regression outputs. The solution provides detailed explanations and calculations for each question, offering a comprehensive understanding of the statistical concepts covered.




1 out of 6
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.