Statistics Homework Assignment: Data Analysis and Regression
VerifiedAdded on 2021/06/17
|7
|1102
|124
Homework Assignment
AI Summary
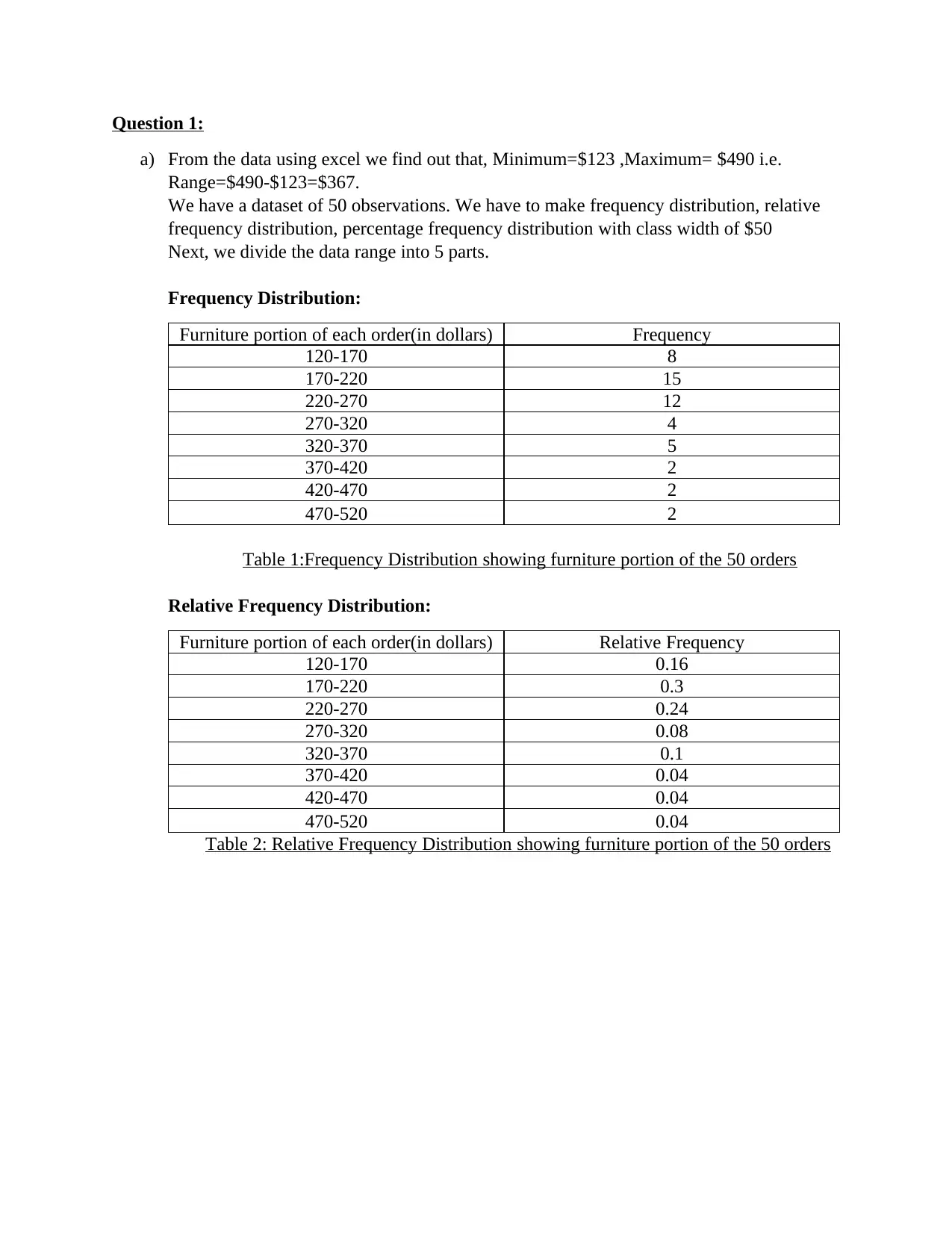
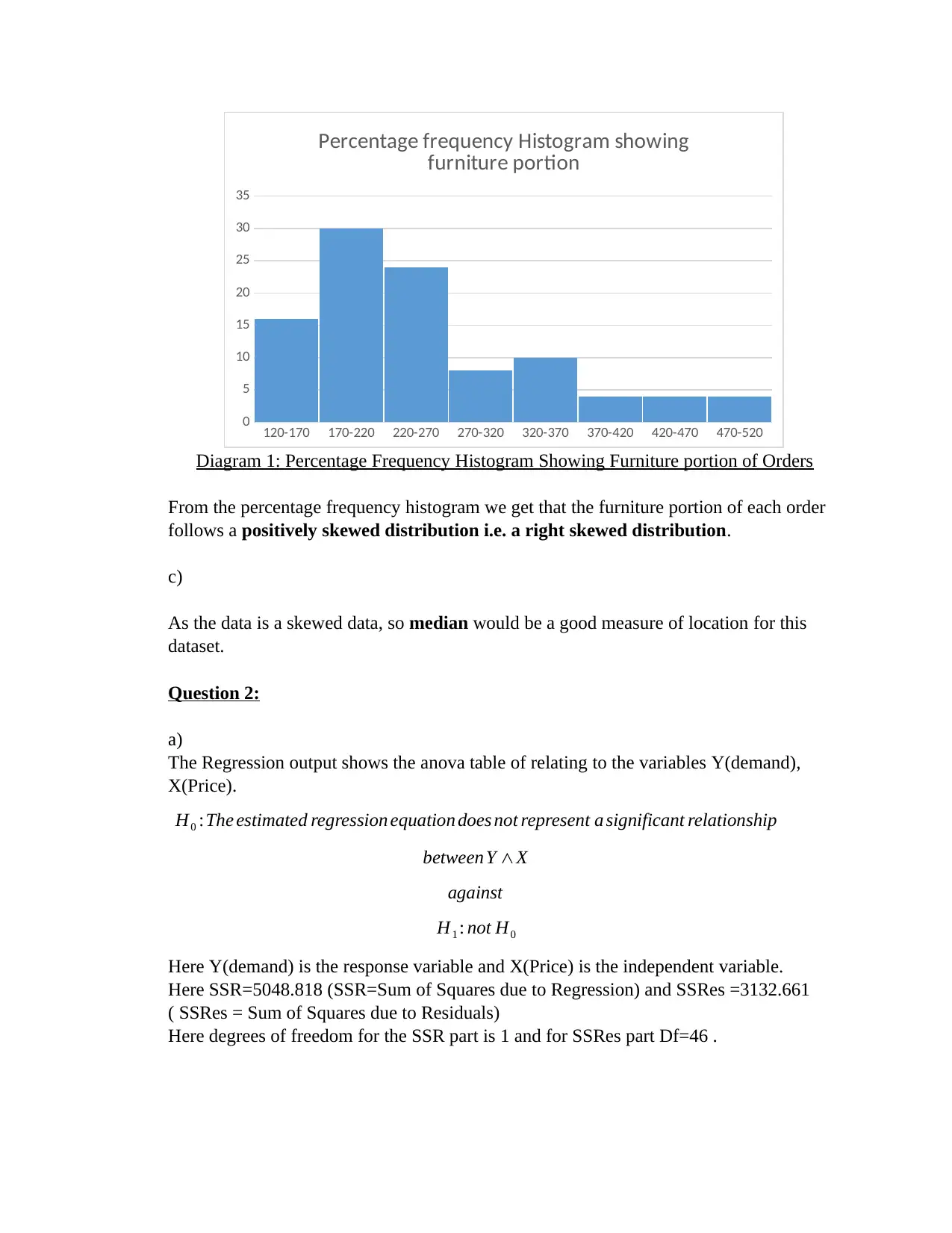
This statistics homework assignment provides a comprehensive analysis of data using various statistical methods. The assignment begins with the calculation of range and the creation of frequency, relative frequency, and percentage frequency distributions for a given dataset, along with a visual representation through a histogram. The analysis then moves on to regression analysis, examining the relationship between demand and unit price, including the calculation of the coefficient of variation and correlation coefficient. Furthermore, the assignment investigates the comparison of means across three populations using ANOVA. Finally, the assignment concludes with a multiple regression analysis, exploring the relationship between sales and advertising spots and price, along with interpretations of coefficients and predictions based on the regression equation. The assignment provides detailed calculations and interpretations, offering a clear understanding of the statistical concepts and their application.




1 out of 7
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.