Statistics 8: Business Data Modelling Assignment Analysis Report
VerifiedAdded on 2022/10/02
|13
|1381
|278
Homework Assignment
AI Summary
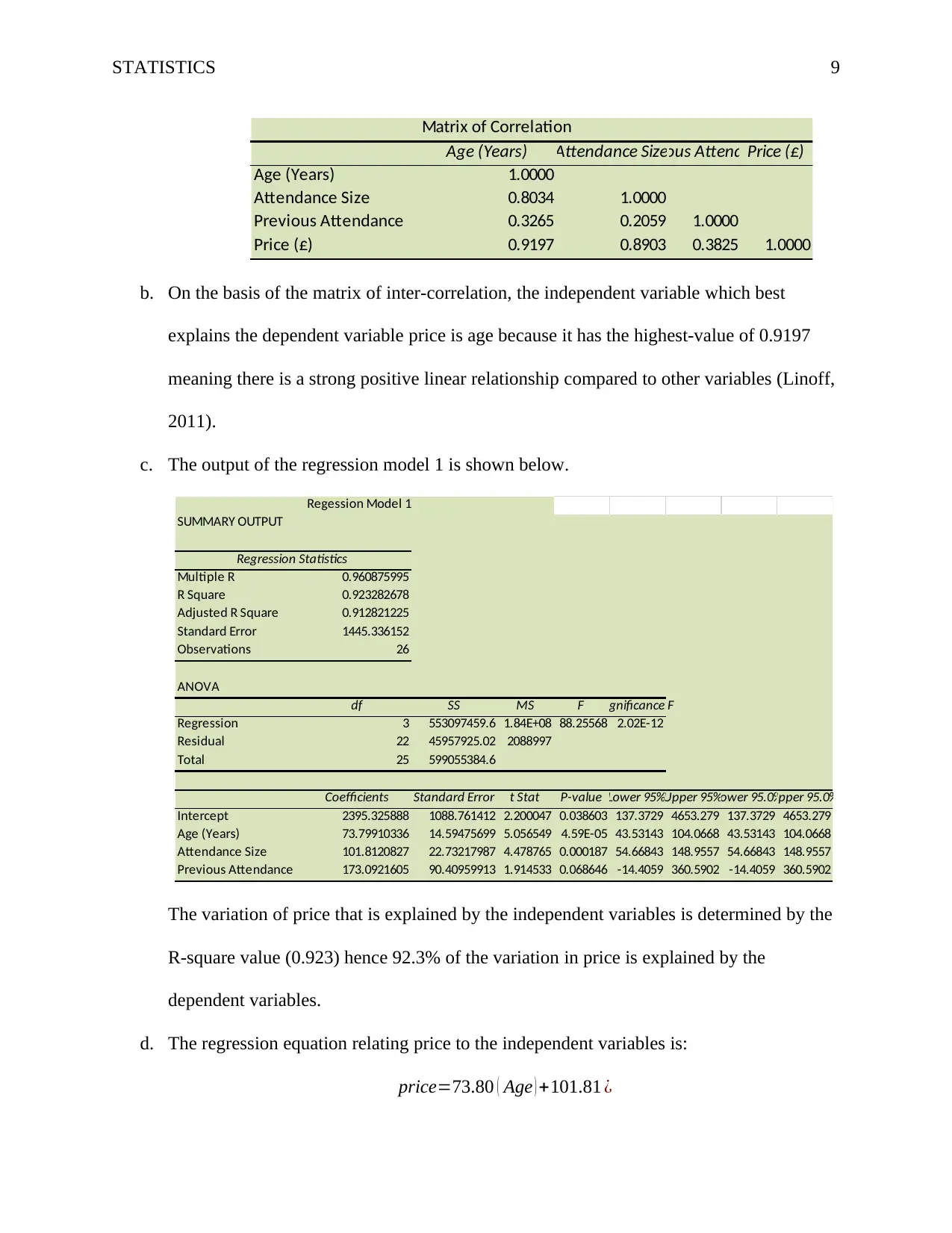
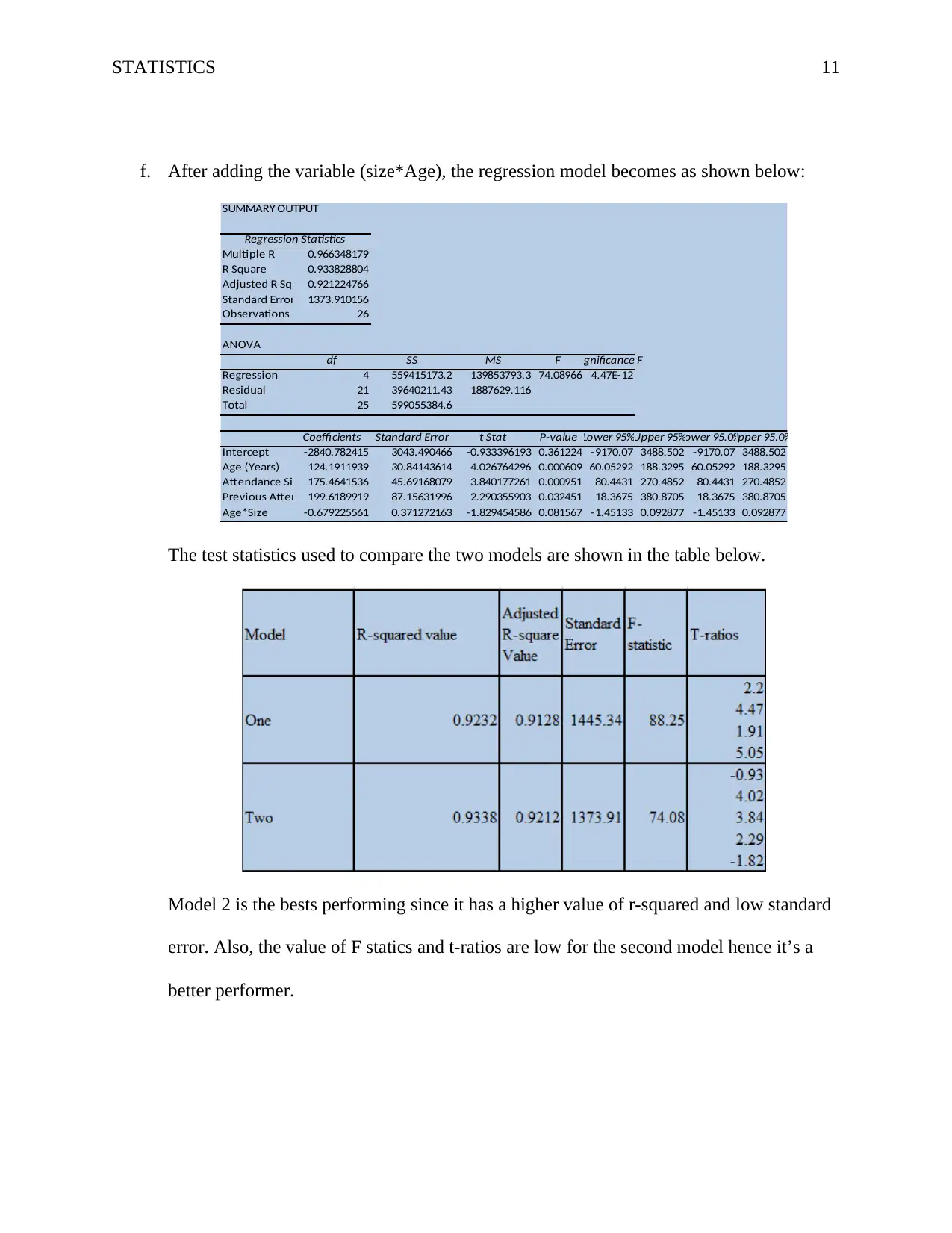
This assignment is a comprehensive analysis of business data modelling using statistical methods. It begins with an examination of categorical variables using a Chi-square test to determine the independence of purchasing behavior and gender. The assignment then proceeds to compare the mean ages of workers at different locations using ANOVA, followed by the Turkey-Kramer test to identify significant mean differences. Finally, it explores relationships between variables such as price, age, and size using scatter plots, correlation matrices, and regression models. The student evaluates the impact of different variables on the regression model's performance, including the addition of interaction variables, and provides interpretations of the results. The assignment includes calculations, interpretations, and critical value comparisons to support conclusions.






1 out of 13
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.