Statistics Homework: Analysis of Variance, Regression and Data
VerifiedAdded on 2021/06/17
|7
|1228
|108
Homework Assignment
AI Summary
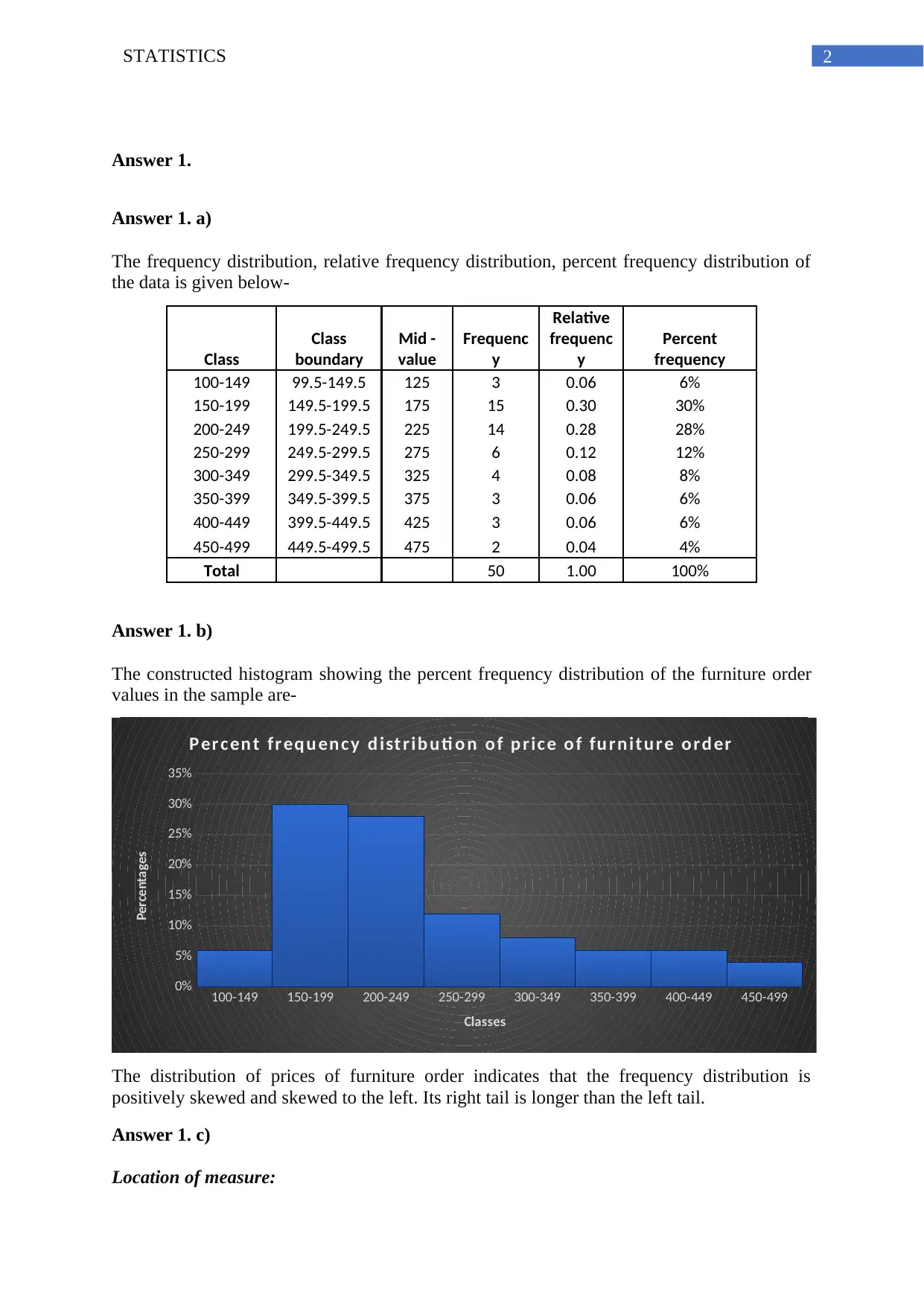
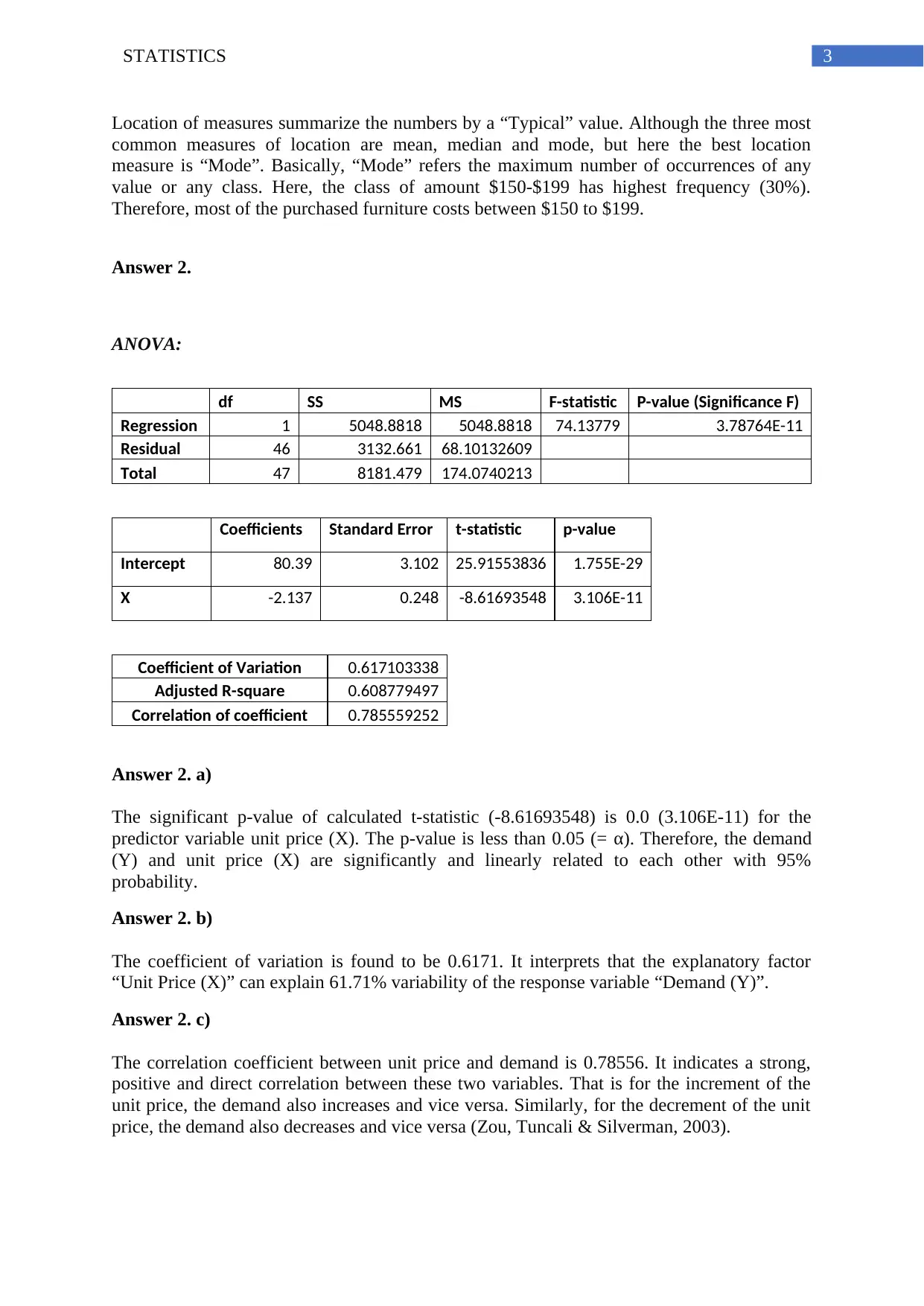
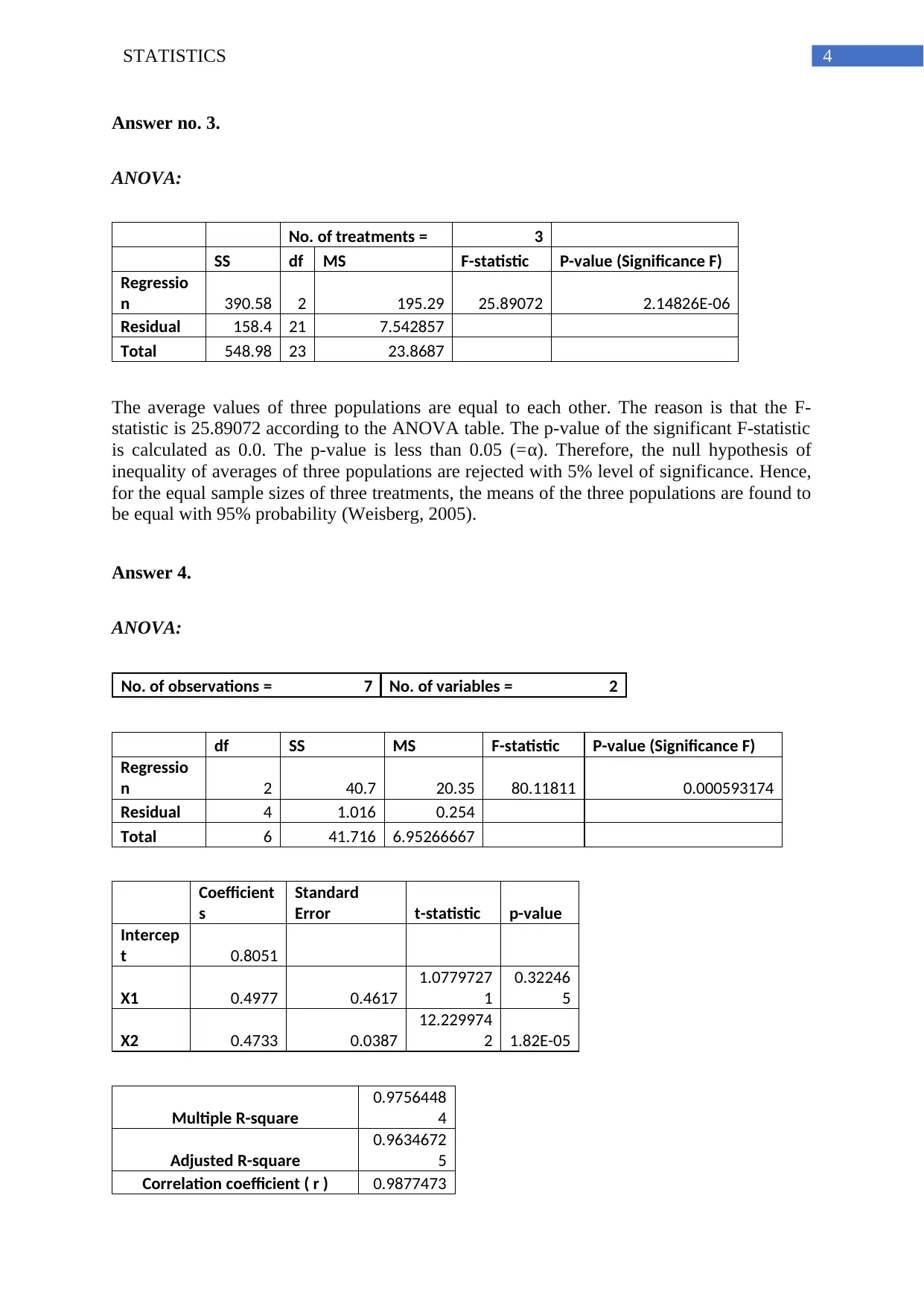
This statistics assignment presents a comprehensive analysis of various statistical concepts. It begins with a frequency distribution analysis, including calculations of relative and percent frequencies, and the construction of a histogram to visualize the data. The assignment then delves into regression analysis, providing ANOVA tables, coefficient of variation, and correlation coefficients to assess the relationship between variables. The analysis includes interpretations of p-values and t-statistics to determine statistical significance. Furthermore, the assignment explores ANOVA to compare the means of multiple populations, determining whether the means are equal. Finally, the assignment culminates in a multiple regression analysis, estimating a linear regression equation and interpreting the coefficients to understand the impact of independent variables on the dependent variable. The assignment covers concepts of statistical significance, correlation, and interpretation of regression models.




1 out of 7
Related Documents


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.