Statistics for Business and Finance Assignment 1 Analysis
VerifiedAdded on 2020/03/01
|11
|1105
|101
Homework Assignment
AI Summary
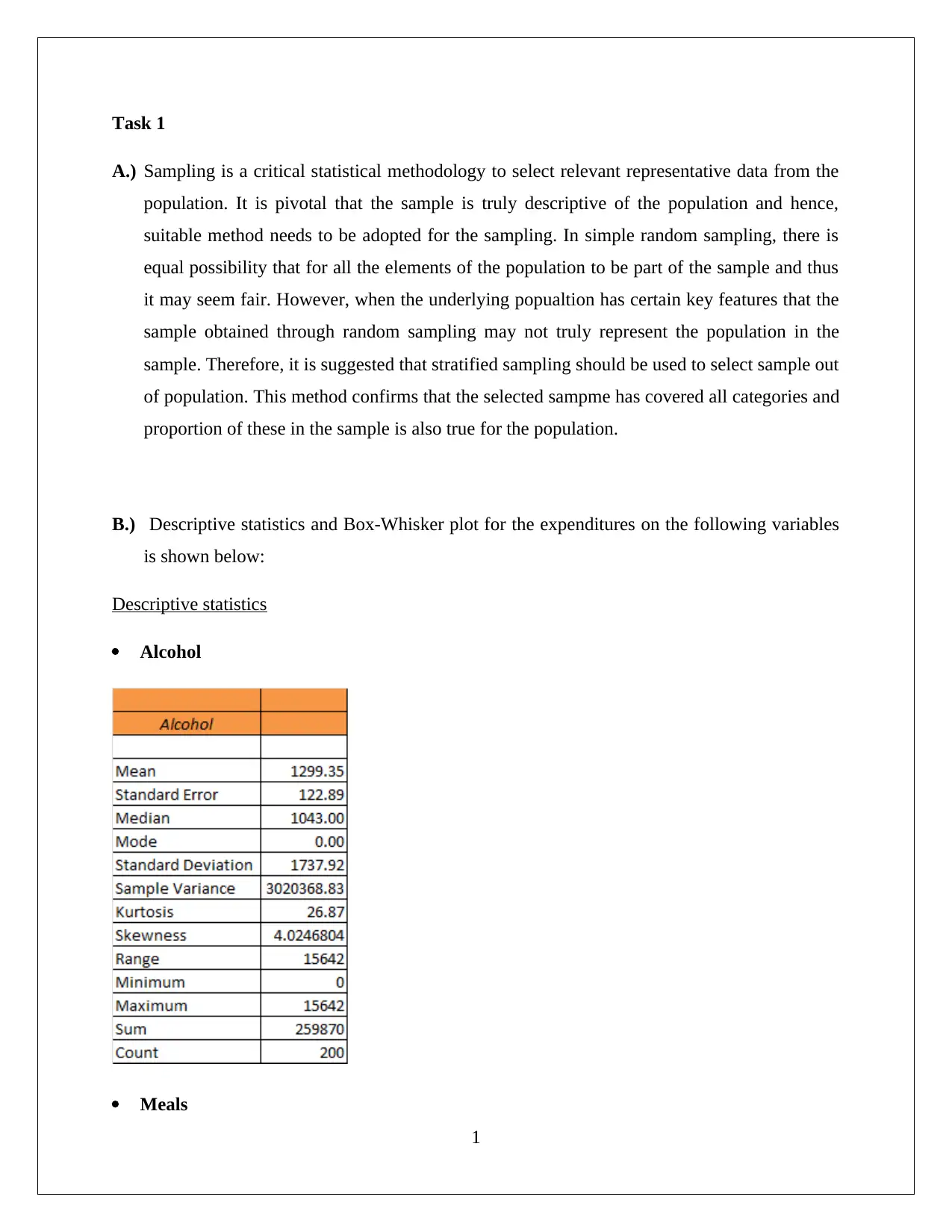
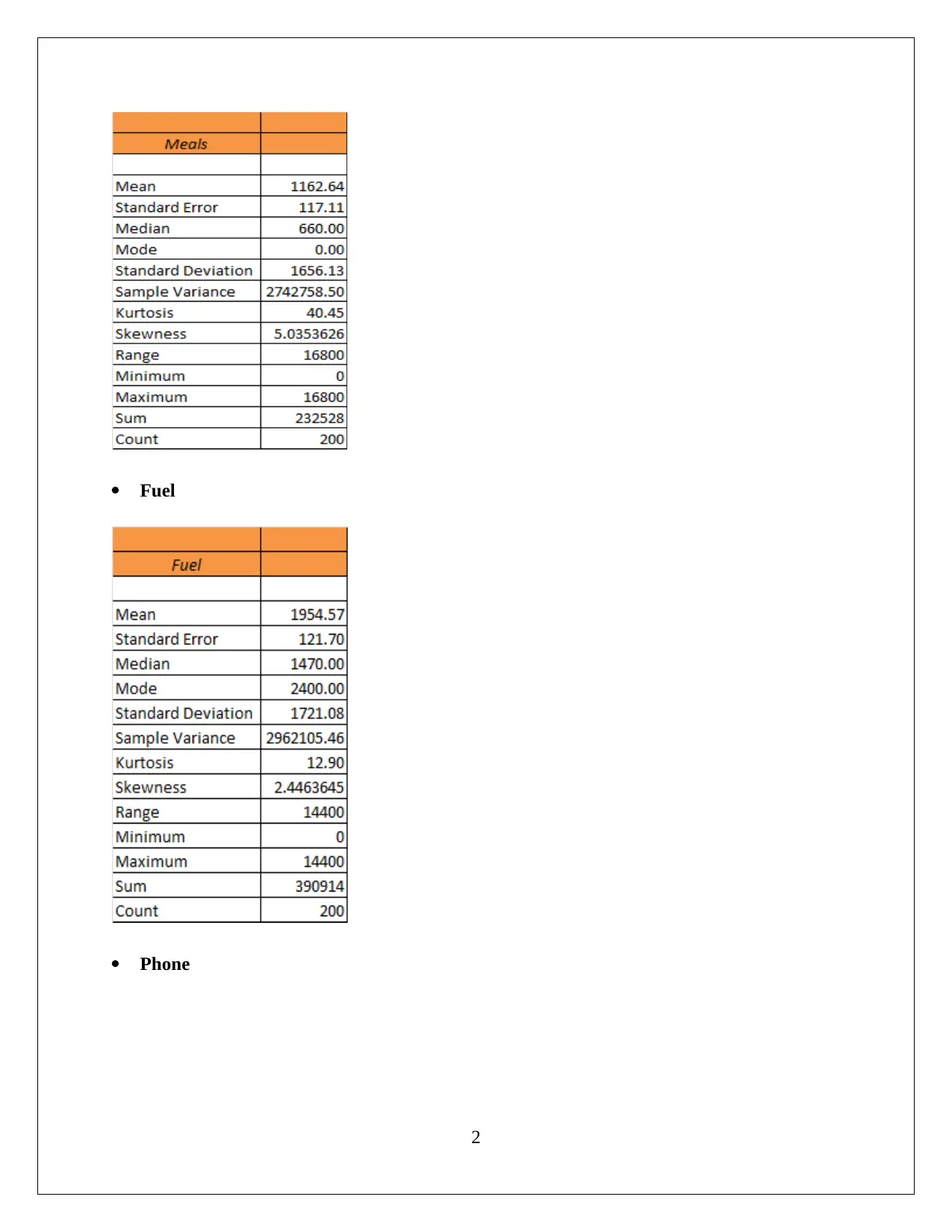
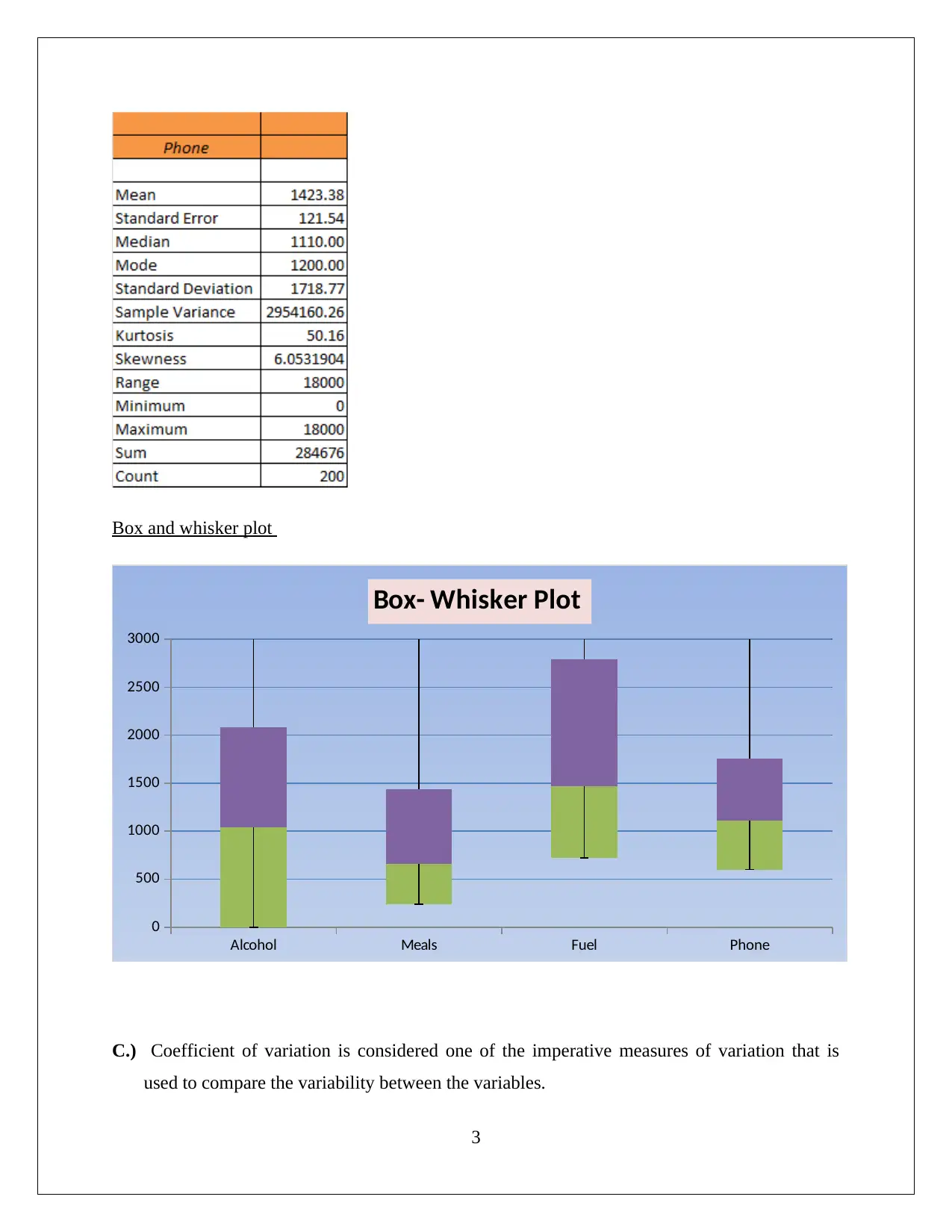
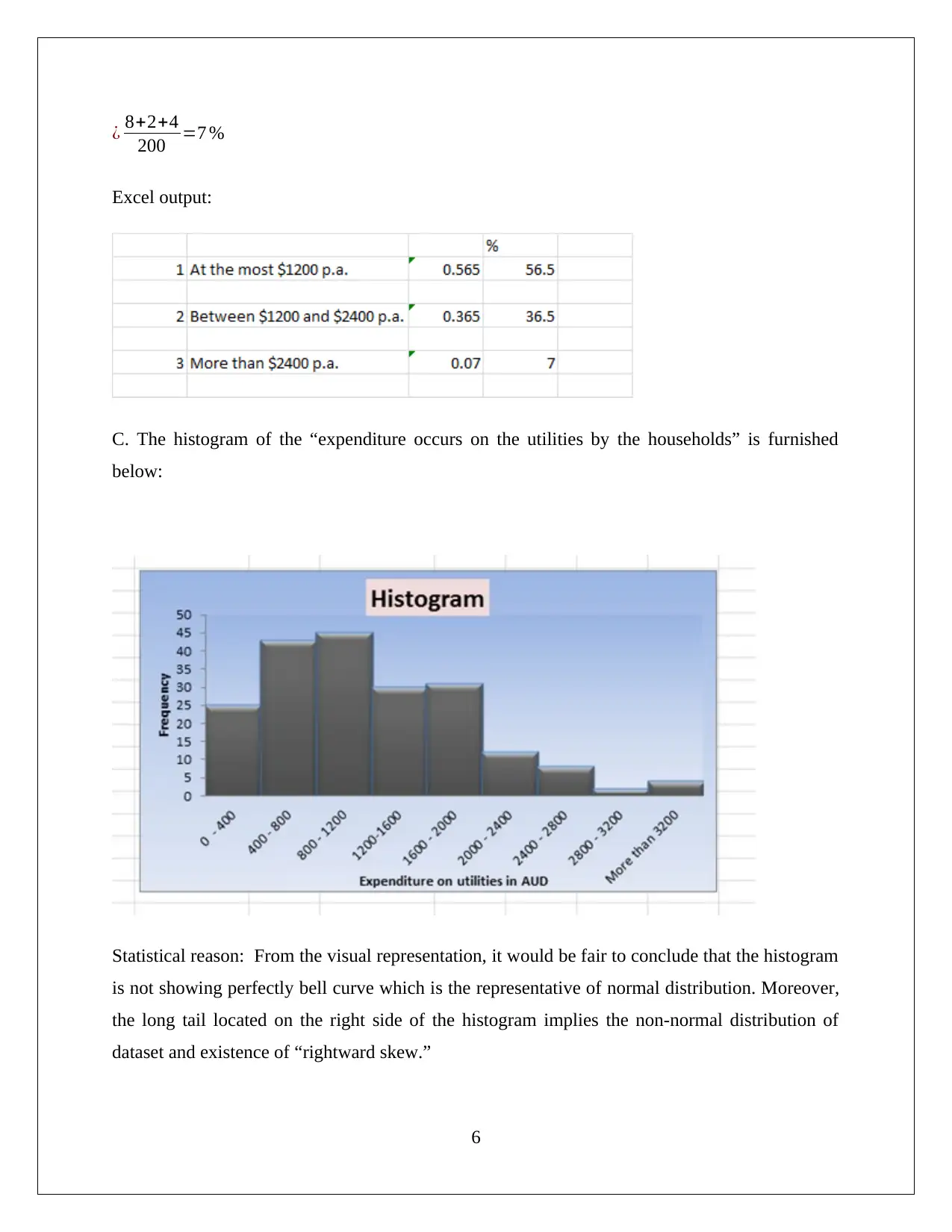
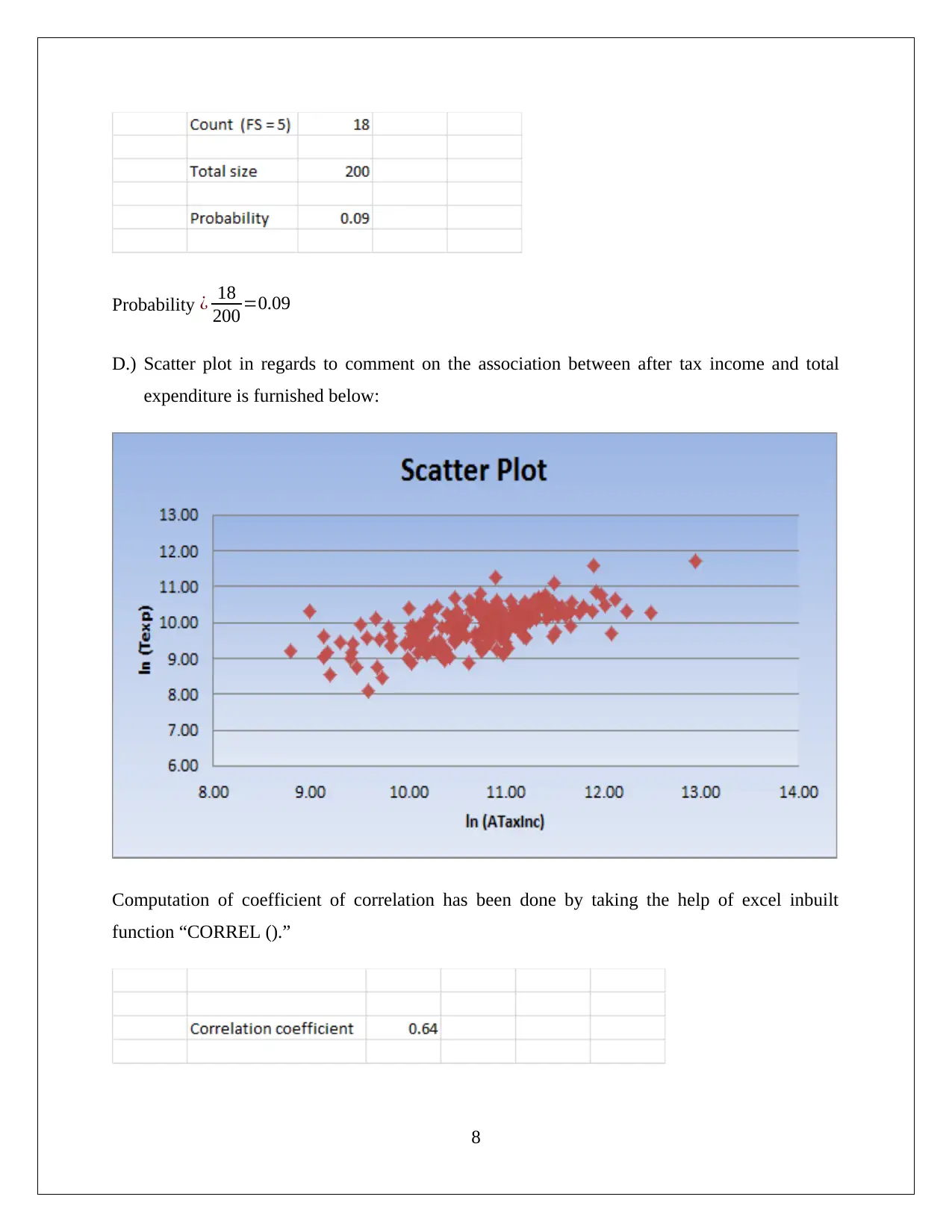
This statistics assignment analyzes household data using various statistical techniques. Task 1 focuses on sampling methods, descriptive statistics (including mean, median, mode, and skewness) for expenditures on alcohol, meals, fuel, and phone, and the use of box-whisker plots and the coefficient of variation to assess variability. Task 2 examines the frequency distribution and histogram of utility expenditures, assessing normality and skewness. Task 3 delves into household income, top and bottom income percentiles, home ownership analysis, family size probabilities, and a scatter plot and correlation analysis of income and total expenditure. Task 4 presents a contingency table analyzing the relationship between gender and education level, calculating probabilities and assessing the independence of events. The assignment demonstrates a comprehensive understanding of statistical concepts and their application to real-world data analysis, including the use of Excel for calculations and visualizations.






1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.