Statistics for Managerial Decisions - Data Analysis and Report
VerifiedAdded on 2022/11/24
|10
|657
|294
Homework Assignment
AI Summary
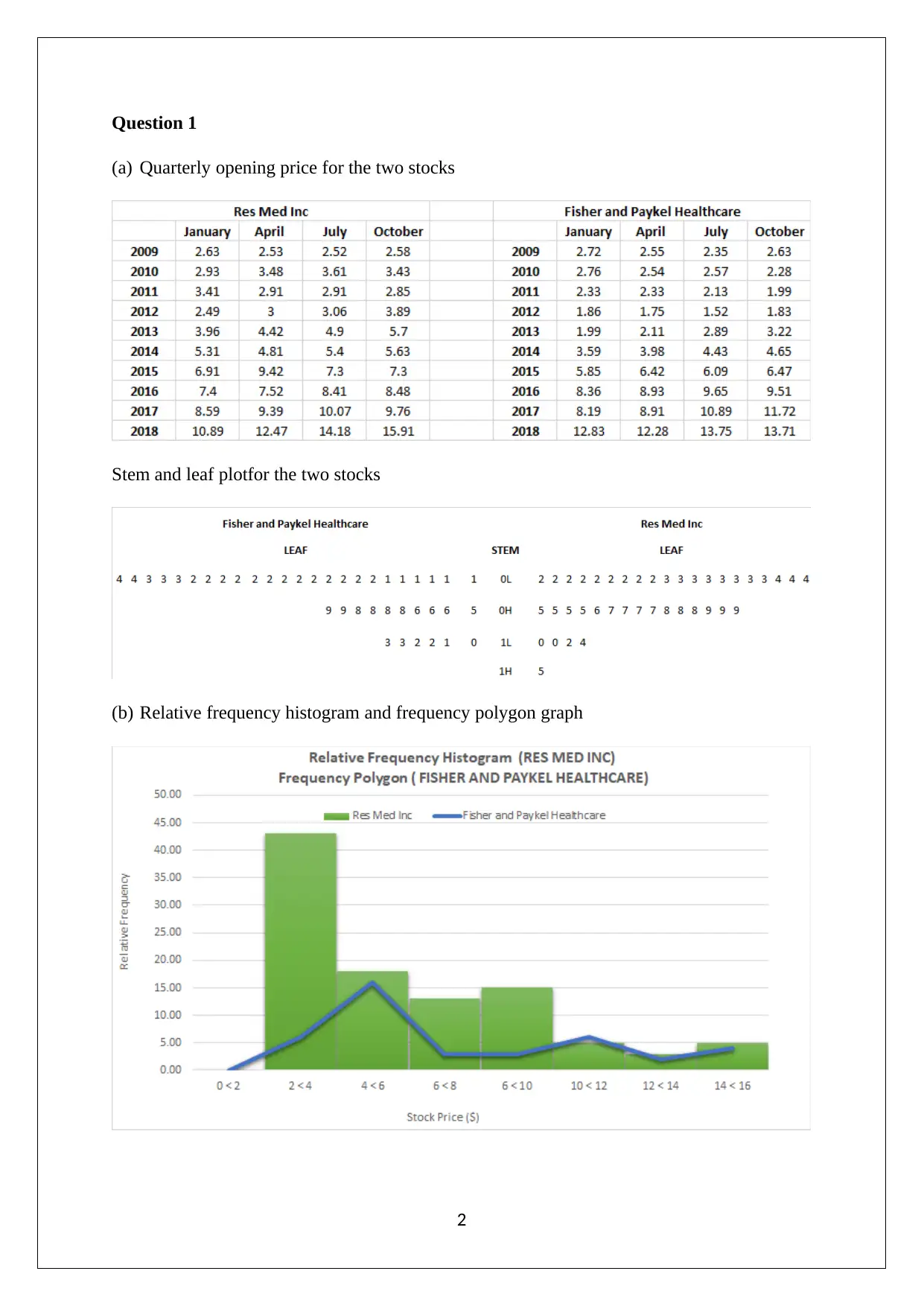
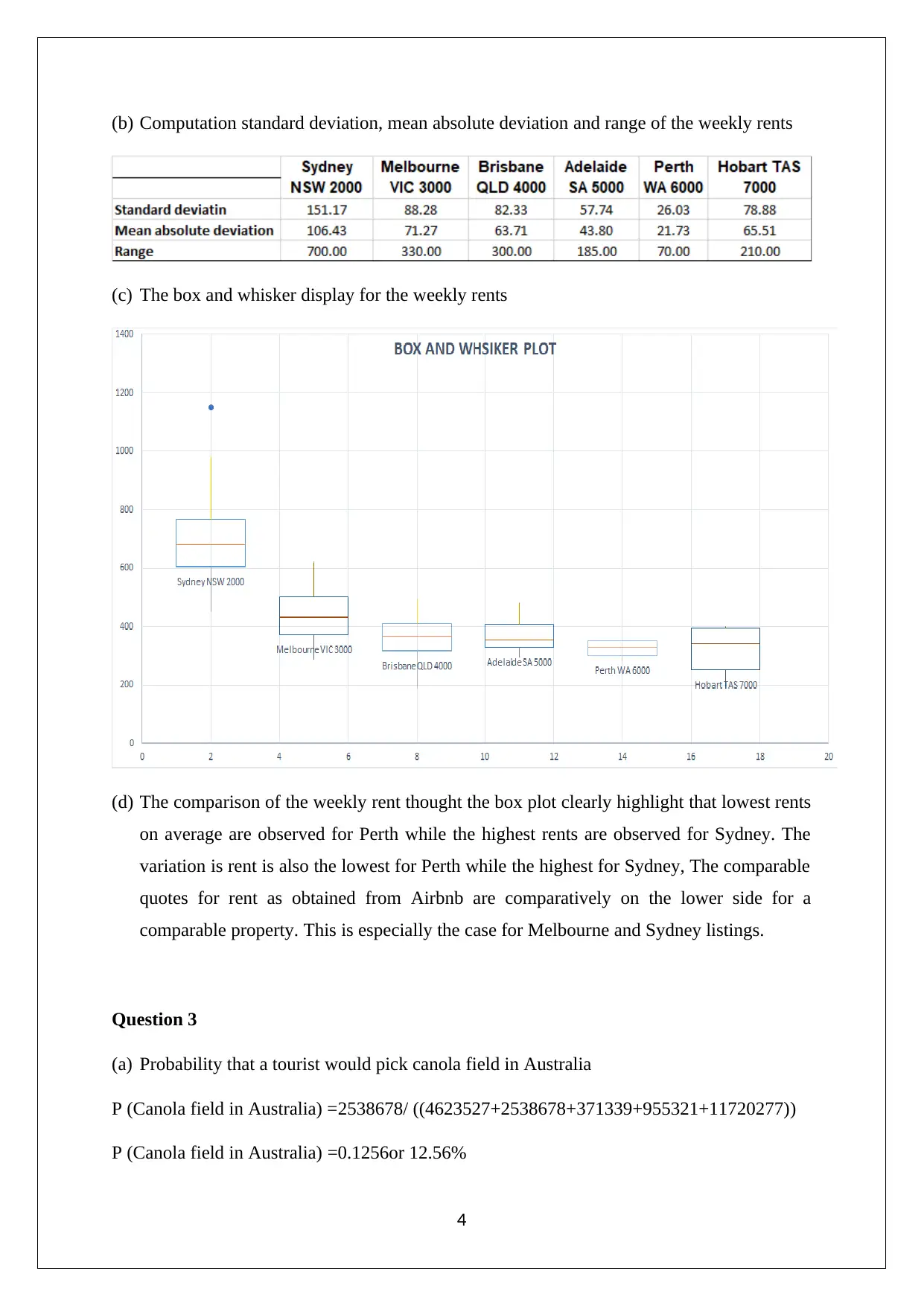
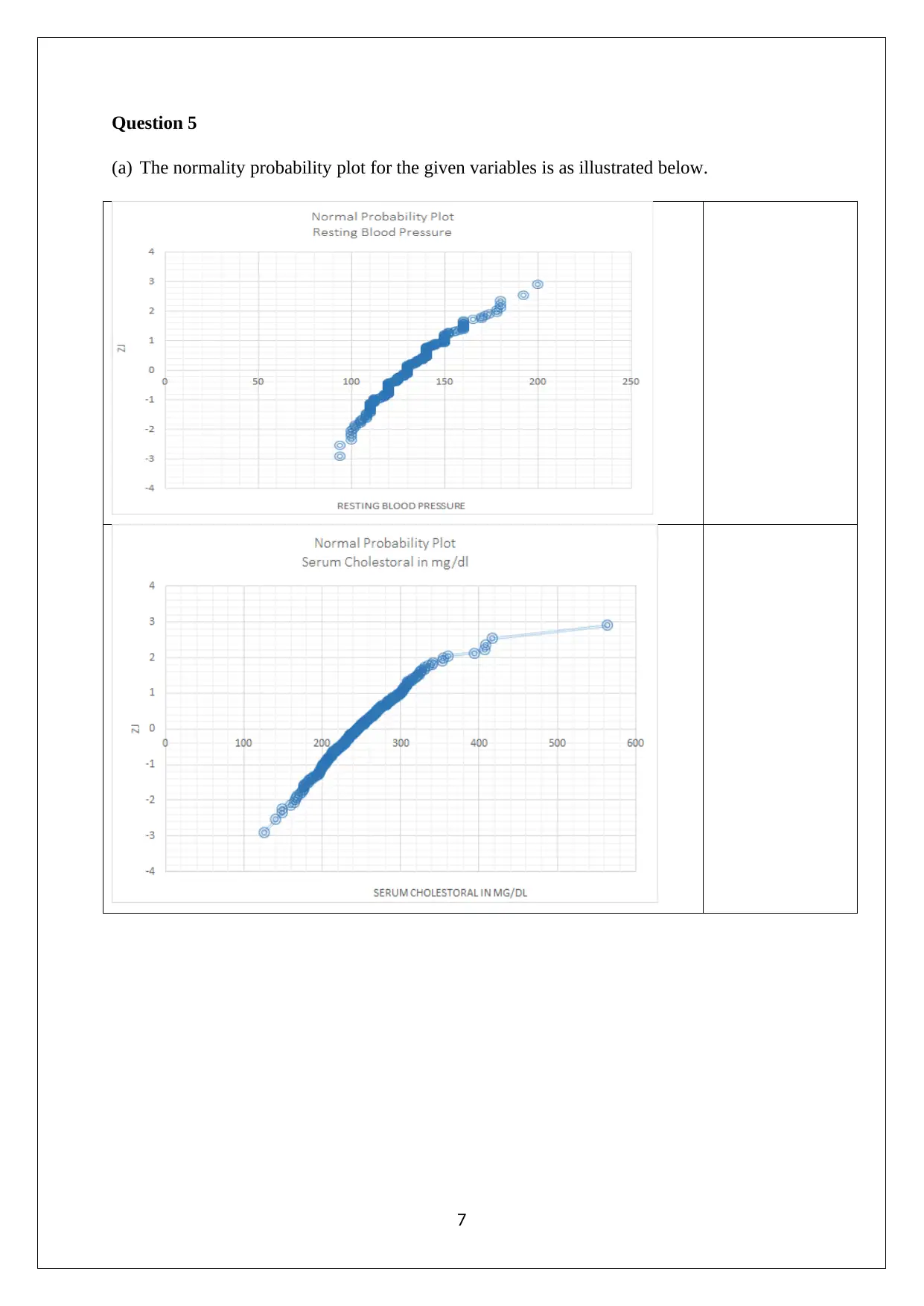
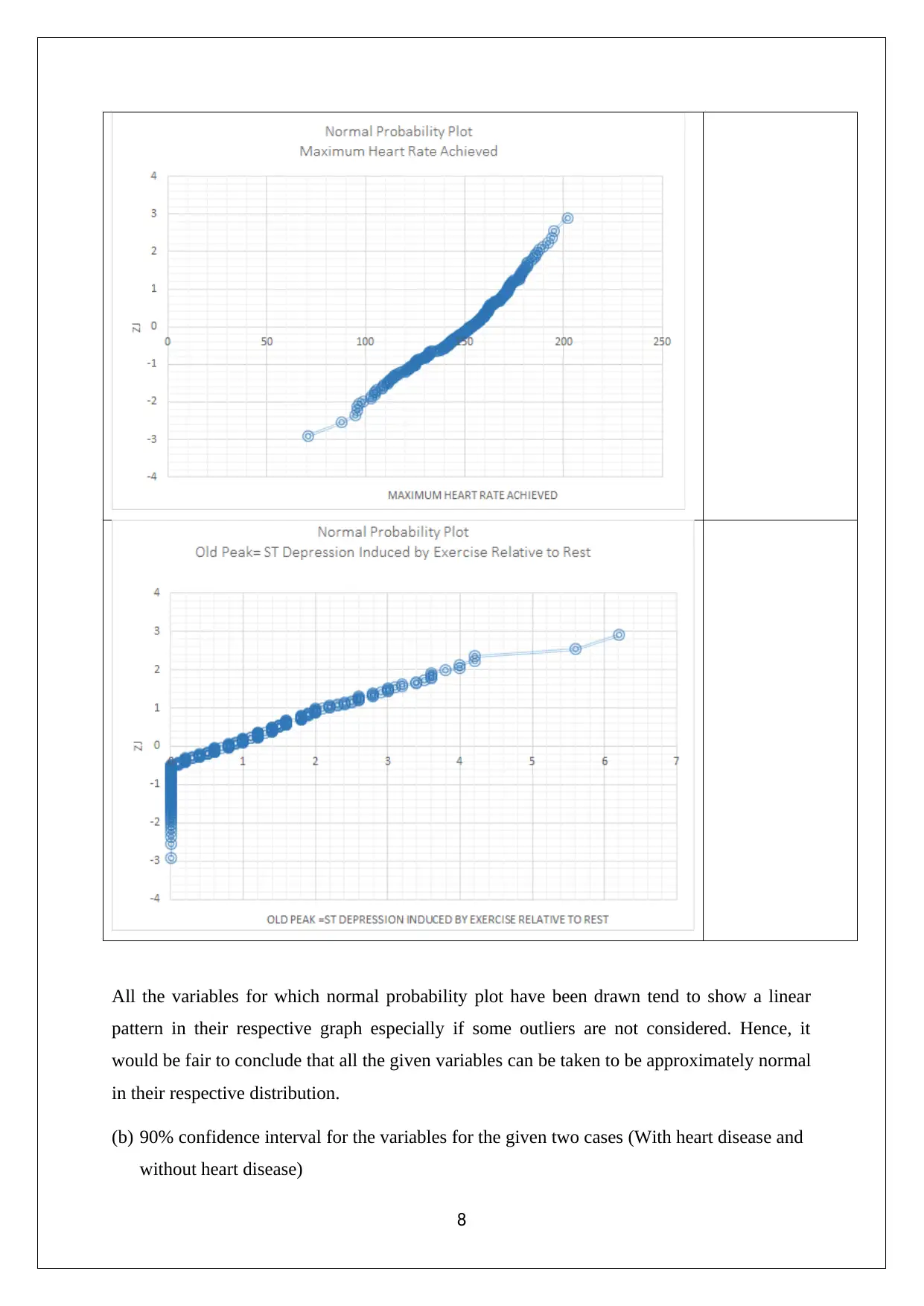
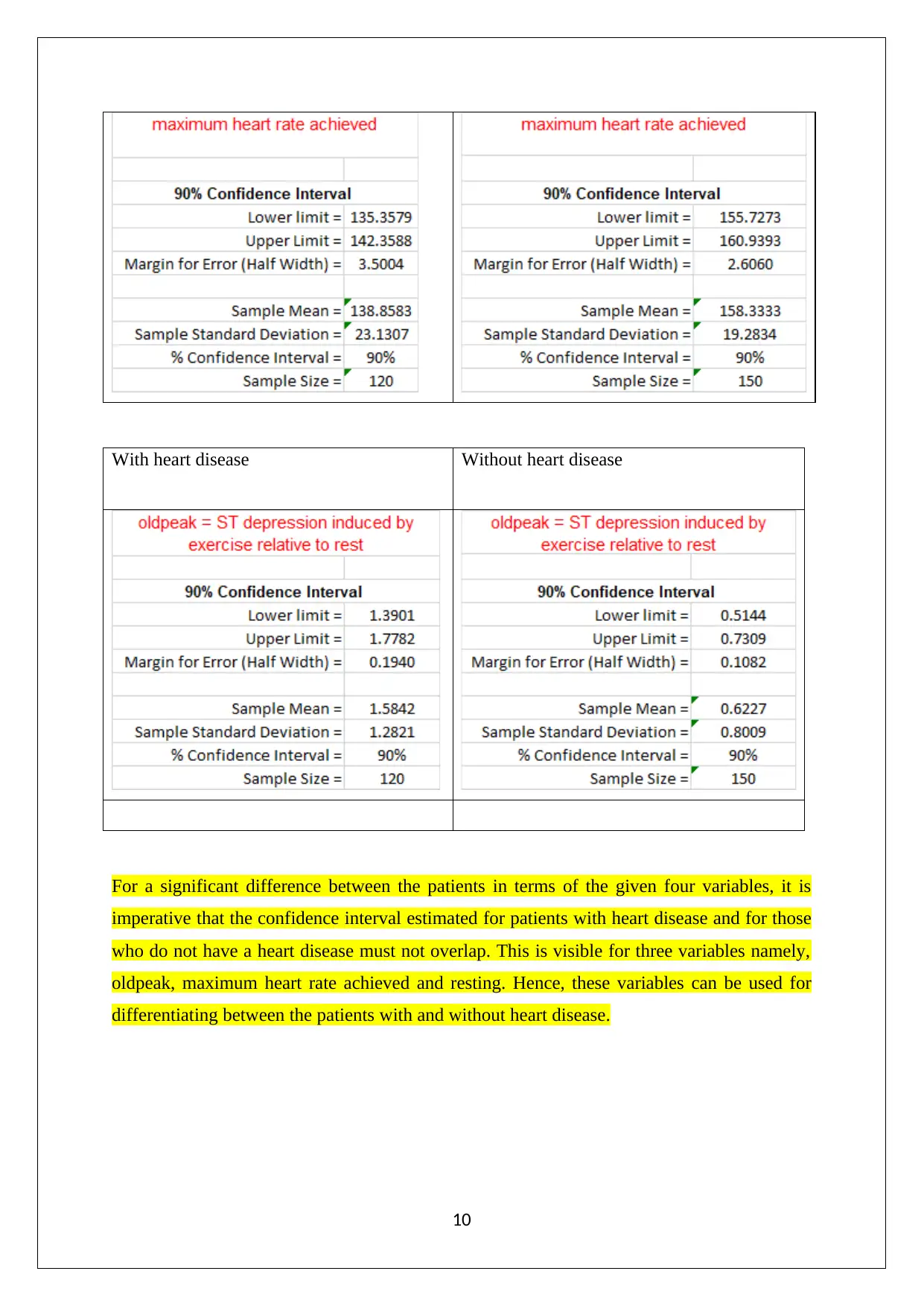
This assignment solution covers various statistical concepts relevant to managerial decisions. It includes data analysis techniques such as stem and leaf plots, relative frequency histograms, and bar graphs to analyze market capitalization data. Probability calculations are performed for different scenarios, including the probability of tourists picking canola fields and wheat fields, as well as analyzing rainfall distributions using Poisson and normal distributions. Furthermore, the assignment explores confidence intervals to differentiate between patients with and without heart disease. The solution demonstrates the application of statistical methods to real-world problems, providing a comprehensive analysis of the given data and drawing meaningful conclusions. The assignment also includes calculations of mean, median, quartiles, standard deviation, and box plots to analyze weekly rents, offering a thorough understanding of statistical concepts.





1 out of 10
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.