Statistics Group Project: Data Analysis of Student Performance
VerifiedAdded on 2020/12/18
|17
|3134
|119
Project
AI Summary
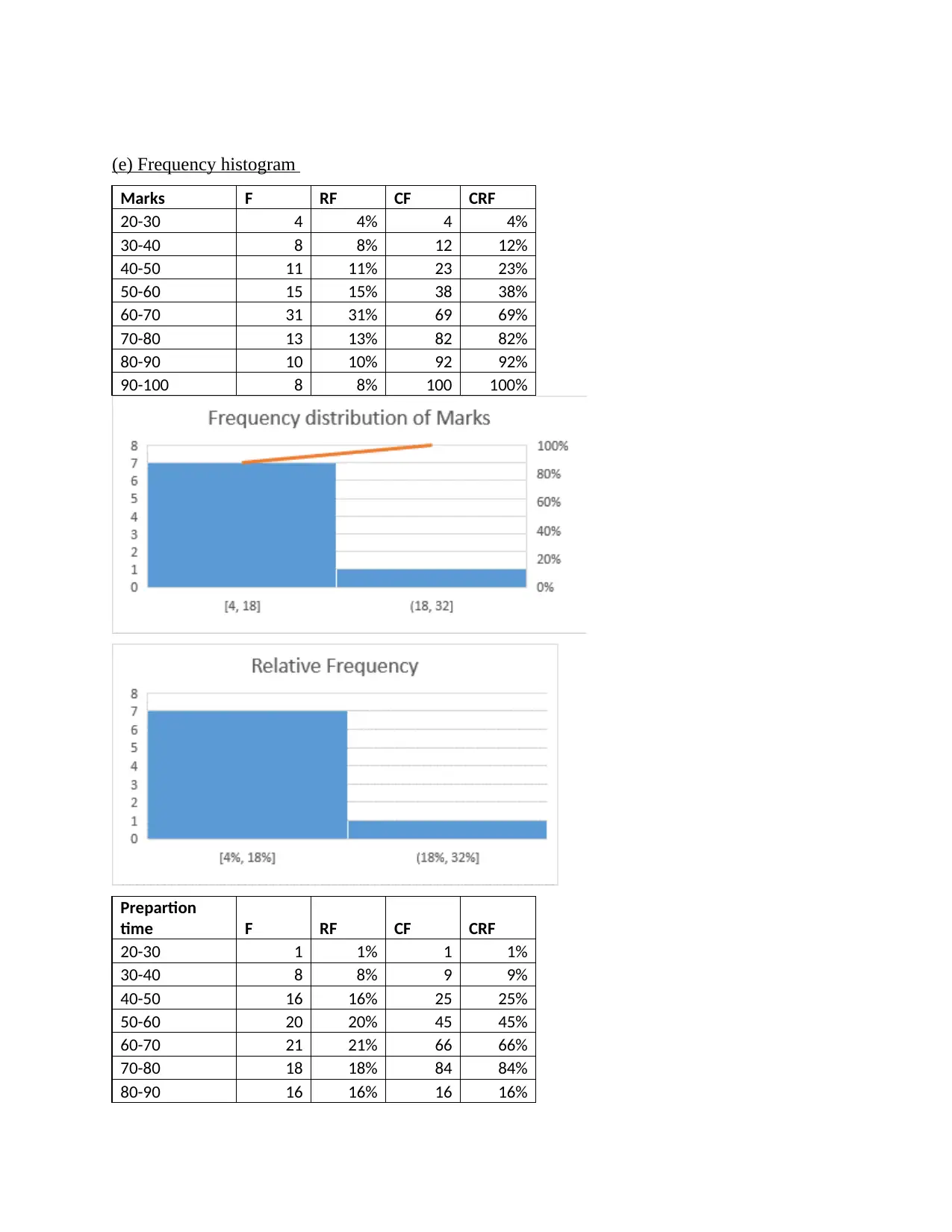
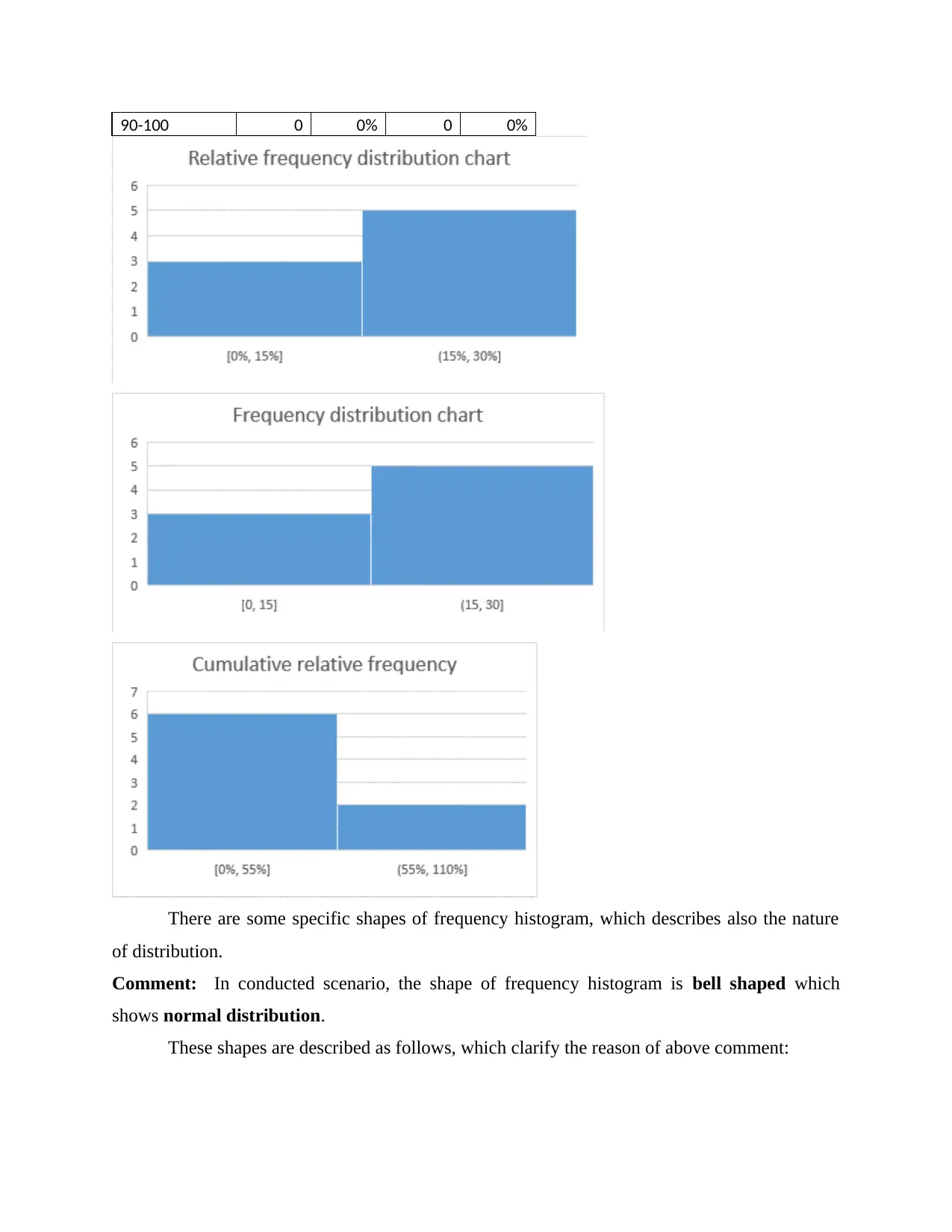
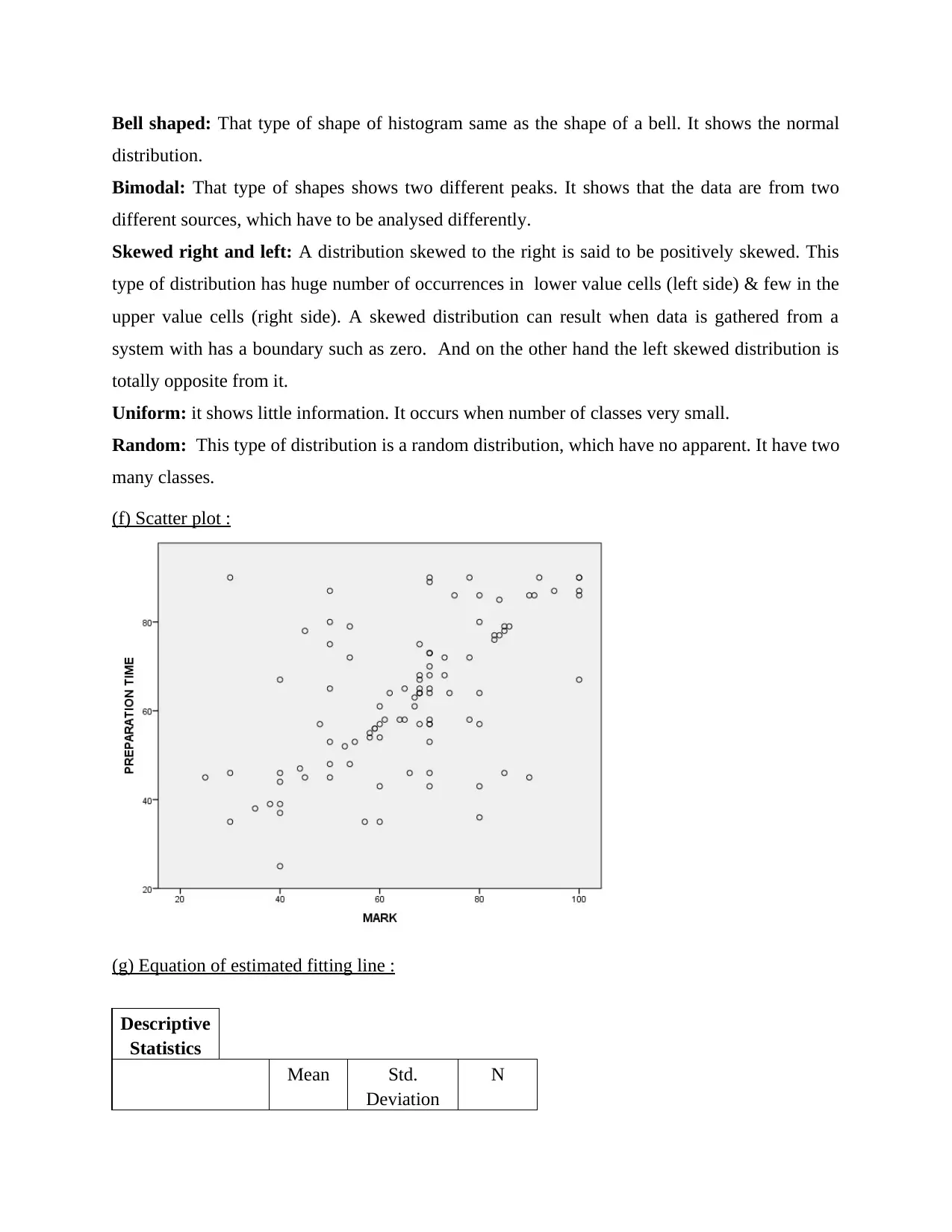
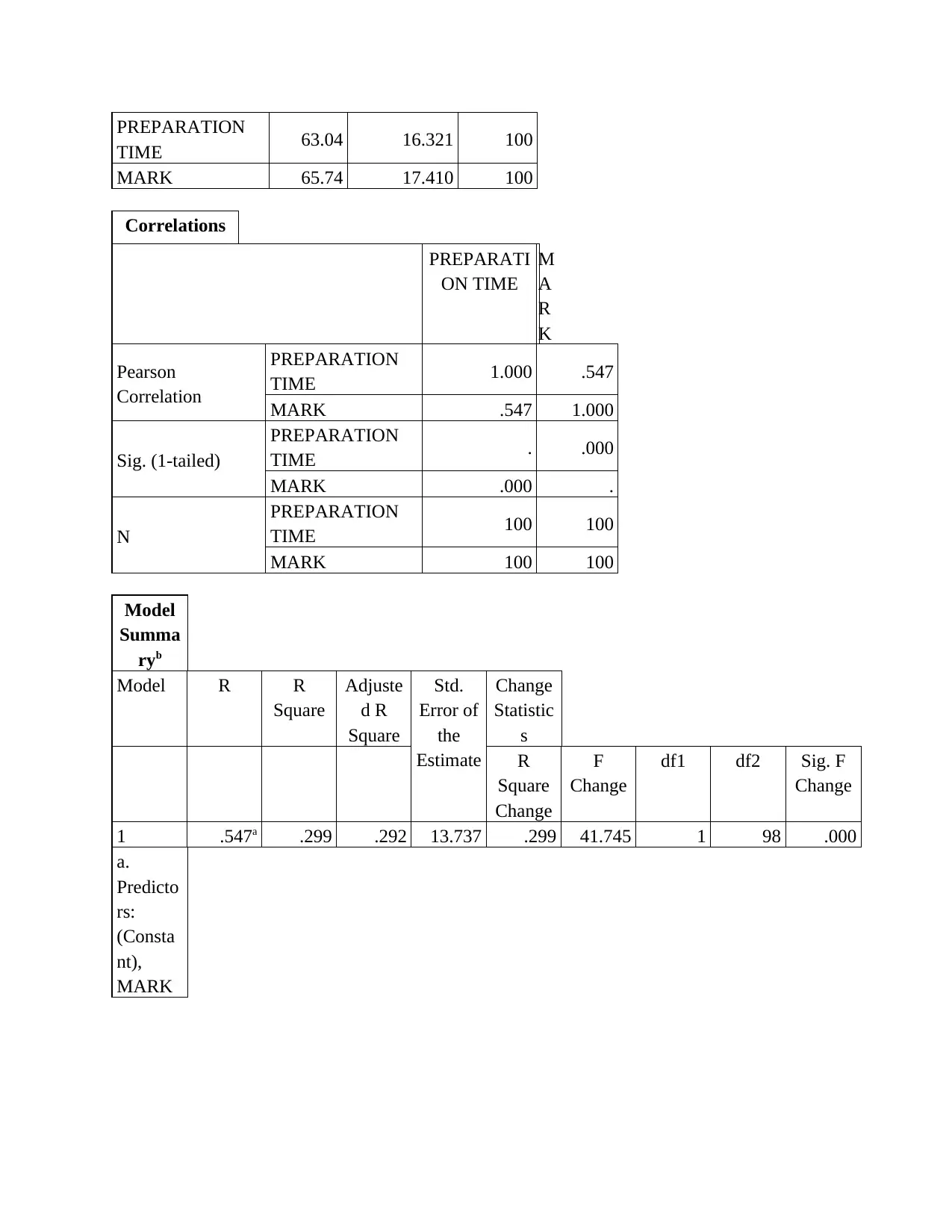
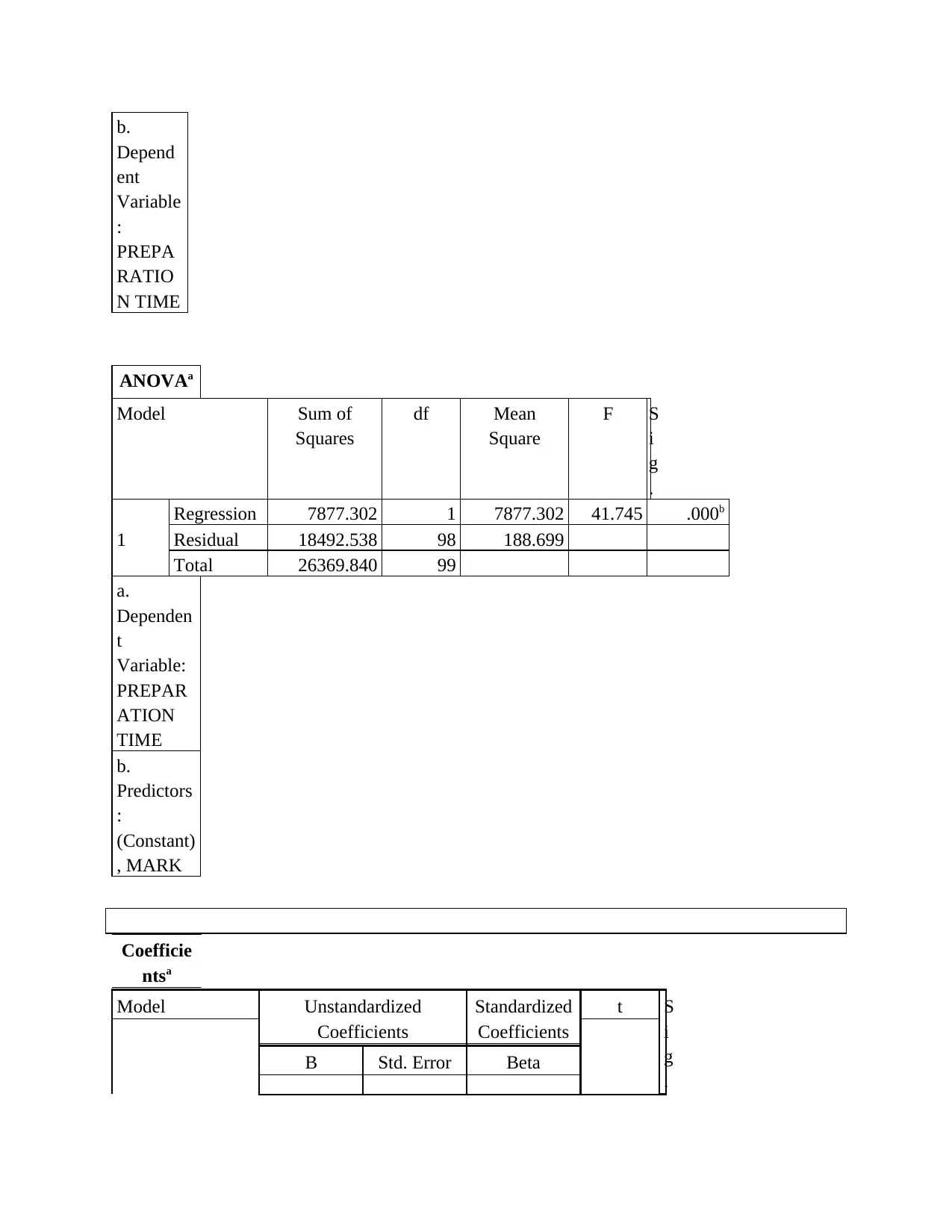
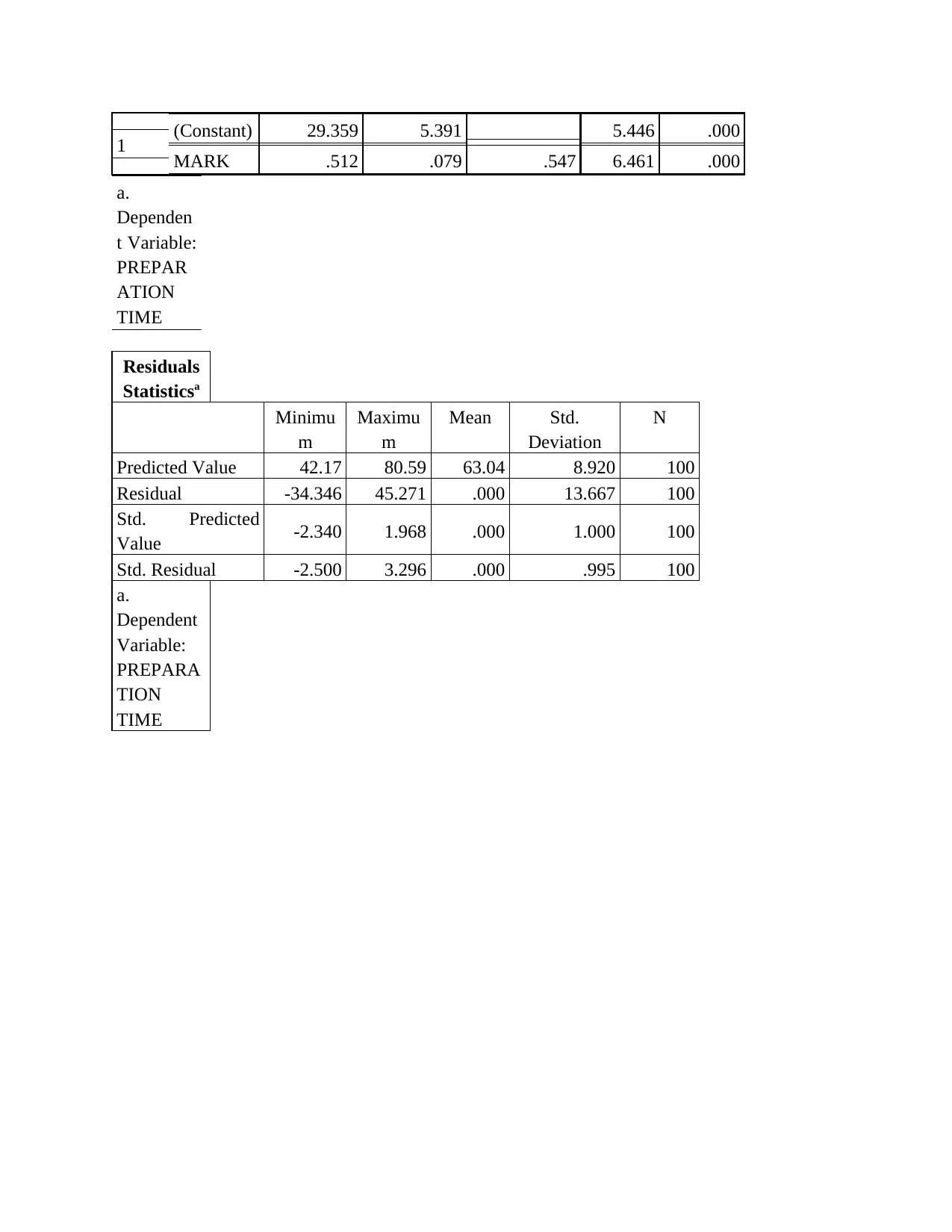
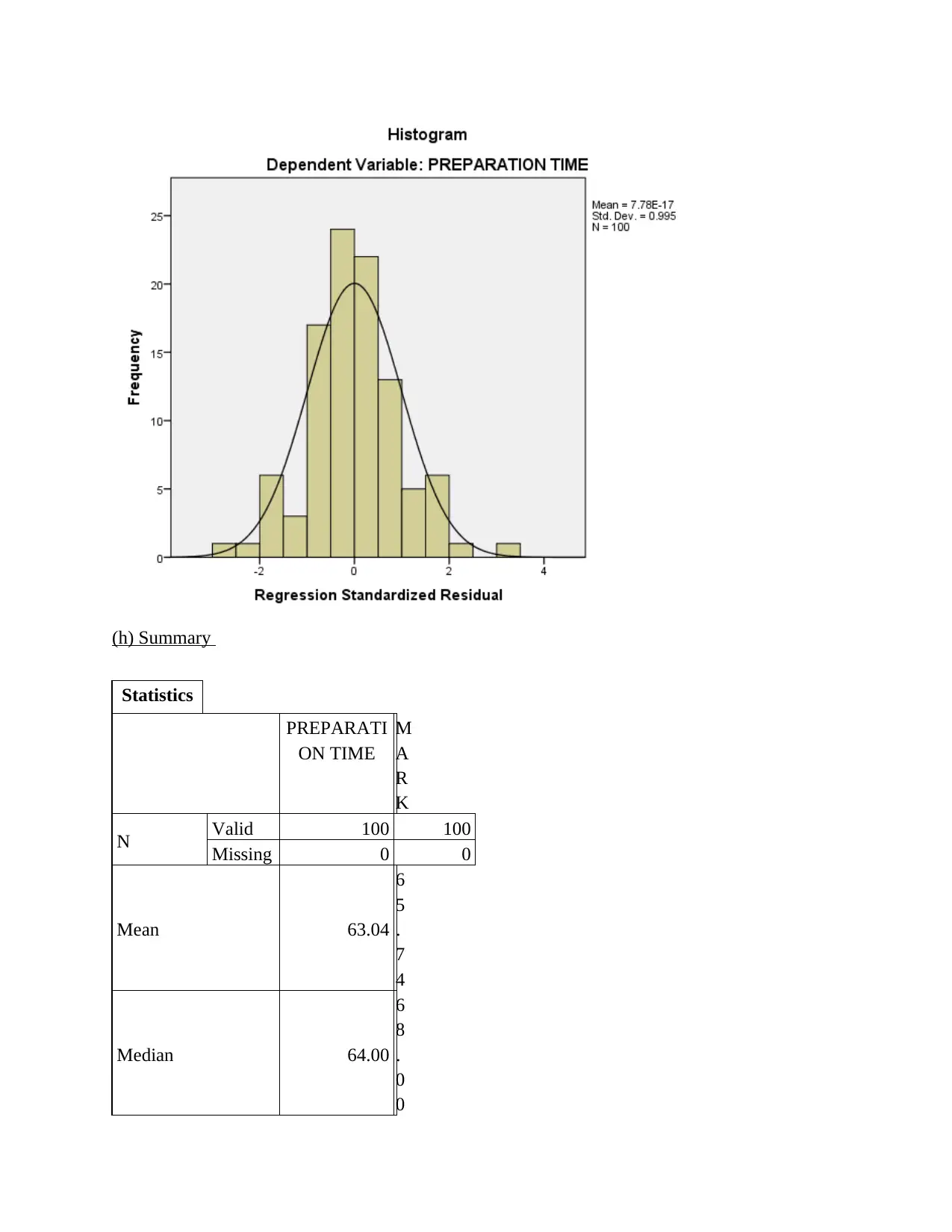
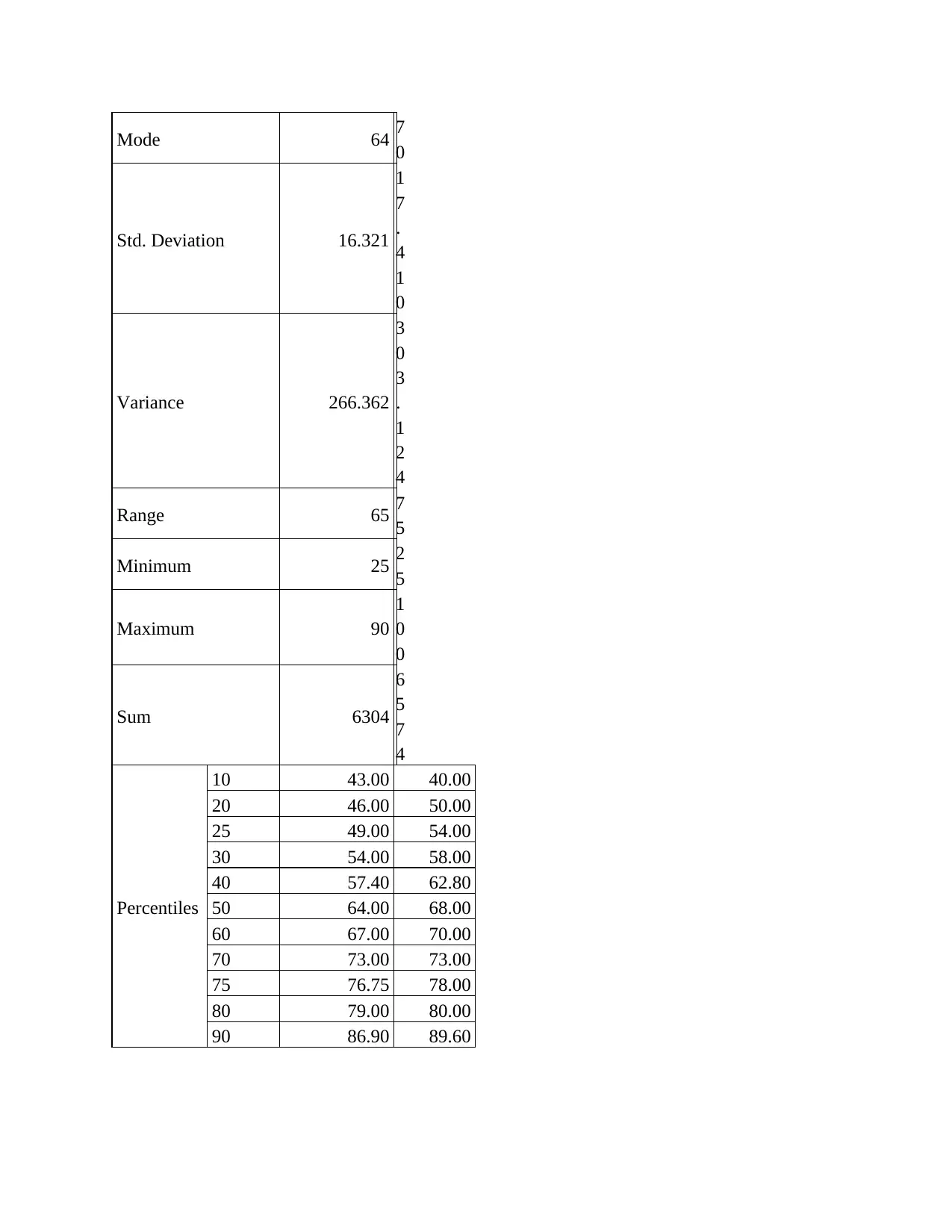
This statistics group project analyzes student performance data, focusing on the relationship between preparation time and marks. The project begins with an overview of survey methods and sampling techniques, specifically questionnaire-based surveys and probability sampling methods like random, stratified, and cluster sampling. It then identifies dependent and independent variables, determining data types, and addresses potential issues encountered during data collection, such as dishonesty and differences in interpretation. The project includes the creation and interpretation of frequency histograms and scatter plots to visualize the data. Regression analysis is performed to determine the equation of the estimated fitting line, and statistical measures like the correlation coefficient are used to quantify the strength and direction of the relationship between variables. The project concludes with an interpretation of the findings, highlighting the linear relationship between preparation time and student marks, along with standard error estimation and coefficient of determination analysis. Overall, the project provides a comprehensive statistical analysis of student data, including descriptive statistics, correlations, and regression modeling.




1 out of 17
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.