University Statistics: Exam 2 - Hypothesis Testing Solutions
VerifiedAdded on 2022/09/23
|11
|1676
|32
Homework Assignment
AI Summary
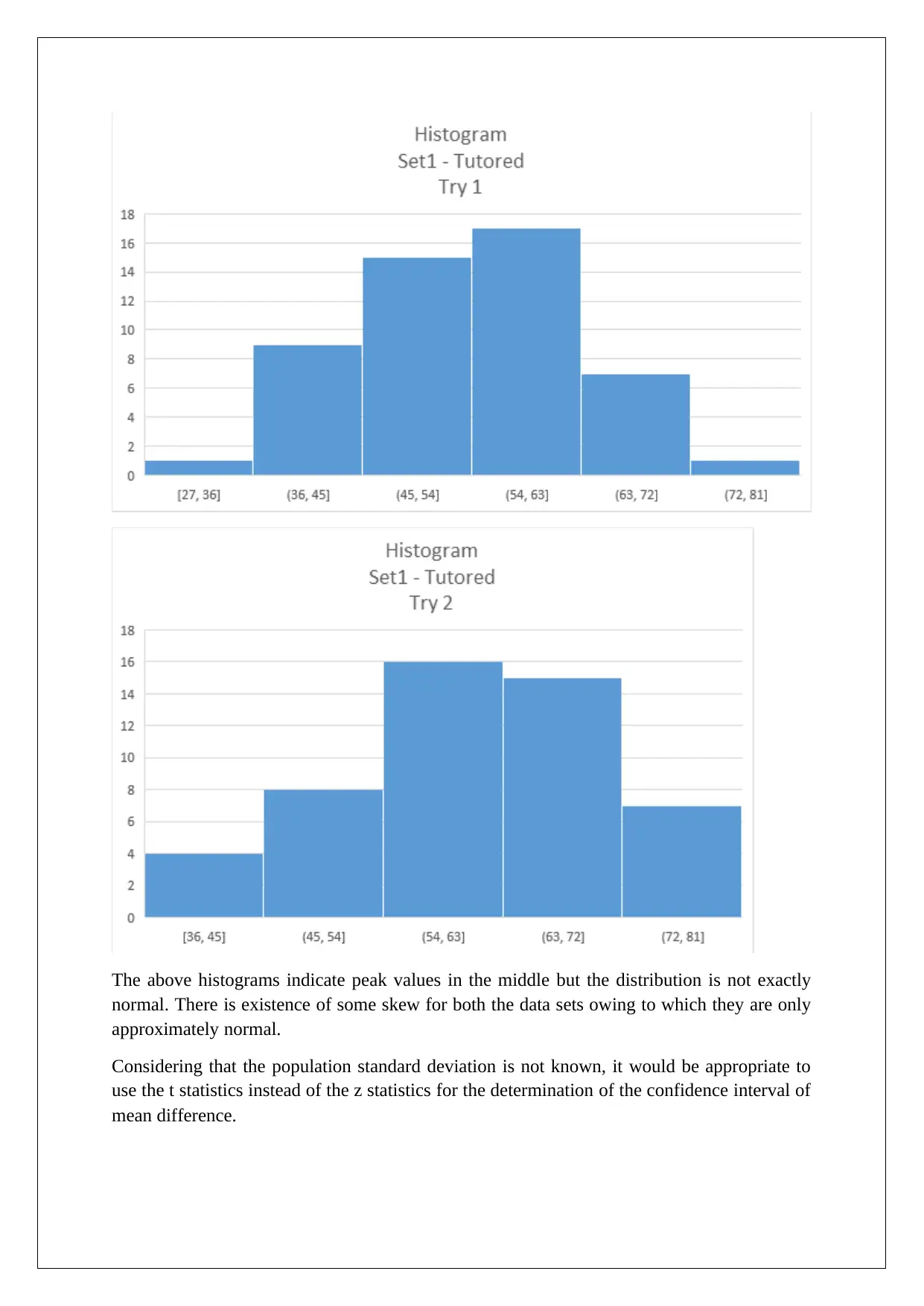
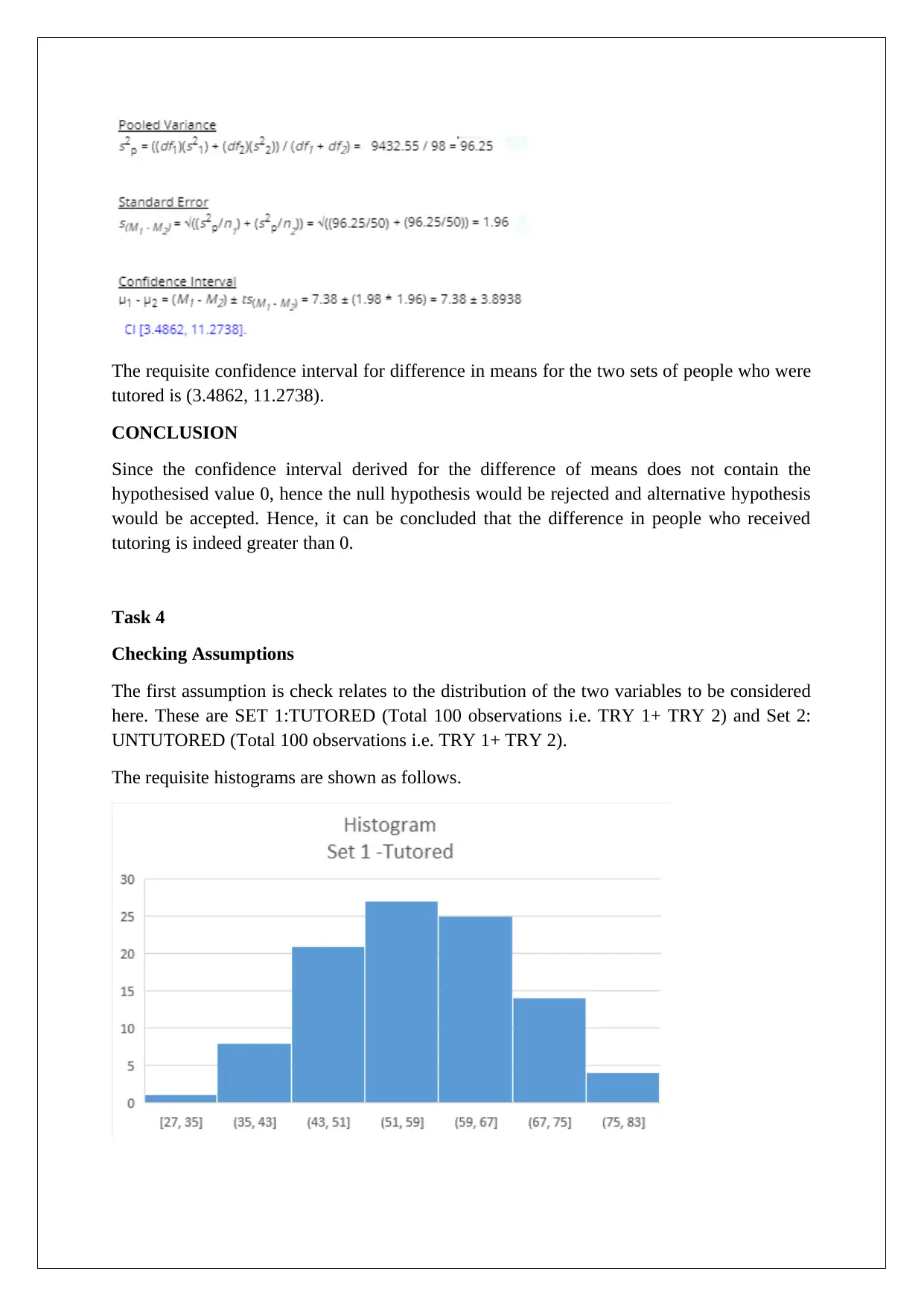
This document presents a comprehensive solution to a statistics exam, addressing five distinct tasks. Task 1 focuses on checking assumptions for a one-sample z-test, performing hypothesis testing, and constructing a 95% confidence interval to determine if the mean stem length of roses differs from 11. Task 2 involves a binomial distribution analysis, checking for normality, performing hypothesis testing using a z-test, and constructing a confidence interval to assess whether more than 80% of the population likes dogs. Tasks 3 and 4 compare two sets of data, employing t-tests and confidence intervals to evaluate the impact of tutoring on performance, considering both tutored and untutored groups. Finally, Task 5 interprets statistical parameters (mean, variance, sample size) and discusses the difference between the distribution of a variable and the distribution of its mean. The solutions include detailed explanations, Excel computations, and conclusions based on p-values and confidence intervals.









1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.