Statistics Assignment: Analyzing GDP and Sample Means Data
VerifiedAdded on 2020/05/03
|4
|475
|156
Homework Assignment
AI Summary
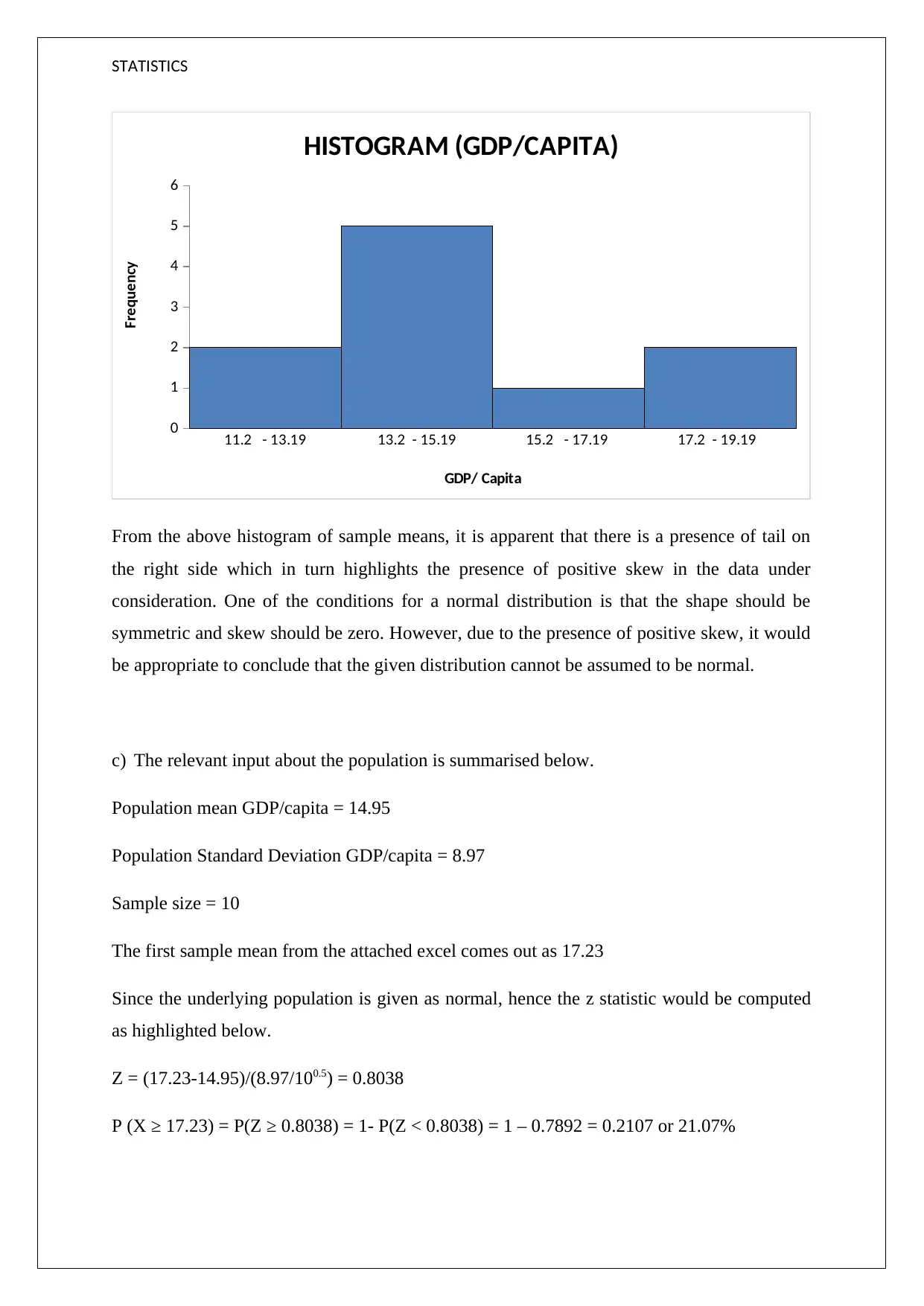
This statistics assignment analyzes GDP data, focusing on sample means, standard deviations, and the characteristics of the distribution. The assignment computes the sample mean, population mean, and population standard deviation. It also calculates the z-statistic to determine the probability of the population mean being at least equal to or greater than the sample mean. The solution highlights the presence of positive skew in the data, indicating that the distribution cannot be assumed to be normal. The assignment emphasizes statistical concepts like normal distribution, skewness, and probability calculations, providing a comprehensive analysis of the GDP data through various statistical measures and tests. The solution also includes a histogram of sample means to visualize the distribution of the data.



1 out of 4
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.