Holmes Institute HI6007 Statistics Group Assignment: Data Analysis
VerifiedAdded on 2023/04/26
|10
|2333
|347
Homework Assignment
AI Summary
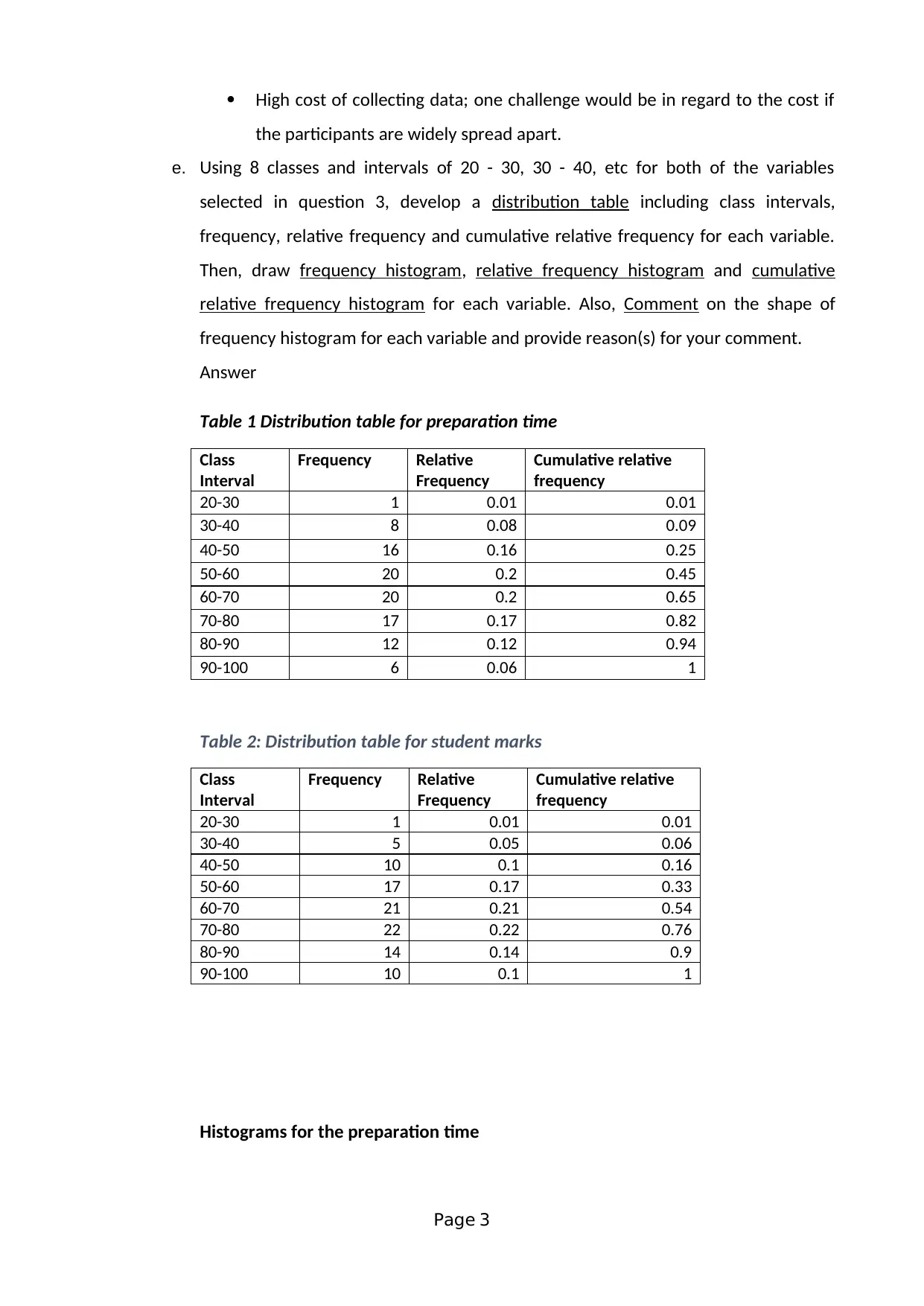
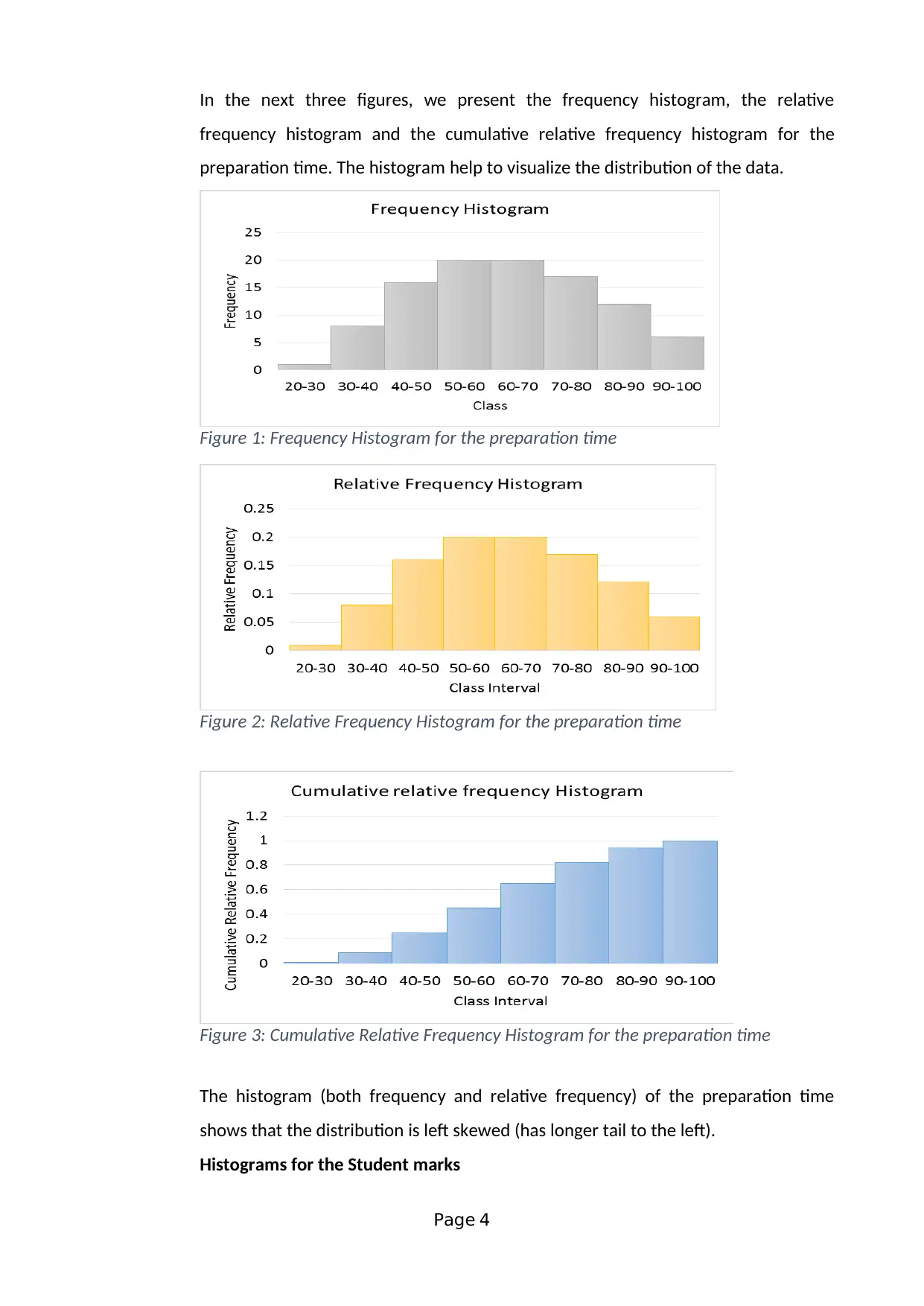
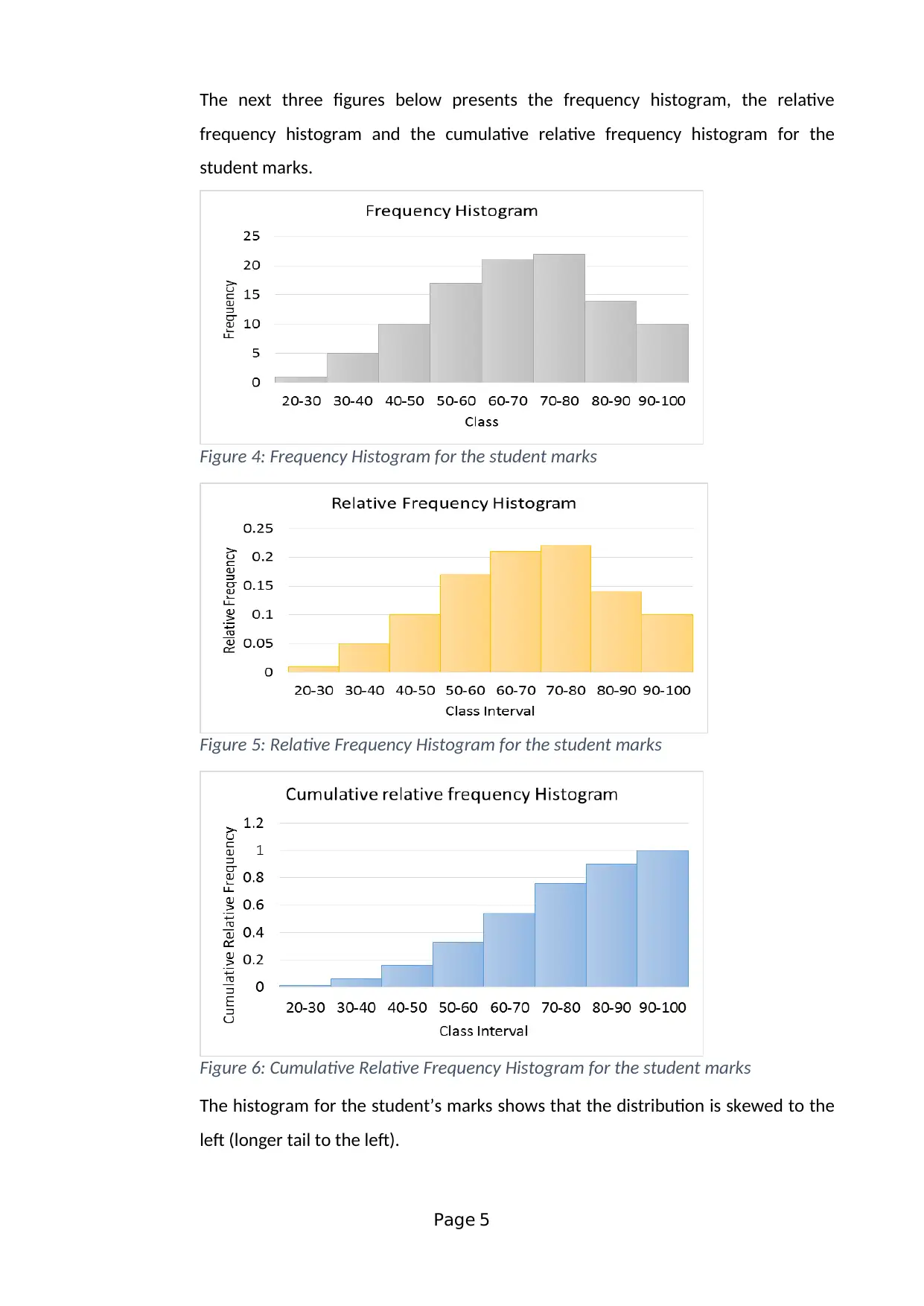
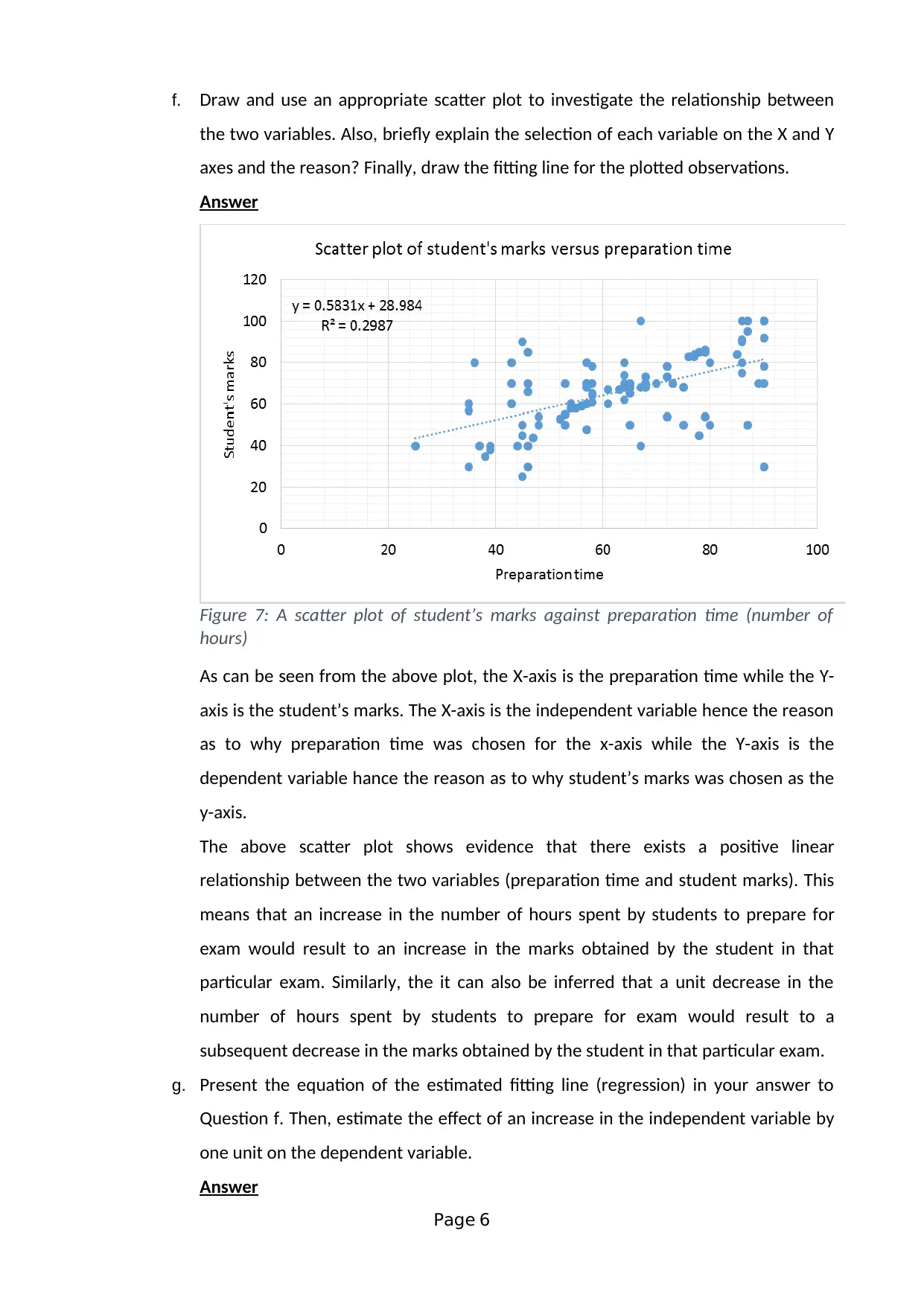
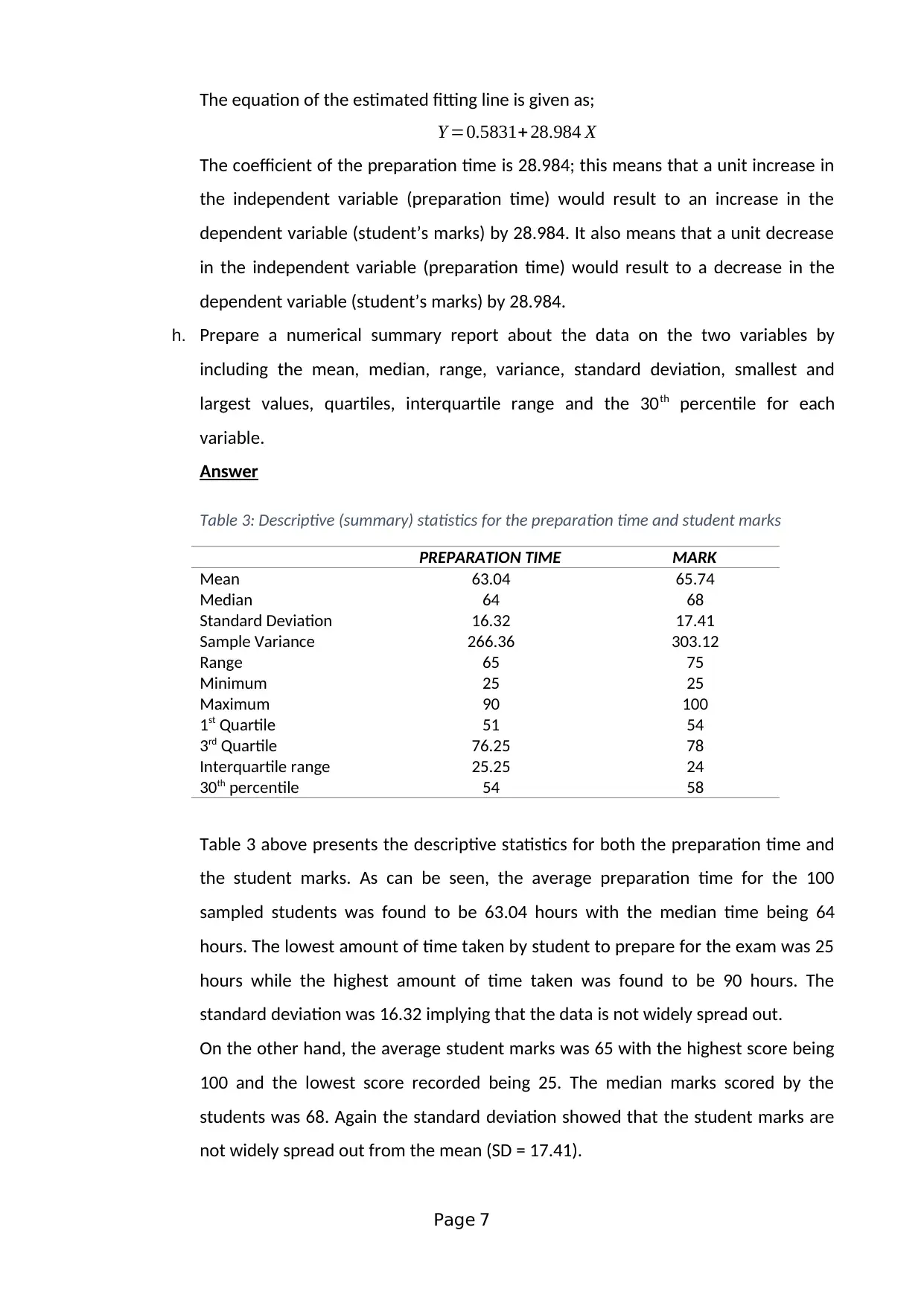
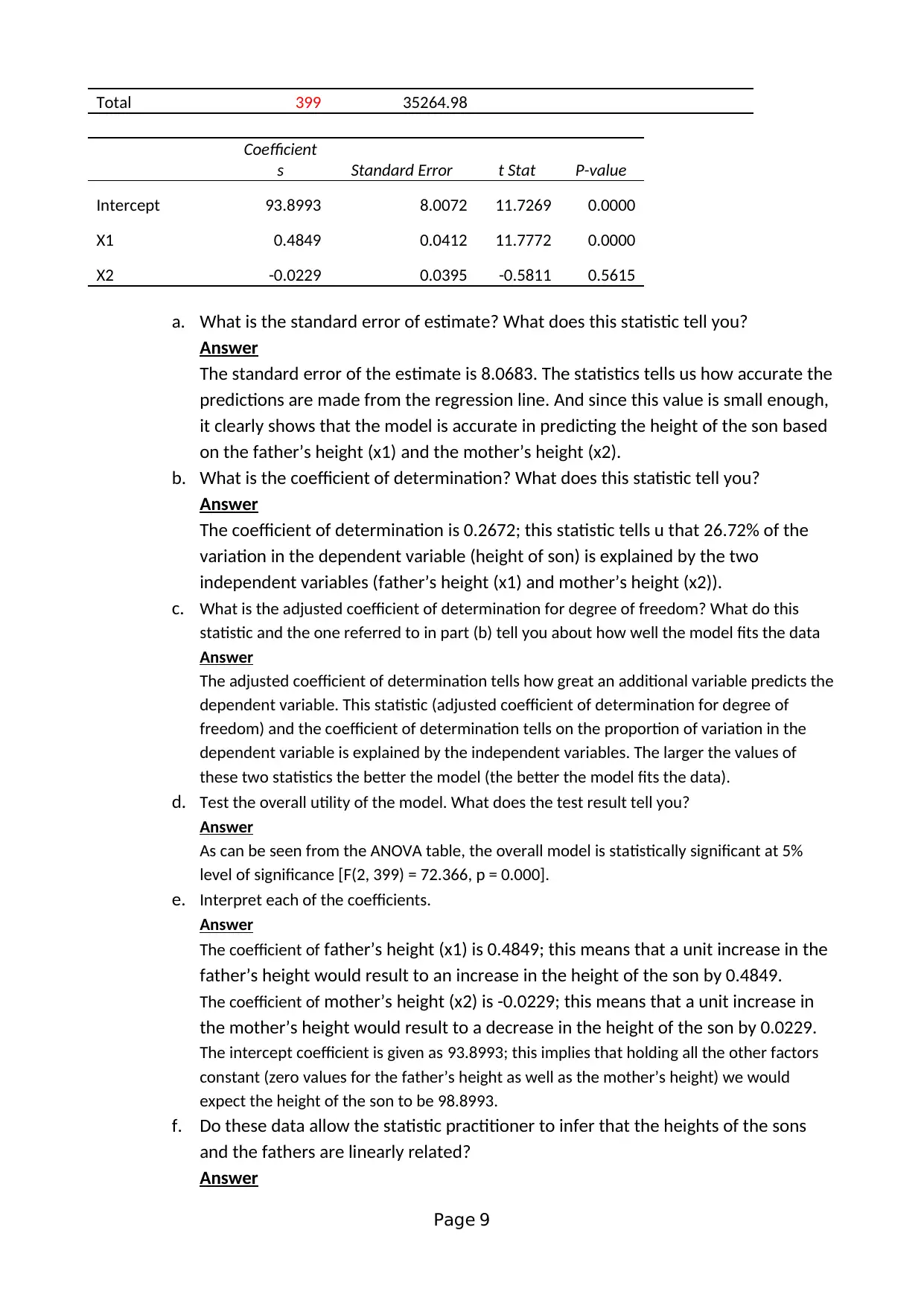
This assignment solution addresses a statistics group assignment (HI6007) from Holmes Institute, focusing on analyzing the relationship between students' preparation time for an exam and their marks. The solution employs a cross-sectional survey method and simple random sampling to collect data from 100 students. It identifies dependent and independent variables, discusses potential data collection issues, and develops frequency distributions with histograms to visualize data patterns. The assignment utilizes scatter plots and regression analysis to investigate the relationship between variables, providing the regression equation and interpreting coefficients. Furthermore, it presents a descriptive statistical summary, including mean, median, standard deviation, and correlation coefficients. The second part of the assignment involves multiple regression analysis, interpreting the output to determine relationships between son's height and parents' heights, including the standard error, coefficient of determination, and model utility.




1 out of 10
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.