Statistics Assignment - Data Analysis, Hypothesis, and CI
VerifiedAdded on 2022/07/28
|9
|1072
|37
Homework Assignment
AI Summary
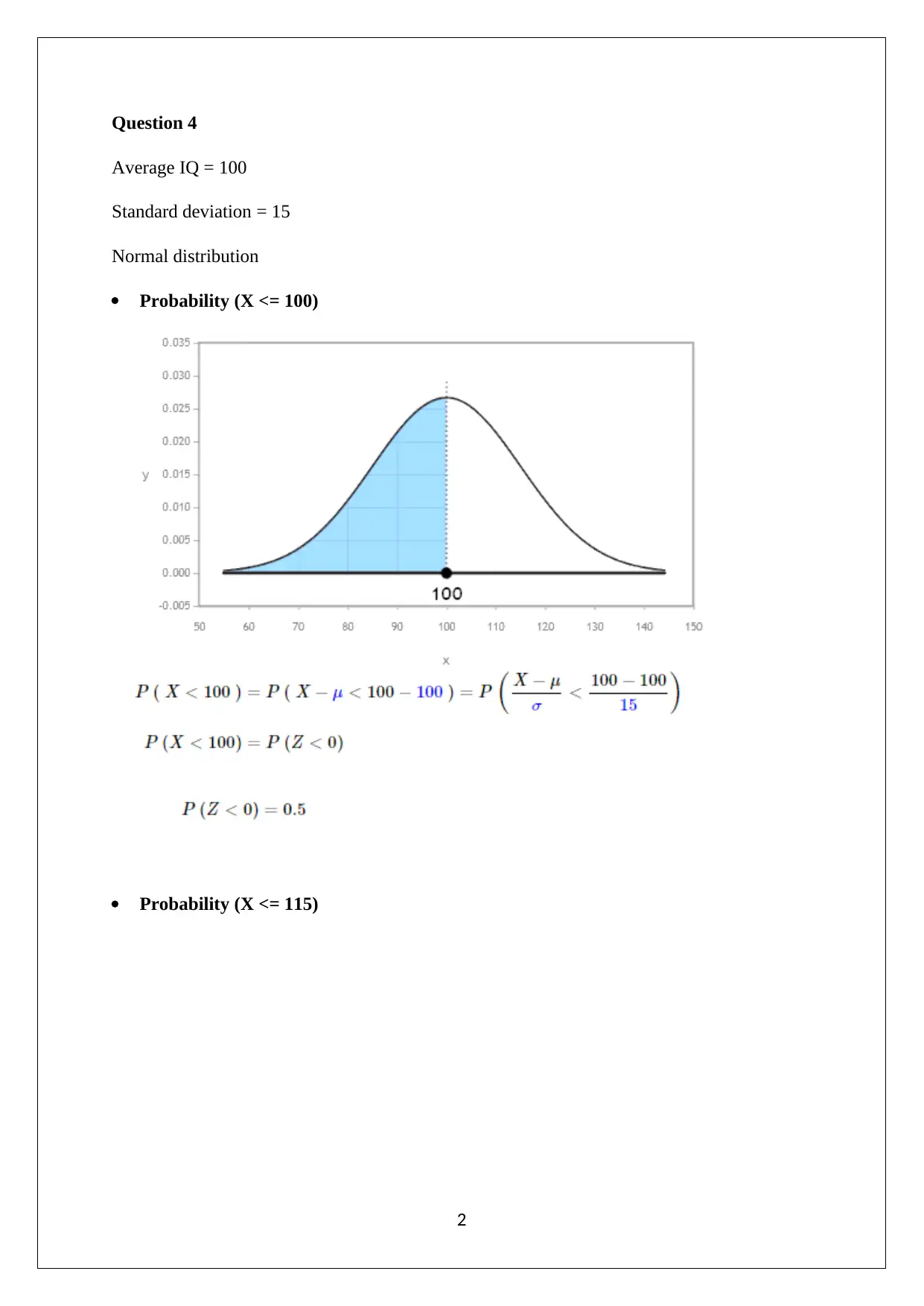
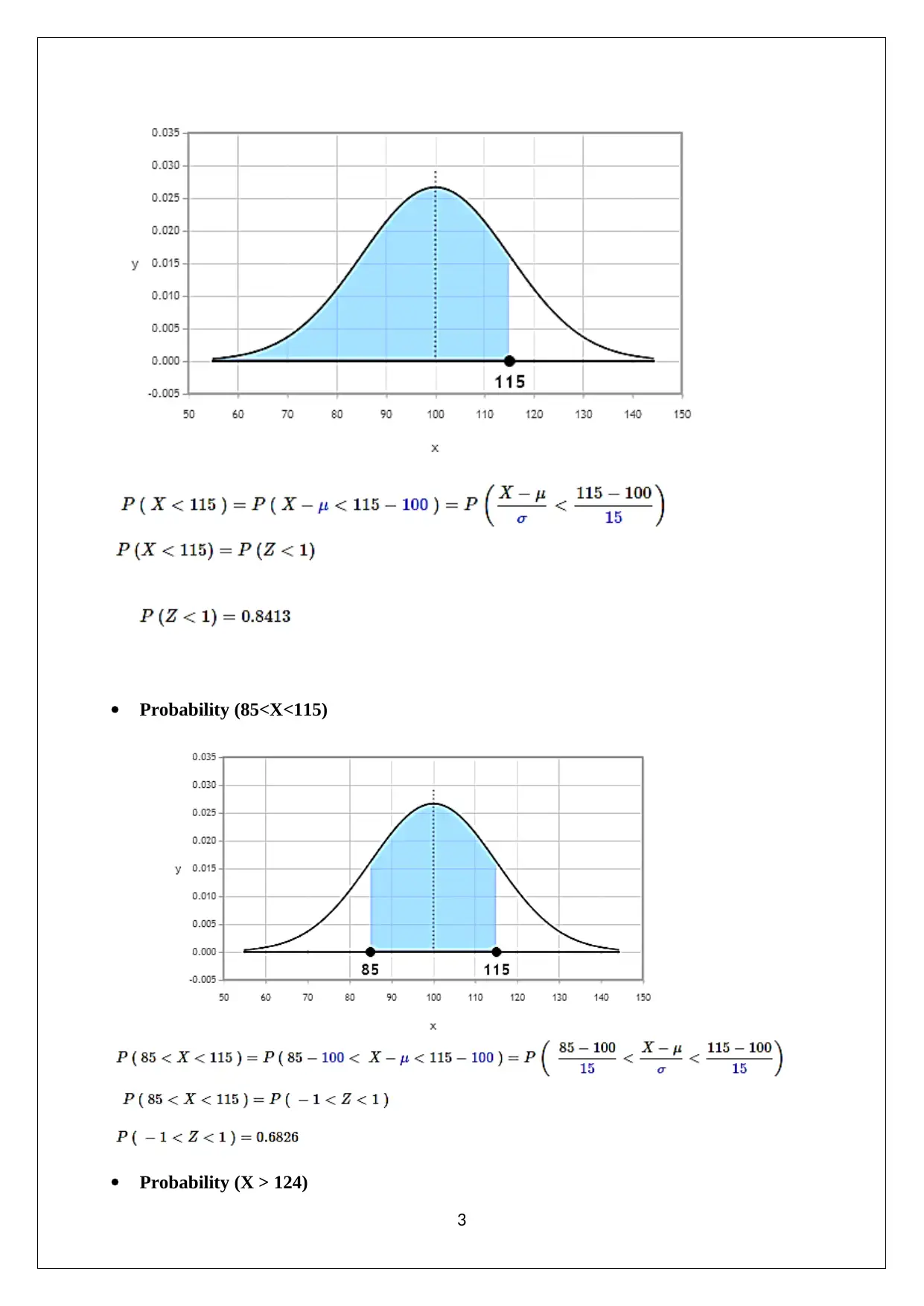
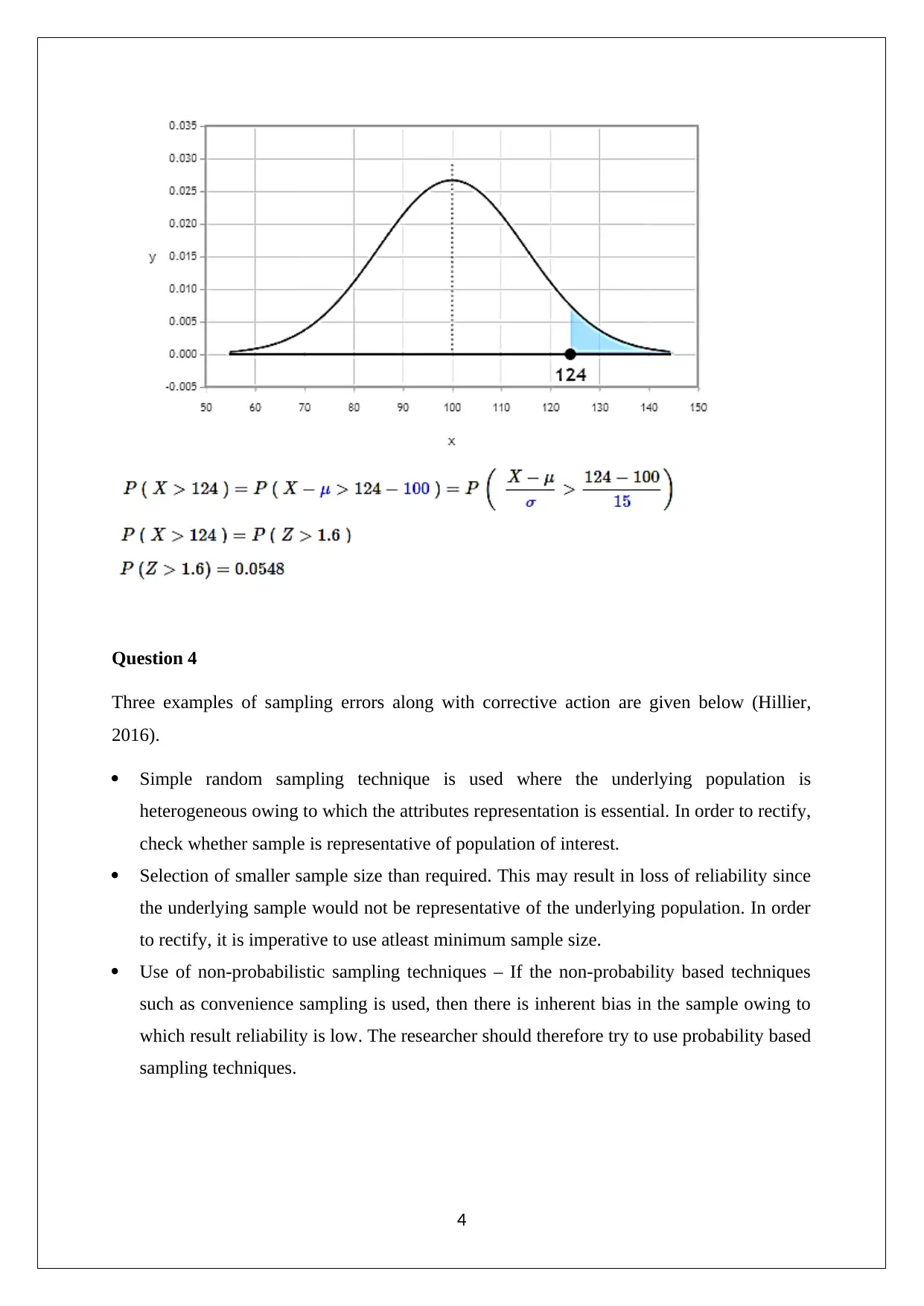
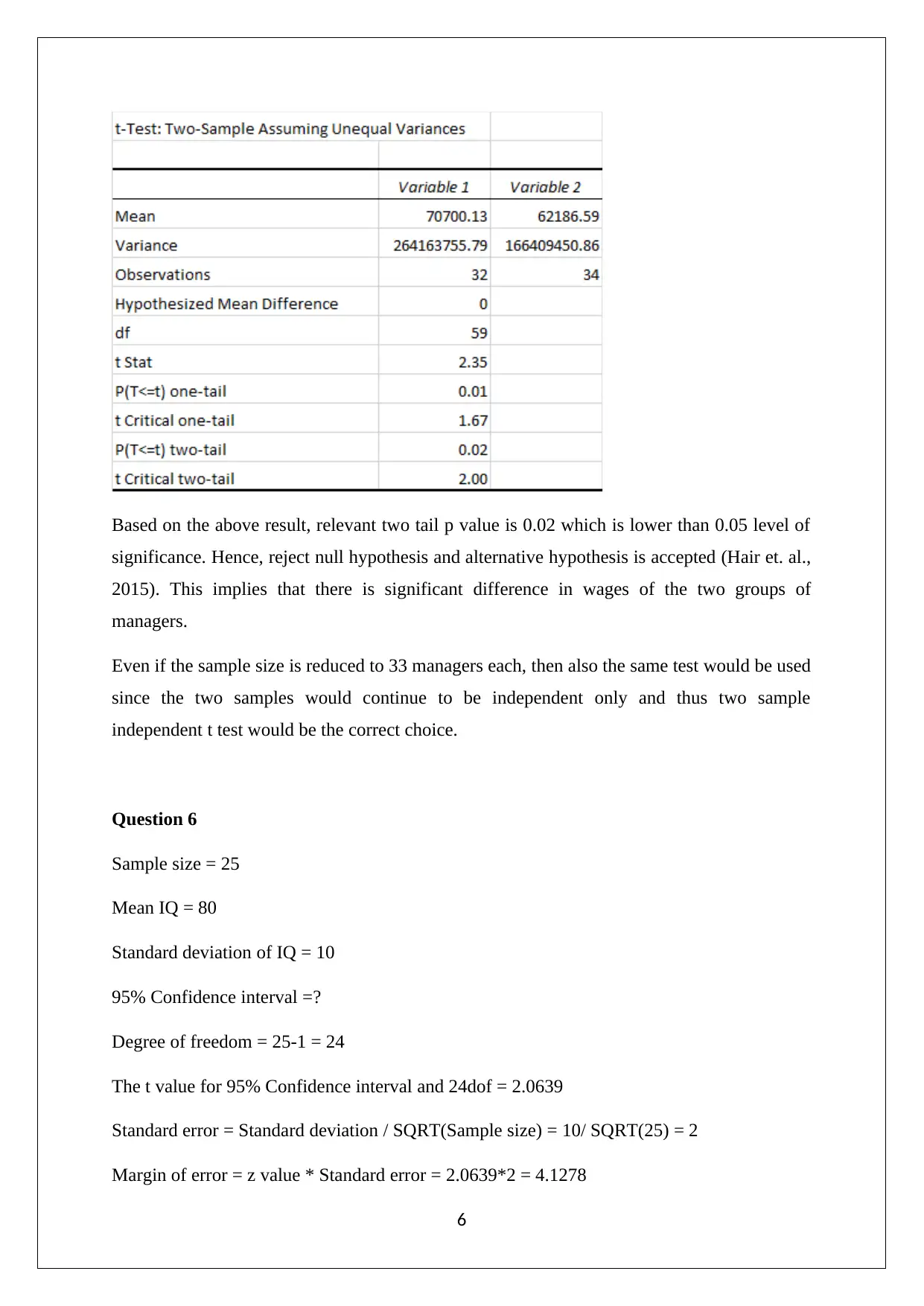
This document presents a comprehensive solution to a statistics assignment, addressing key concepts and methodologies. The solution begins with a numerical summary of a given dataset, including calculations of mean, median, mode, and skewness to assess data distribution. It then explores probability using the binomial distribution, calculating the probability of selecting female students. The assignment proceeds to analyze normal distributions and calculate probabilities associated with IQ scores, incorporating standard deviation and the concept of sampling errors. The solution also differentiates between sampling and non-sampling errors, providing examples and corrective actions for each. Hypothesis testing is demonstrated using a two-sample independent t-test, with interpretation of results and implications for different sample sizes. Finally, the assignment concludes with the calculation of confidence intervals for the mean IQ, considering varying sample sizes and explaining the impact on interval width. The solution references key statistical concepts and provides detailed explanations to aid in understanding. The assignment is a valuable resource for students looking to improve their understanding of statistical principles and problem-solving skills.





1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.