Statistics Homework: Analyzing Household Expenditure Data with Excel
VerifiedAdded on 2023/05/05
|7
|1646
|371
Homework Assignment
AI Summary
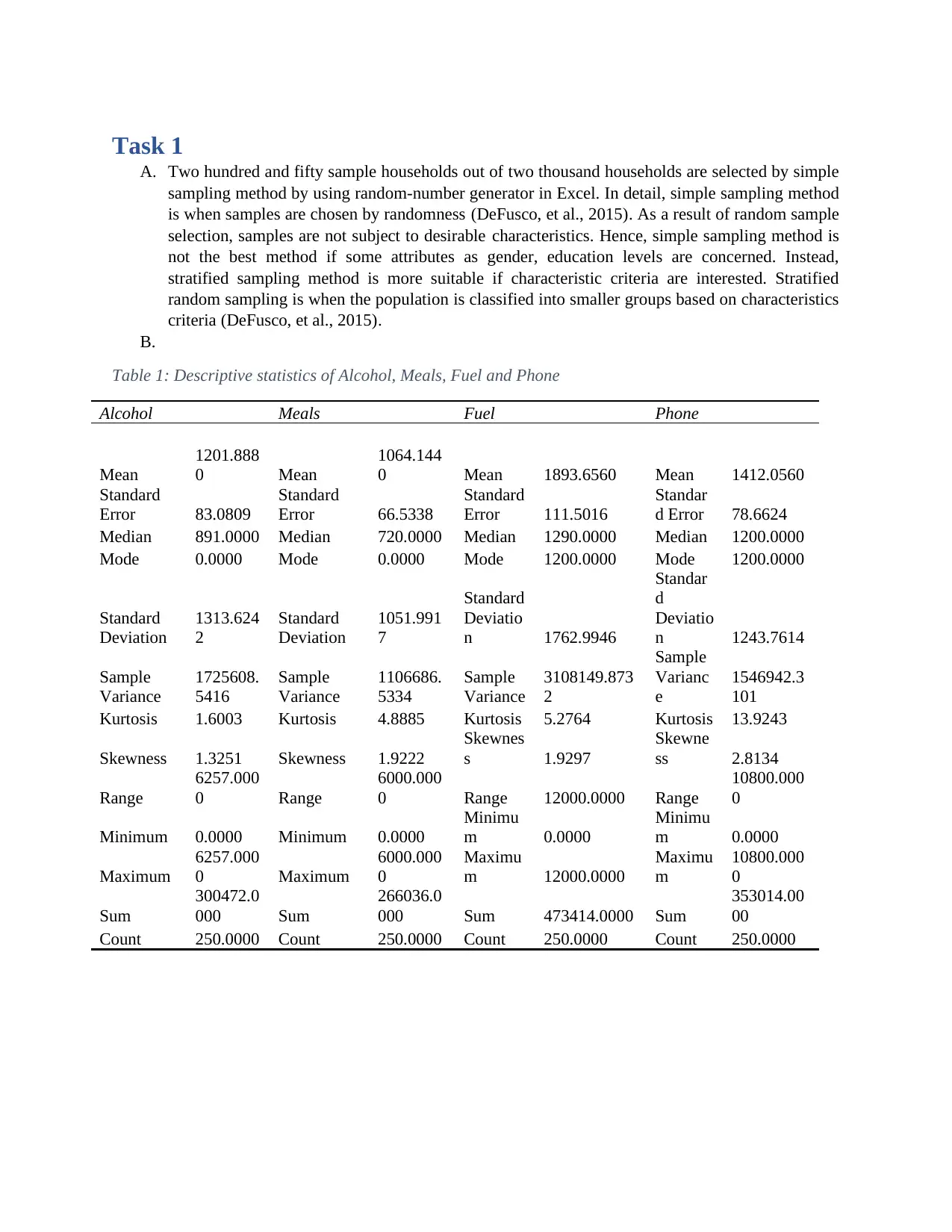
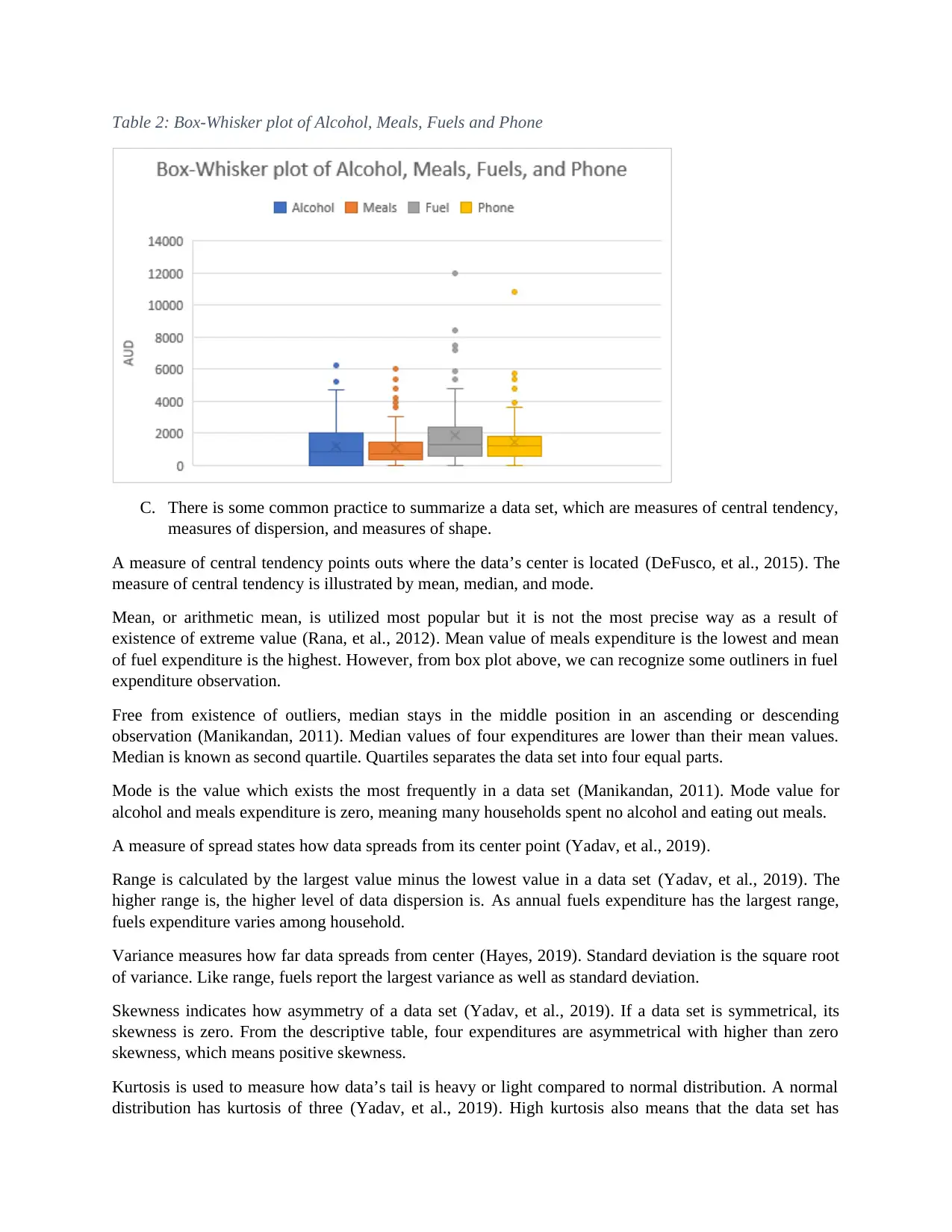
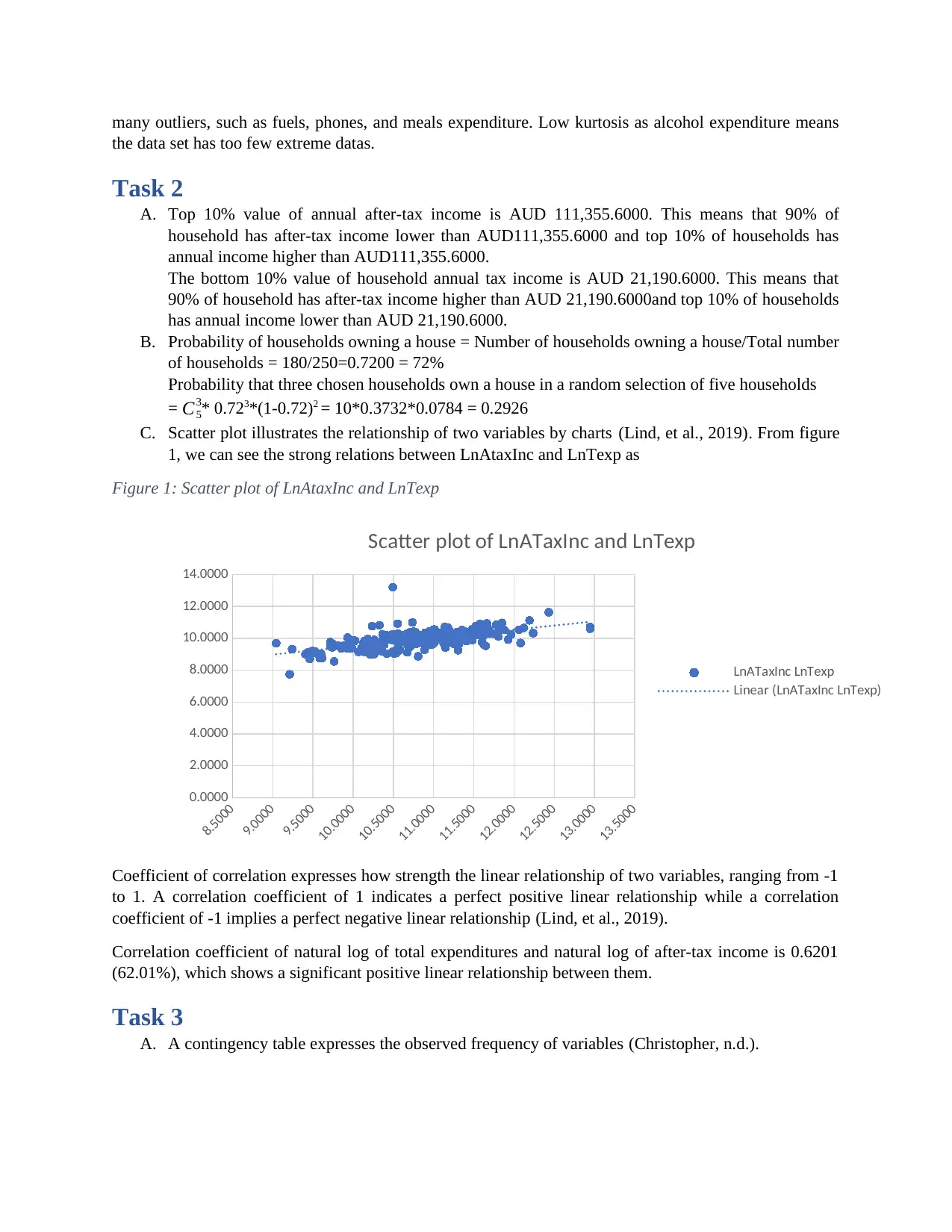
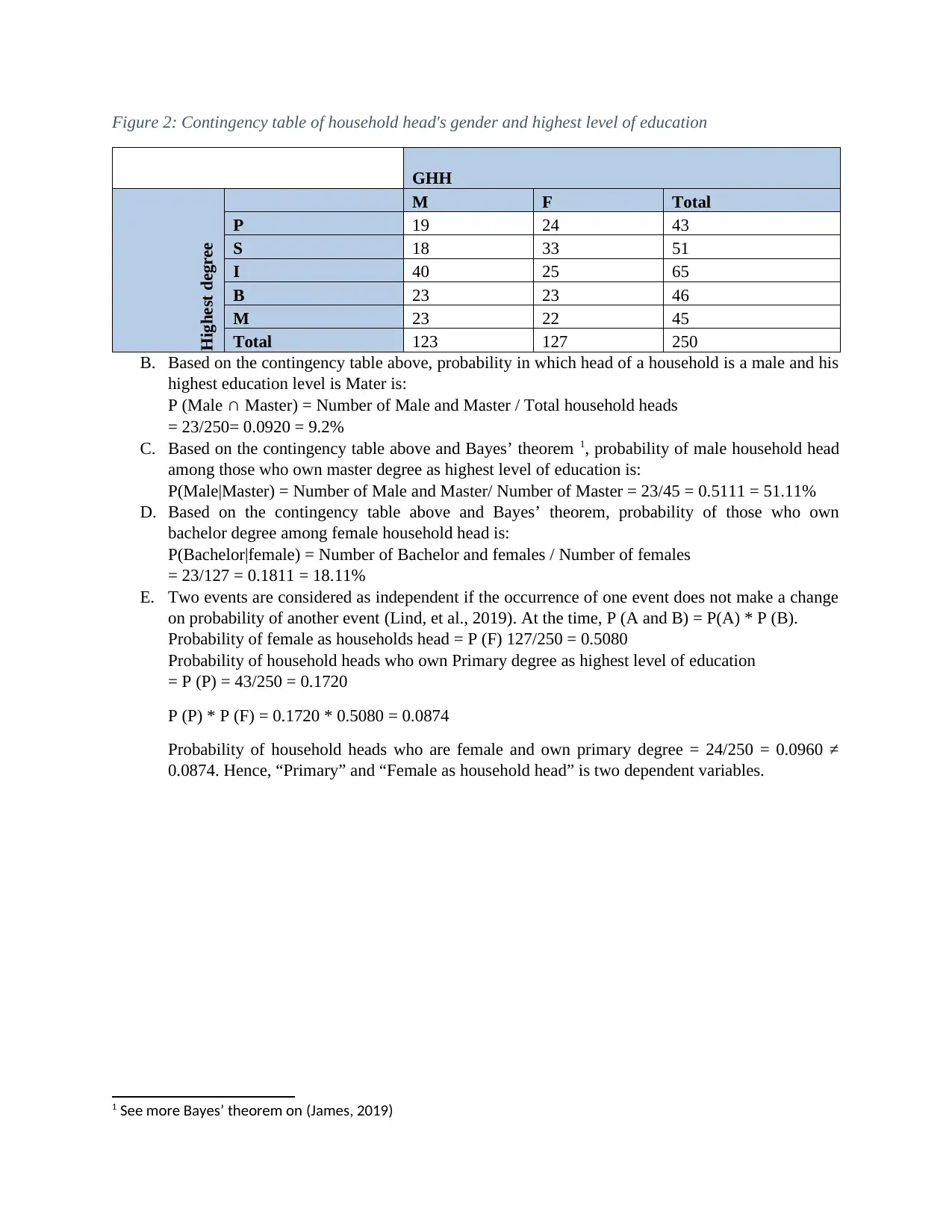
This assignment provides a comprehensive statistical analysis of household expenditure data. It begins with a simple random sampling of 250 households from a larger dataset to analyze expenditures on alcohol, meals, fuel, and phone services. Descriptive statistics, including mean, median, mode, standard deviation, skewness, and kurtosis, are calculated and interpreted to understand the central tendency, dispersion, and shape of the data. The assignment also determines the top and bottom 10% values of after-tax income, calculates the probability of households owning a house, and examines the relationship between after-tax income and total expenditure using scatter plots and correlation coefficients. Finally, it uses a contingency table to analyze the relationship between household head gender and education level, calculating conditional probabilities and determining the independence of variables using Bayes’ theorem. The analysis is supported by tables and figures generated using Excel.



1 out of 7
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.