HI6007 Statistics Assignment: Analyzing Business Data and Regression
VerifiedAdded on 2020/04/07
|13
|2221
|265
Homework Assignment
AI Summary
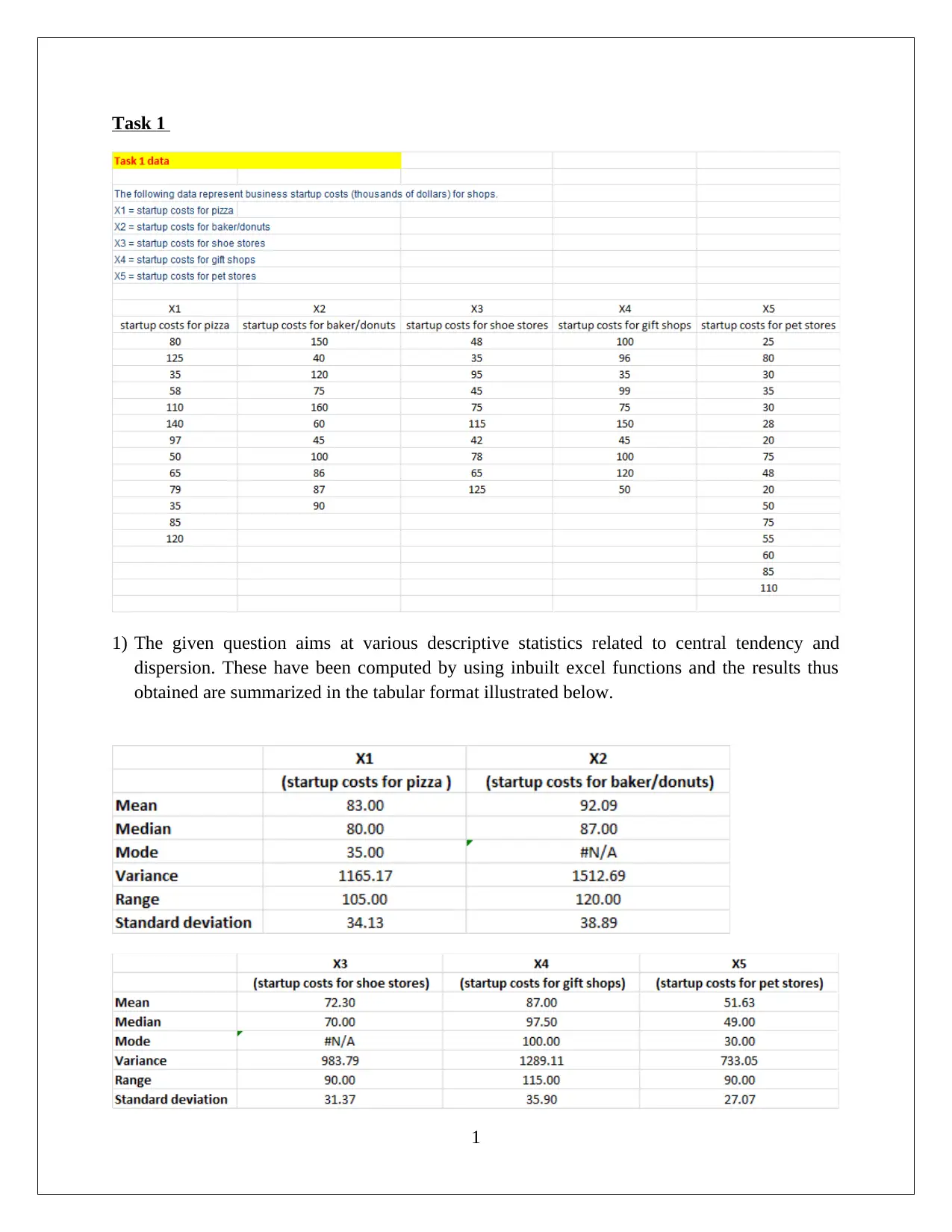
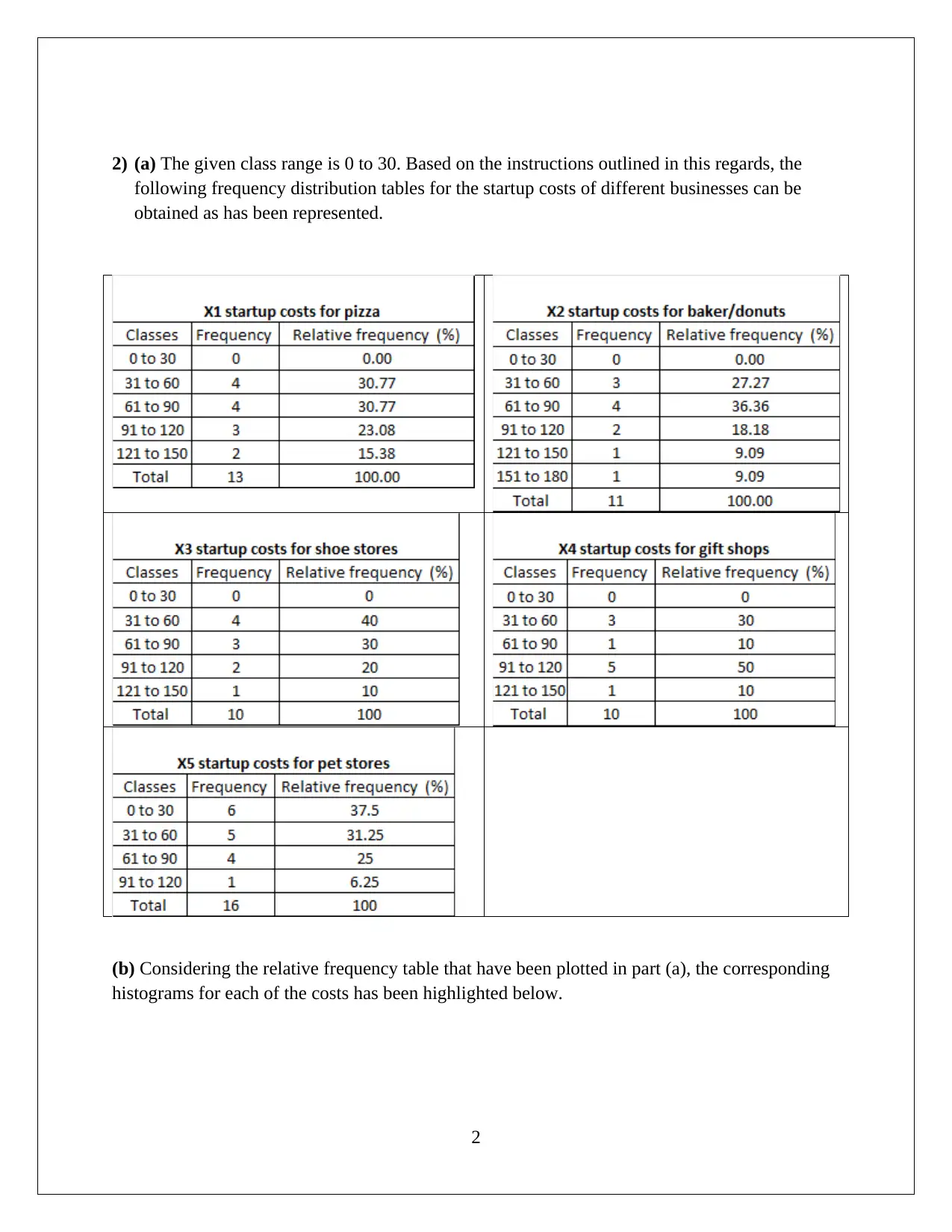
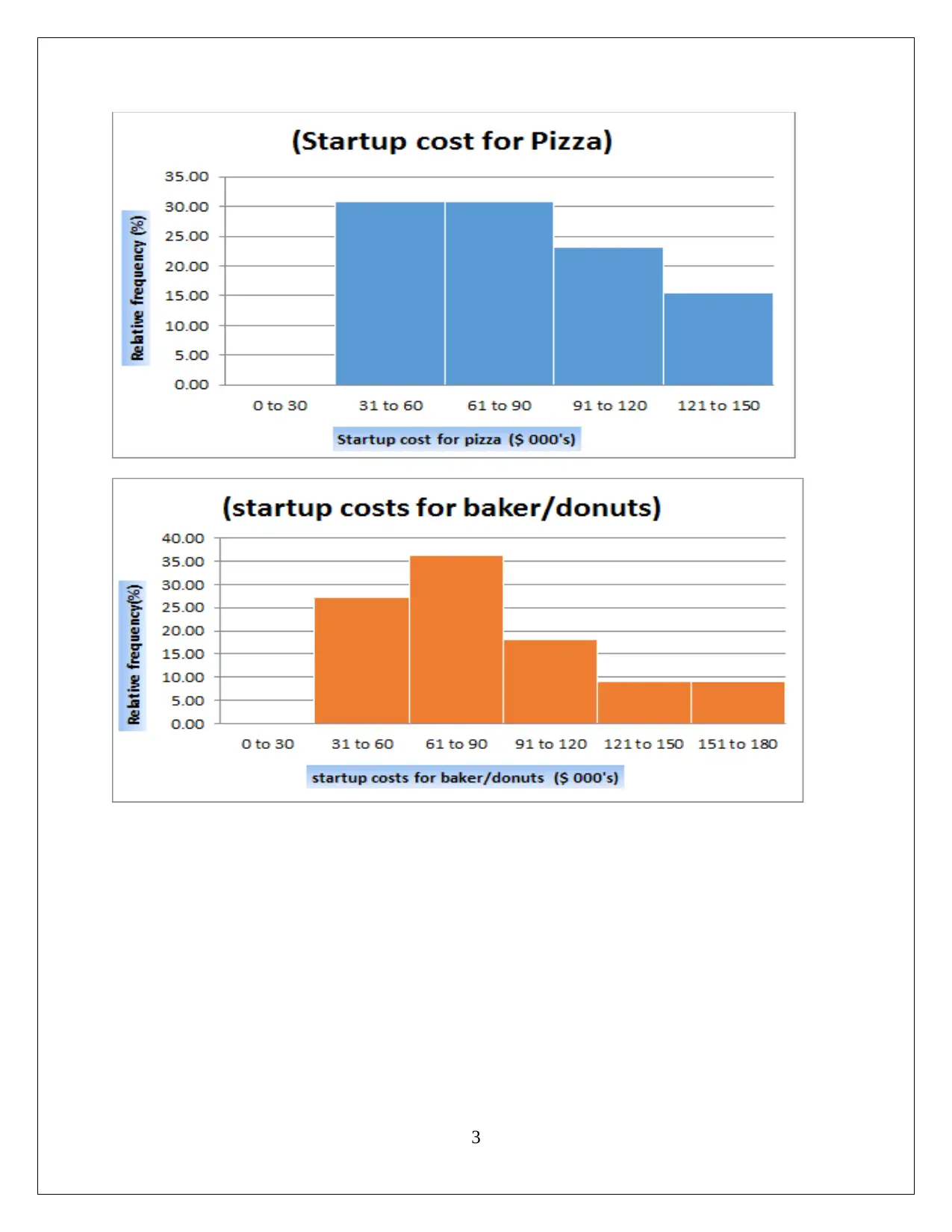
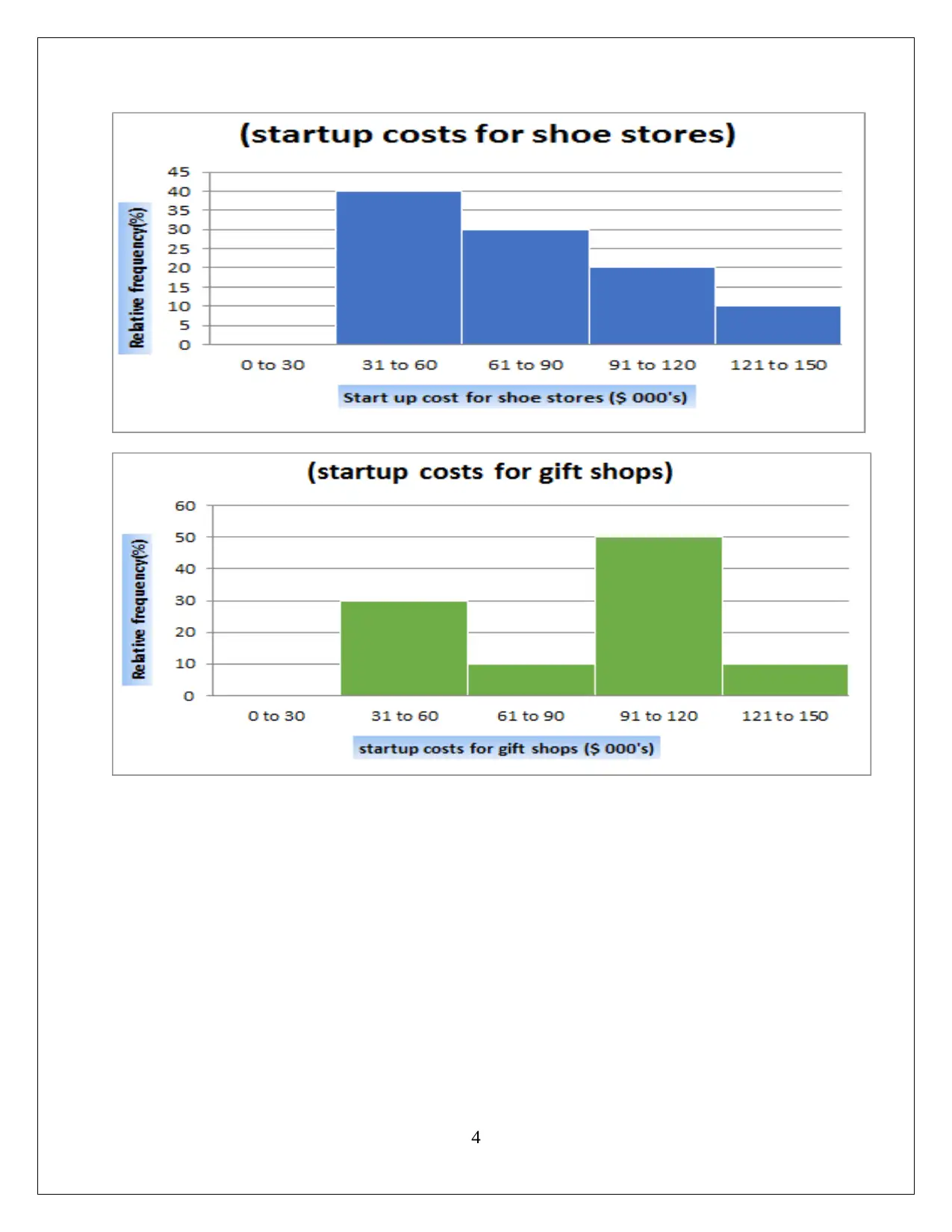
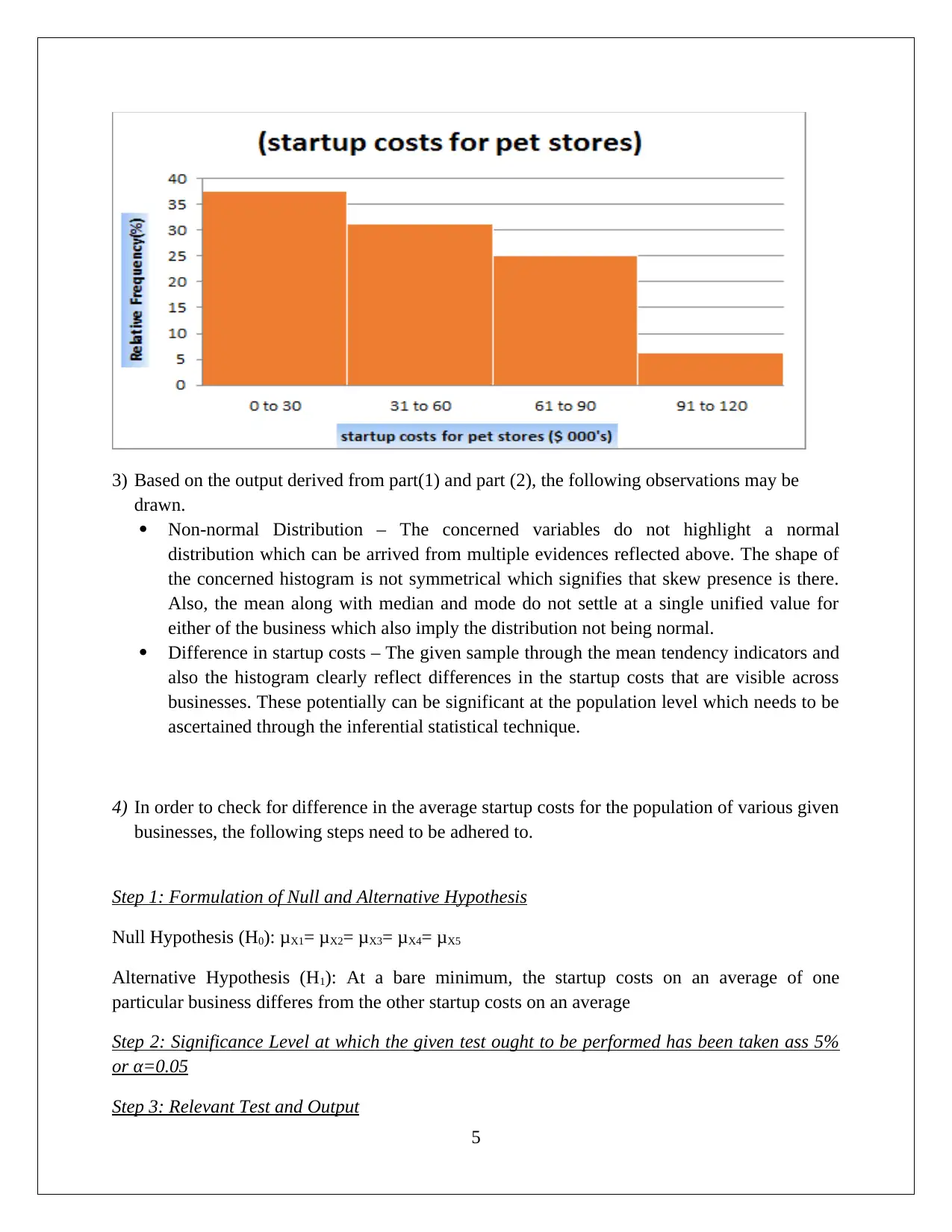
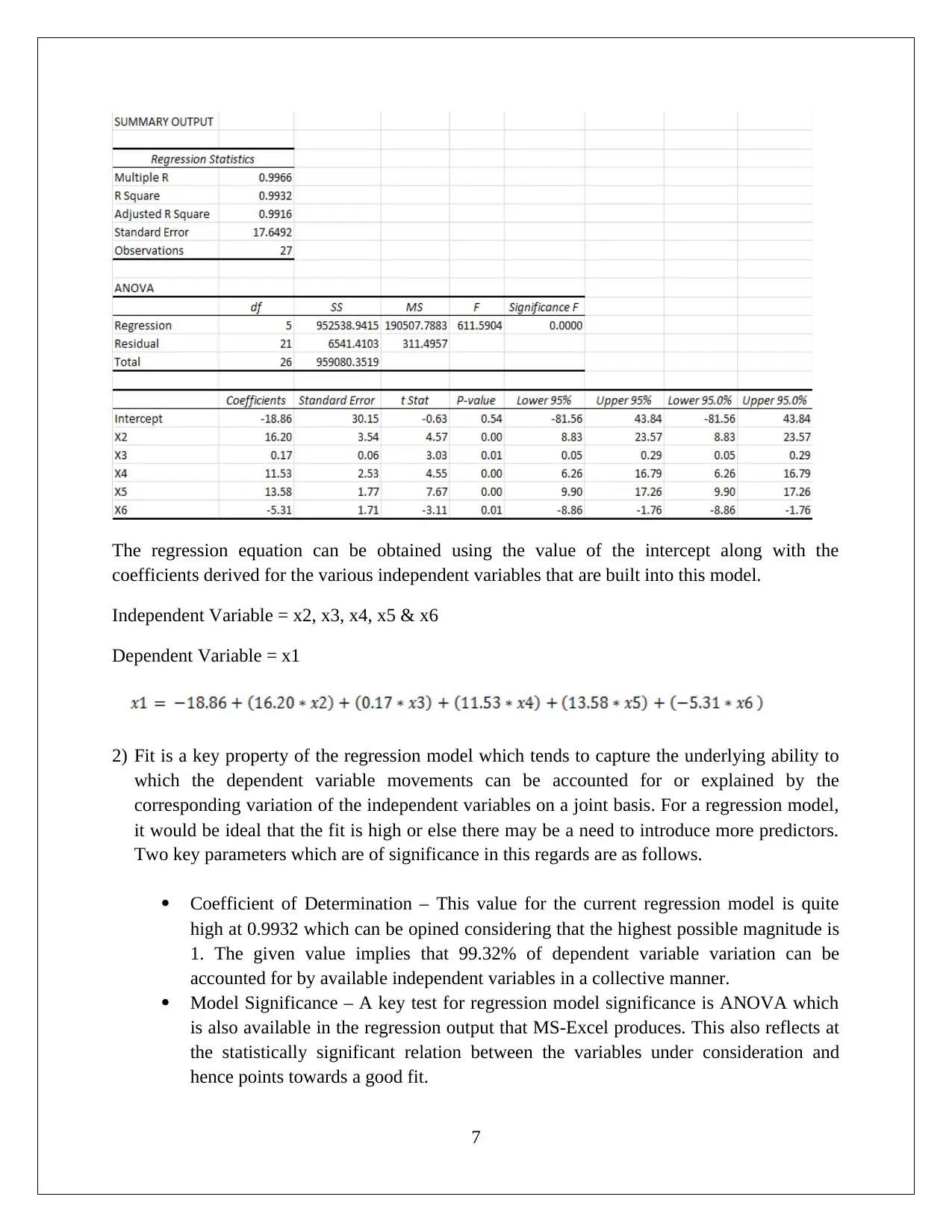
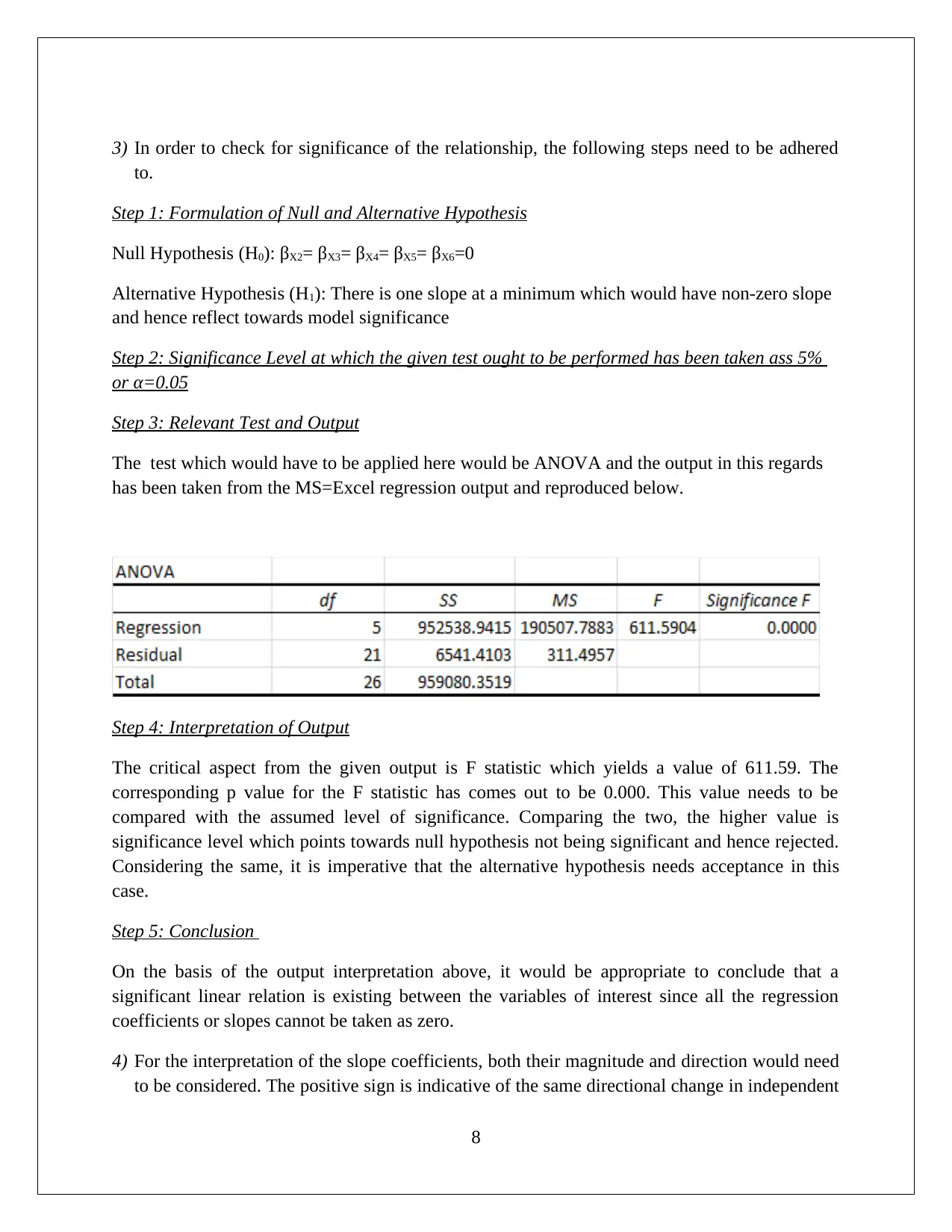
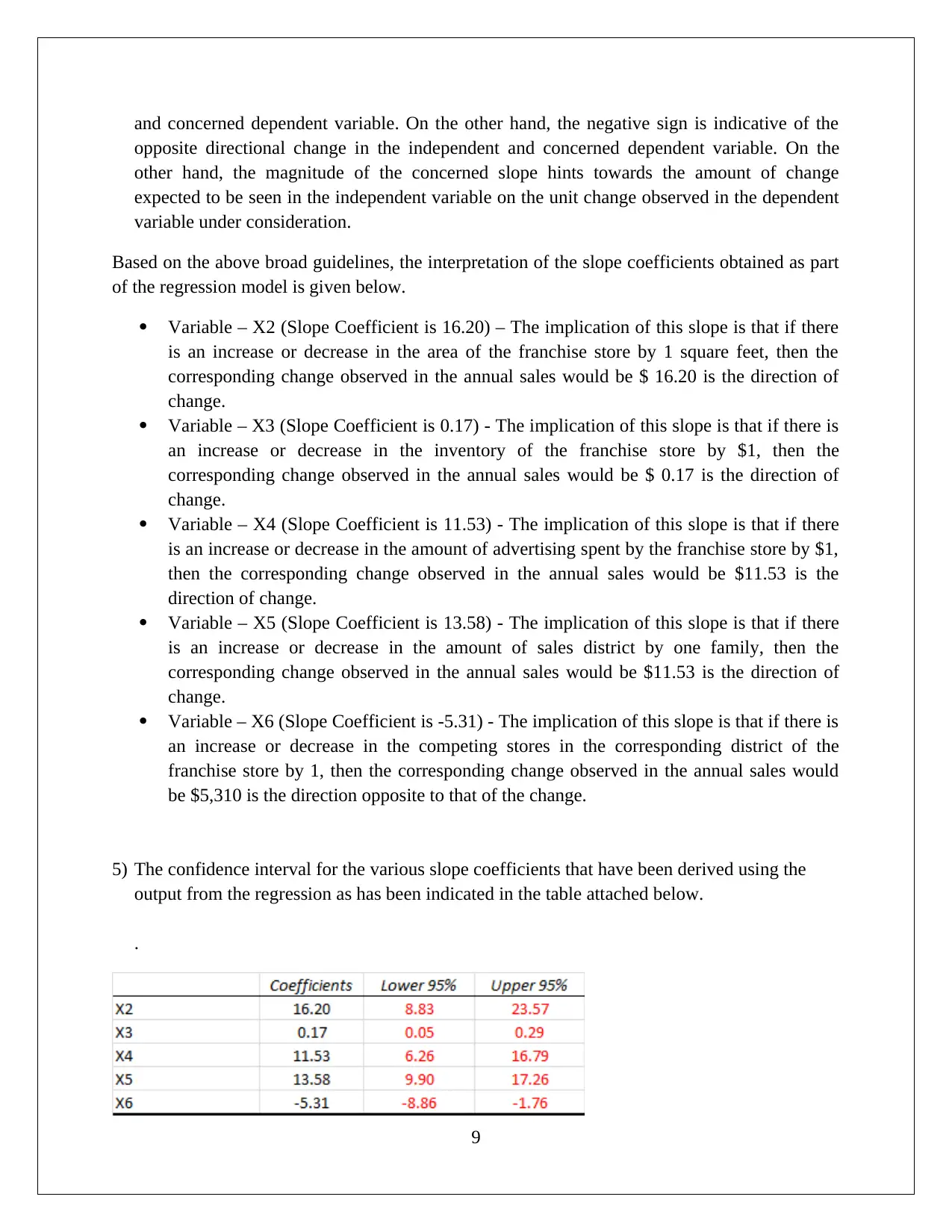
This assignment solution for HI6007 Statistics covers descriptive and inferential statistical analyses, focusing on startup costs and regression models. Task 1 involves calculating descriptive statistics, constructing frequency distributions and histograms, and conducting an ANOVA test to compare the average startup costs of different businesses. Task 2 utilizes regression analysis to model the relationship between annual sales and various independent variables, including franchise store area, inventory level, advertising spend, sales district families, and number of competing stores. The solution includes the formulation of hypotheses, significance level determination, test outputs, interpretation of results (including F-statistic and p-values), and conclusions. The interpretation of slope coefficients, confidence intervals, and the application of the regression model to predict annual sales are also provided, demonstrating a comprehensive understanding of statistical methods and their application in business contexts.



1 out of 13
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.