HI6007 Group Assignment: Statistical Analysis and Regression Models
VerifiedAdded on 2023/06/04
|17
|2515
|396
Homework Assignment
AI Summary
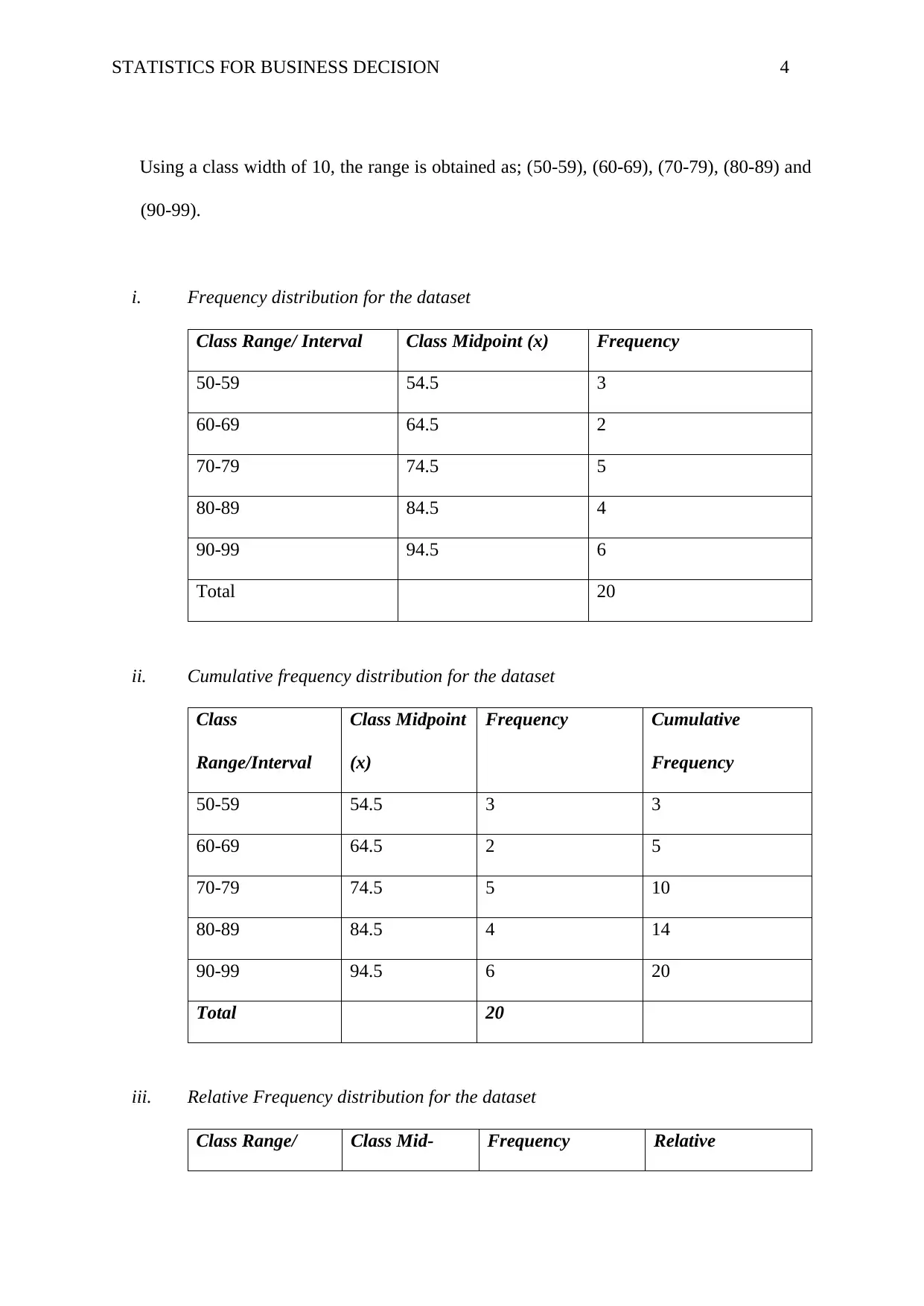
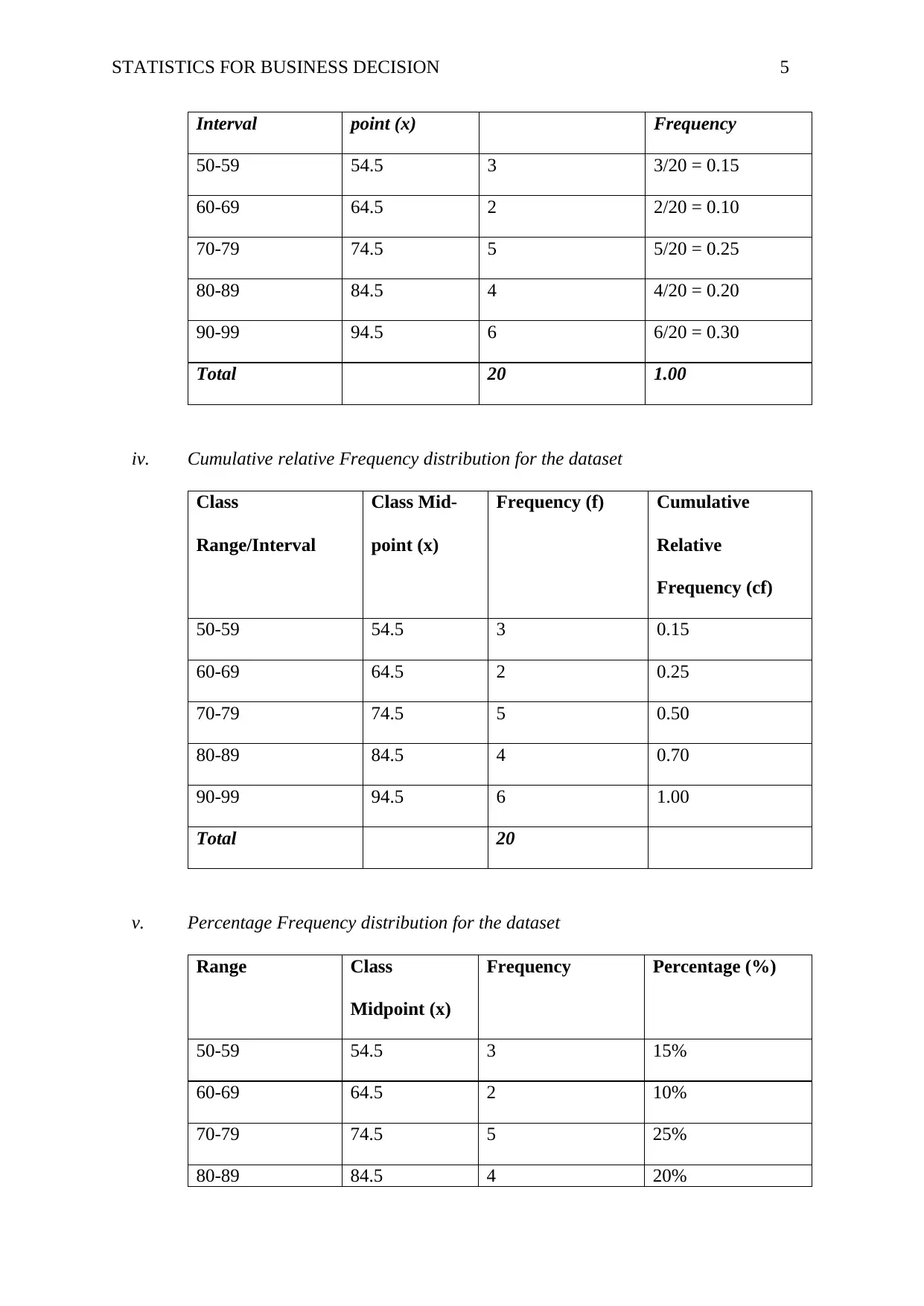
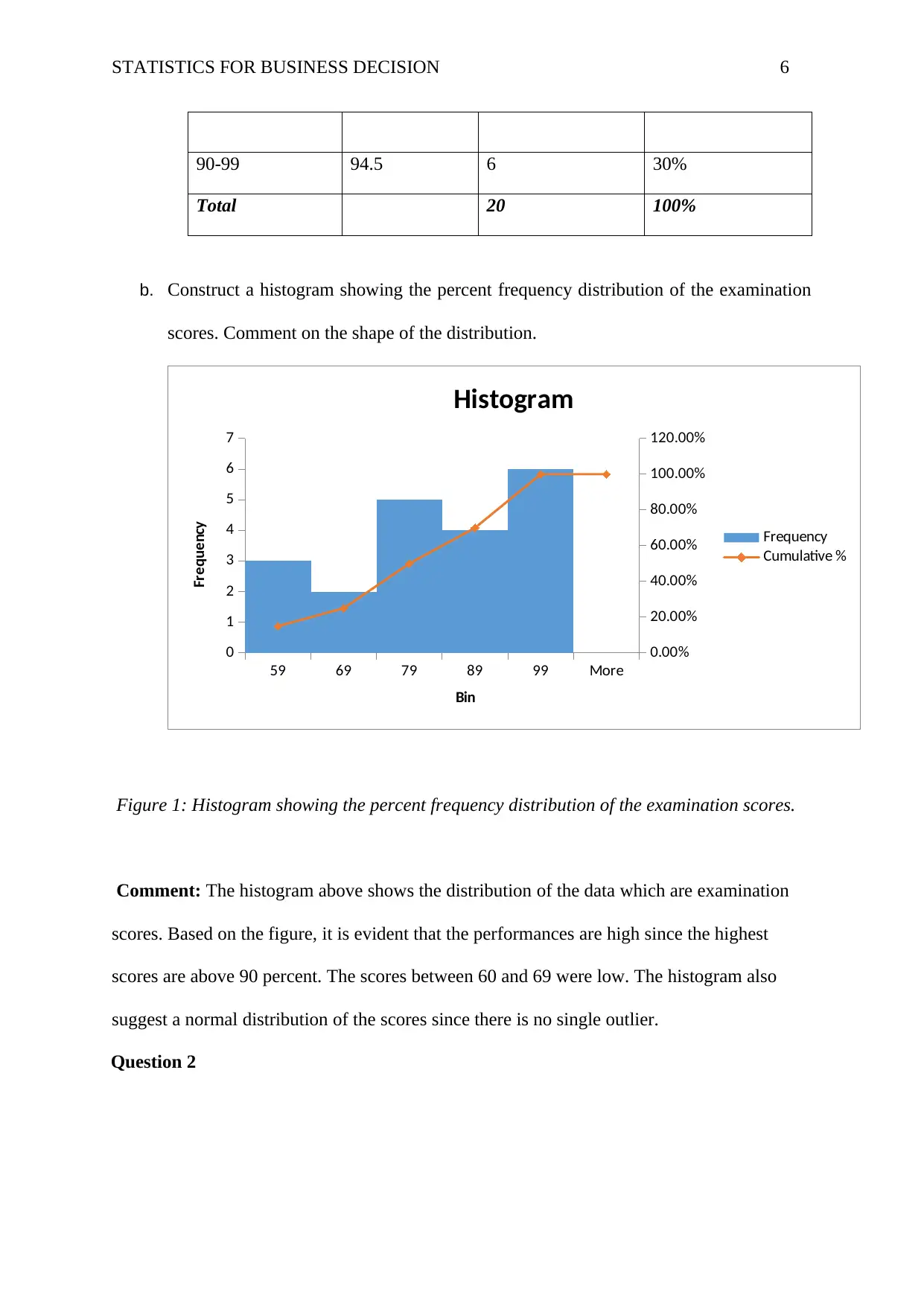
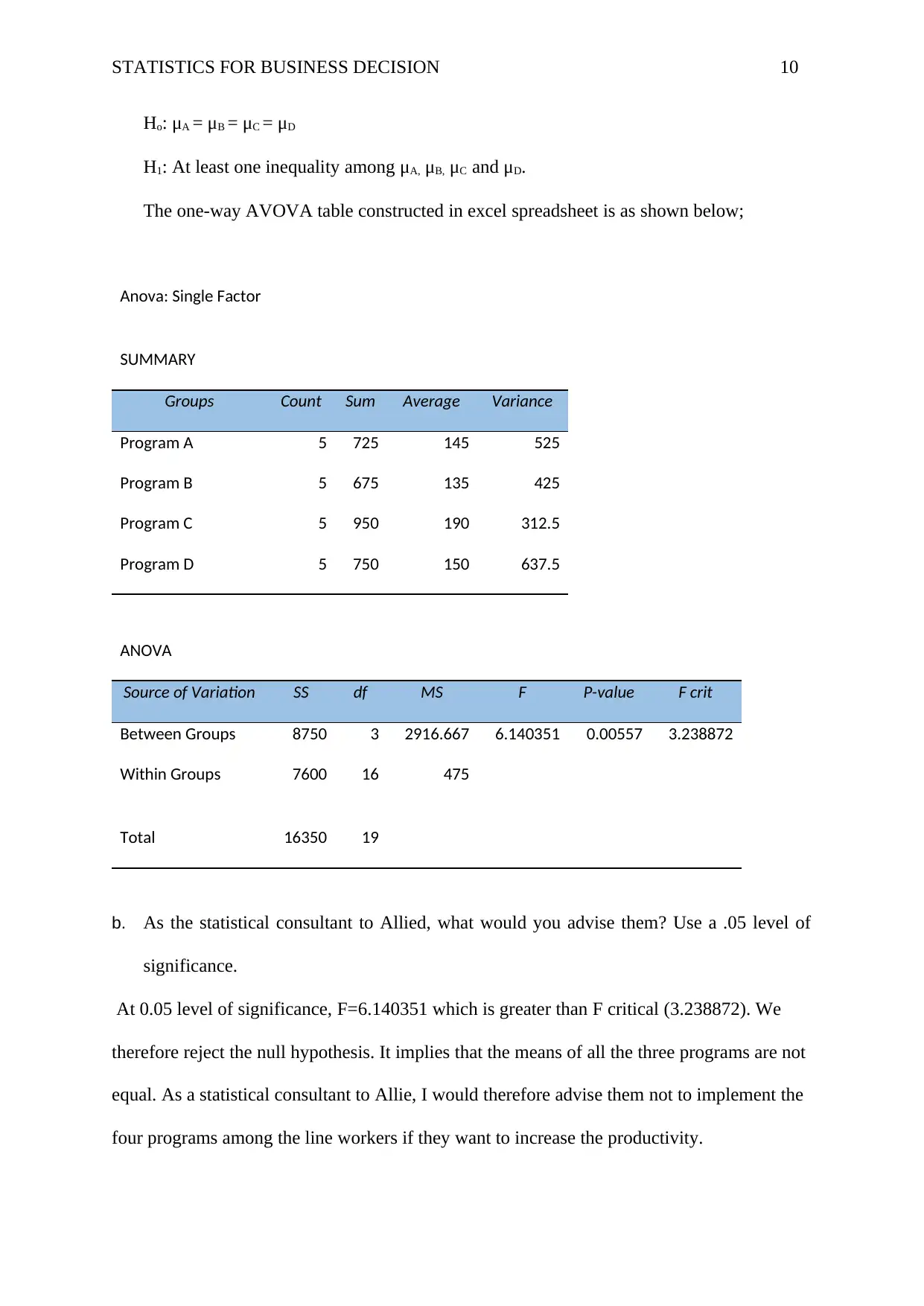
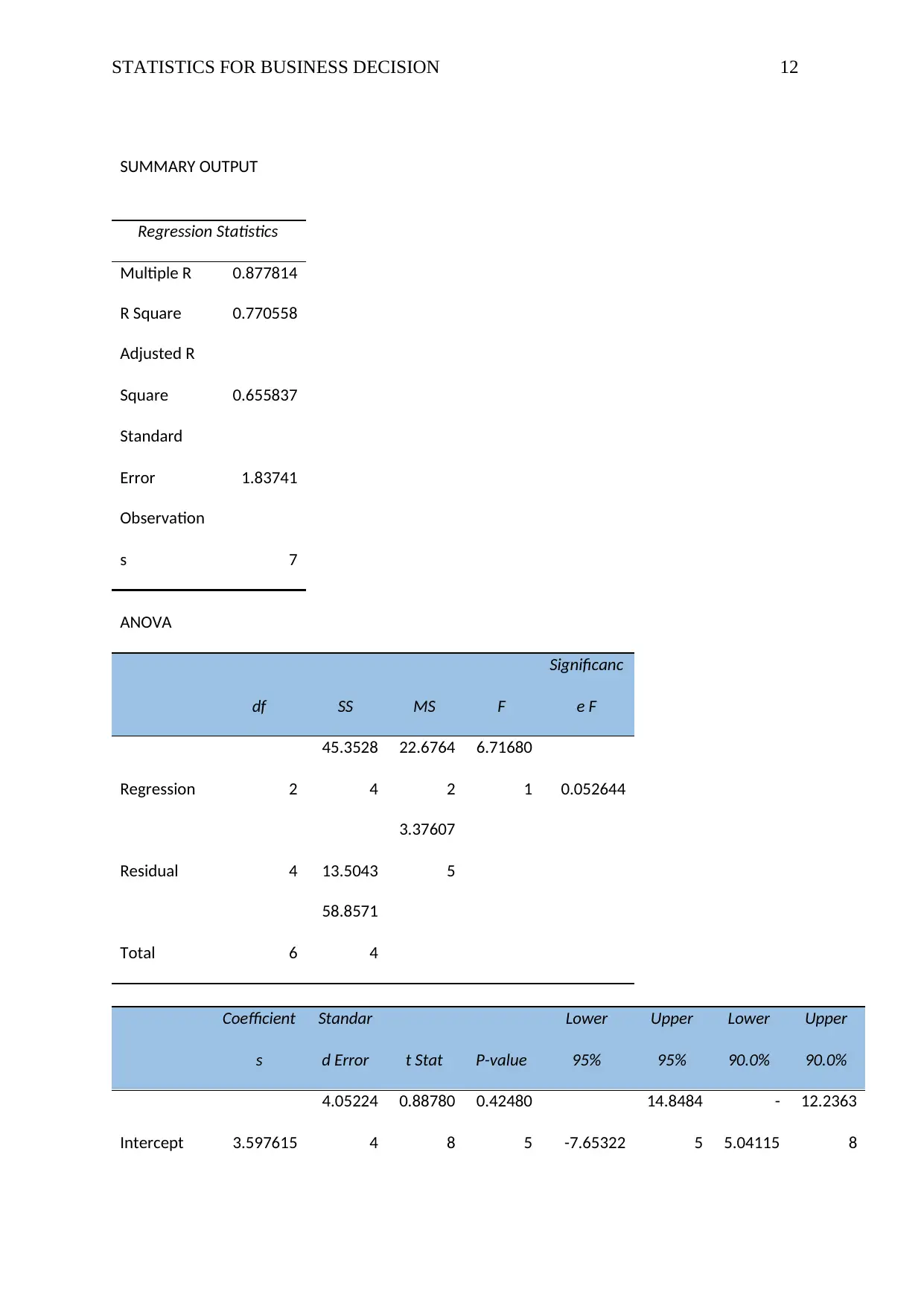
This assignment solution for HI6007 Statistics for Business Decisions covers several key statistical concepts. Question 1 focuses on constructing frequency distributions (frequency, cumulative frequency, relative frequency, cumulative relative frequency, and percentage frequency) and histograms from a dataset of examination scores, along with a comment on the distribution's shape. Question 2 delves into regression analysis, analyzing a computer output to determine the sample size, the relationship between demand and unit price, the coefficient of determination and correlation, and predicting supply based on unit price. Question 3 involves constructing an ANOVA table to assess the impact of different programs on worker productivity, followed by a recommendation. Finally, Question 4 uses Excel's Regression Tool to estimate a regression equation, assess its overall significance, determine the significance of individual variables, and re-estimate the model after dropping insignificant variables, including interpreting the slope coefficients.







1 out of 17
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.