Statistics Resit Assignment for Introduction to Accounting & Finance
VerifiedAdded on 2023/01/12
|6
|1050
|88
Homework Assignment
AI Summary
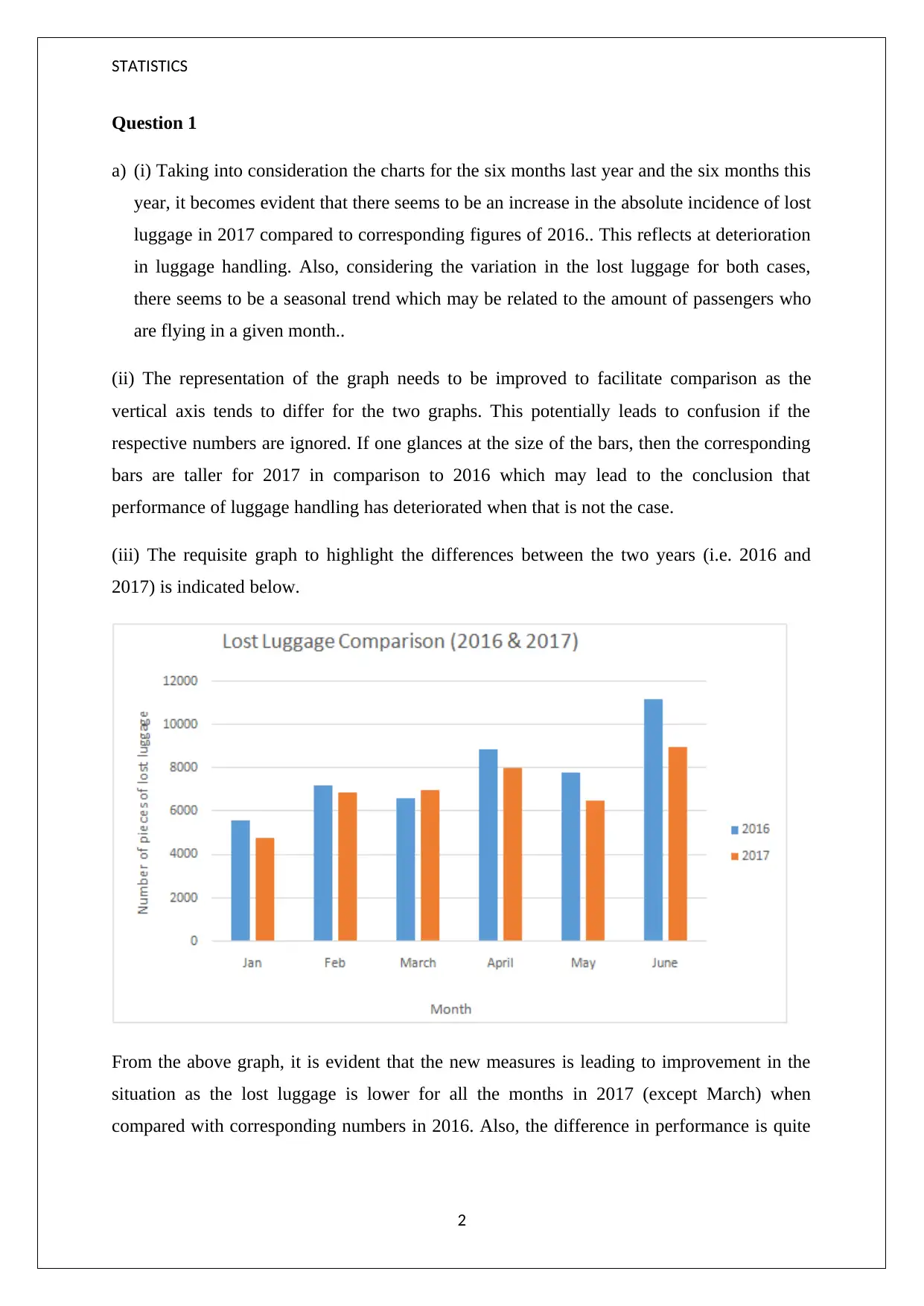
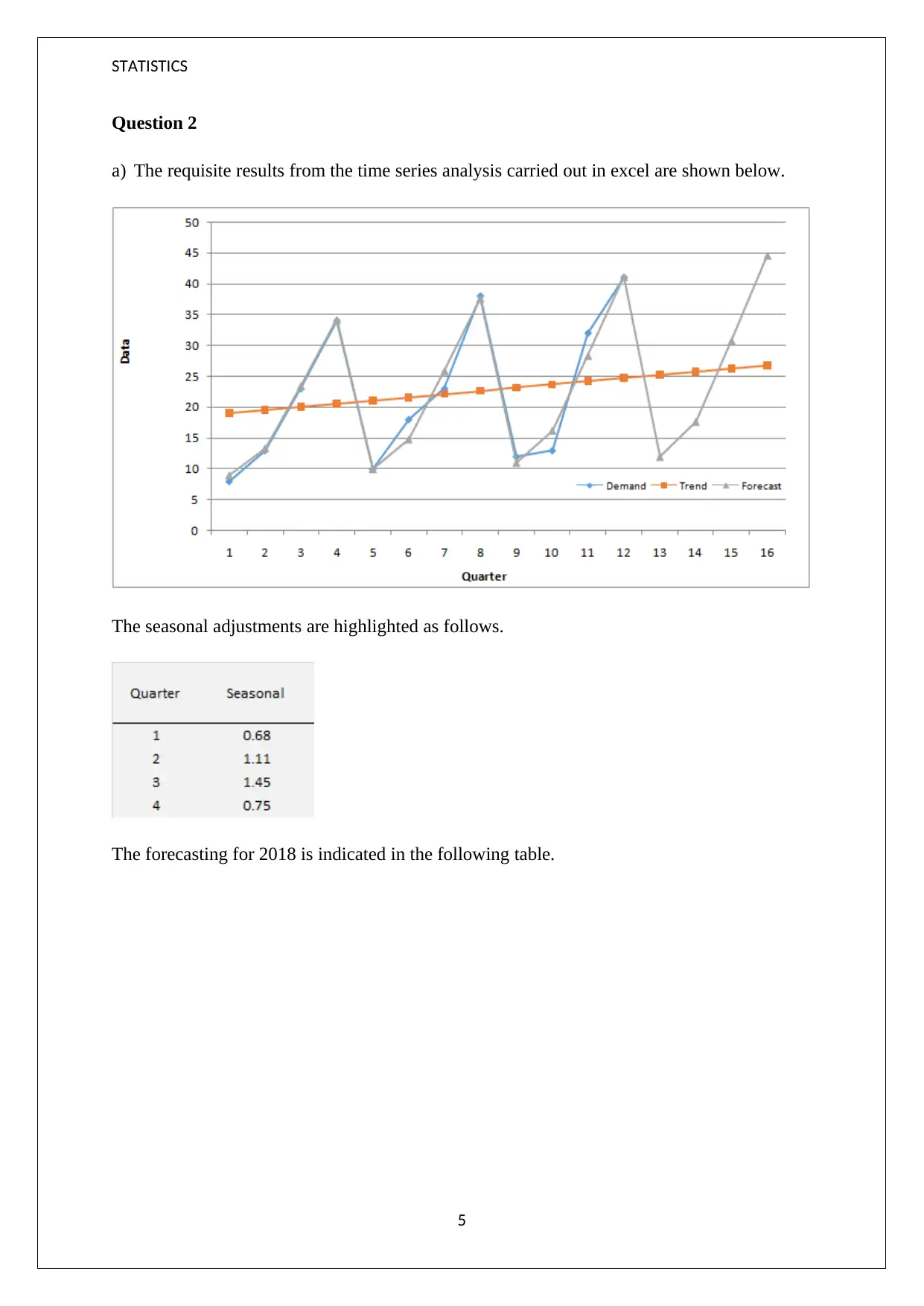
This statistics resit assignment presents a comprehensive analysis of data, focusing on time series analysis and forecasting techniques. The assignment begins with an examination of luggage handling data, comparing lost luggage incidents over two years and discussing the need for improved graph representations to facilitate comparison. It then delves into the concepts of mean and median, illustrating their application with examples and explaining the impact of skewed data. The assignment also evaluates a histogram, identifying issues with its presentation and interpreting its skewness. Furthermore, it explores the suitability of different chart types for data representation. Finally, the assignment presents a time series analysis with seasonal adjustments and forecasting using a multiplicative model. The rationale behind the chosen model is explained in the context of increasing sales trends and the presence of seasonality.




1 out of 6
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.