Introduction to Statistics (STATS 101) Hypothesis Testing Assignment
VerifiedAdded on 2023/06/05
|23
|3476
|106
Homework Assignment
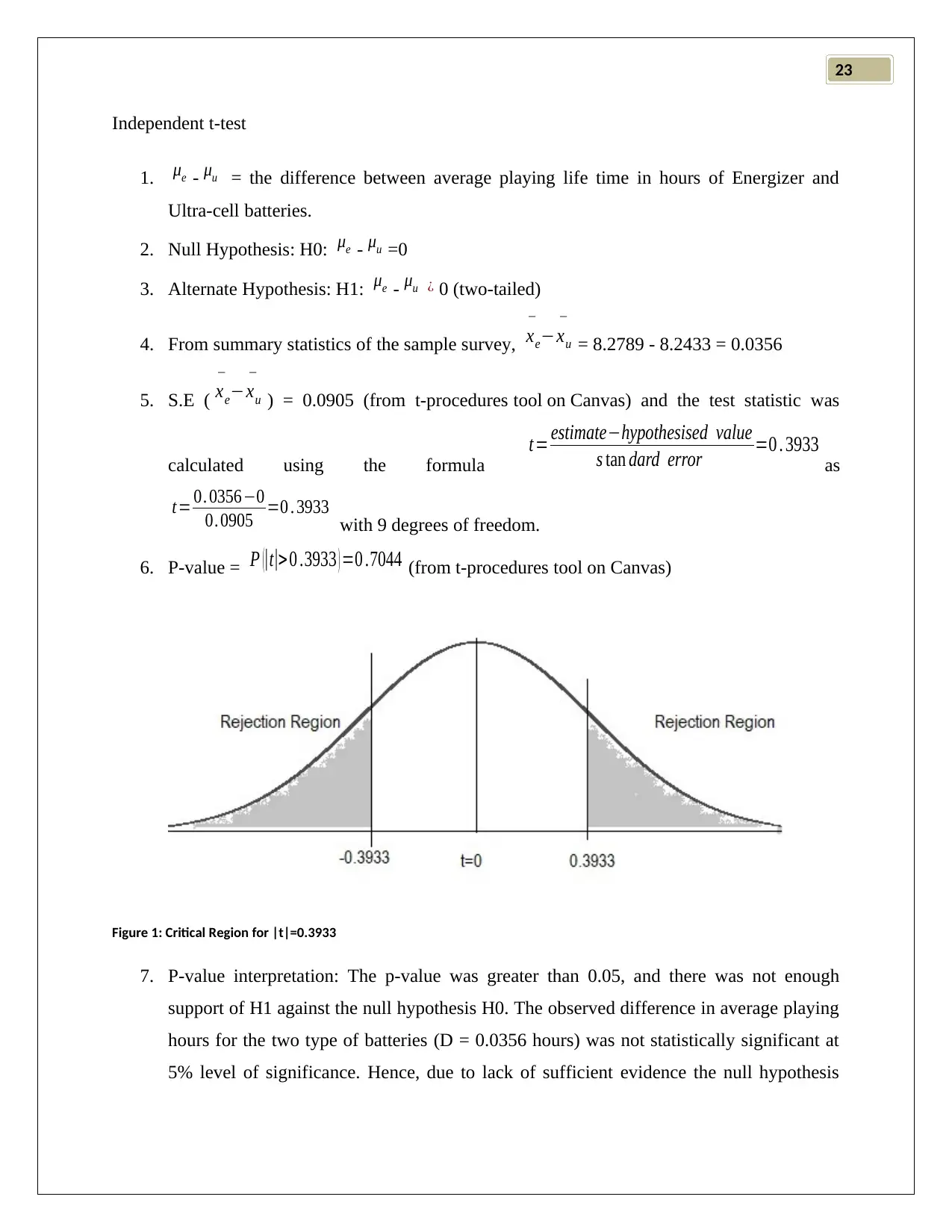
AI Summary
This document presents a comprehensive solution to a statistics assignment focused on hypothesis testing. The assignment explores various scenarios, including comparing battery life using independent t-tests, analyzing proportions related to cannabis legalization using a t-test for the difference between two proportions, and evaluating productivity scores across different cases. It also examines the impact of spoiler paragraphs on enjoyment ratings using a dependent t-test and investigates the relationship between cyclist age and completion time in a cycling event. The solution provides detailed statistical analyses, including the calculation and interpretation of p-values, confidence intervals, and test statistics, along with discussions on statistical and practical significance. It also includes graphical representations and interpretations to support the findings.










1 out of 23
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.