STATS 201/8 Assignment 1: Analyzing Economic and Health Data
VerifiedAdded on 2022/10/02
|14
|2093
|36
Homework Assignment
AI Summary
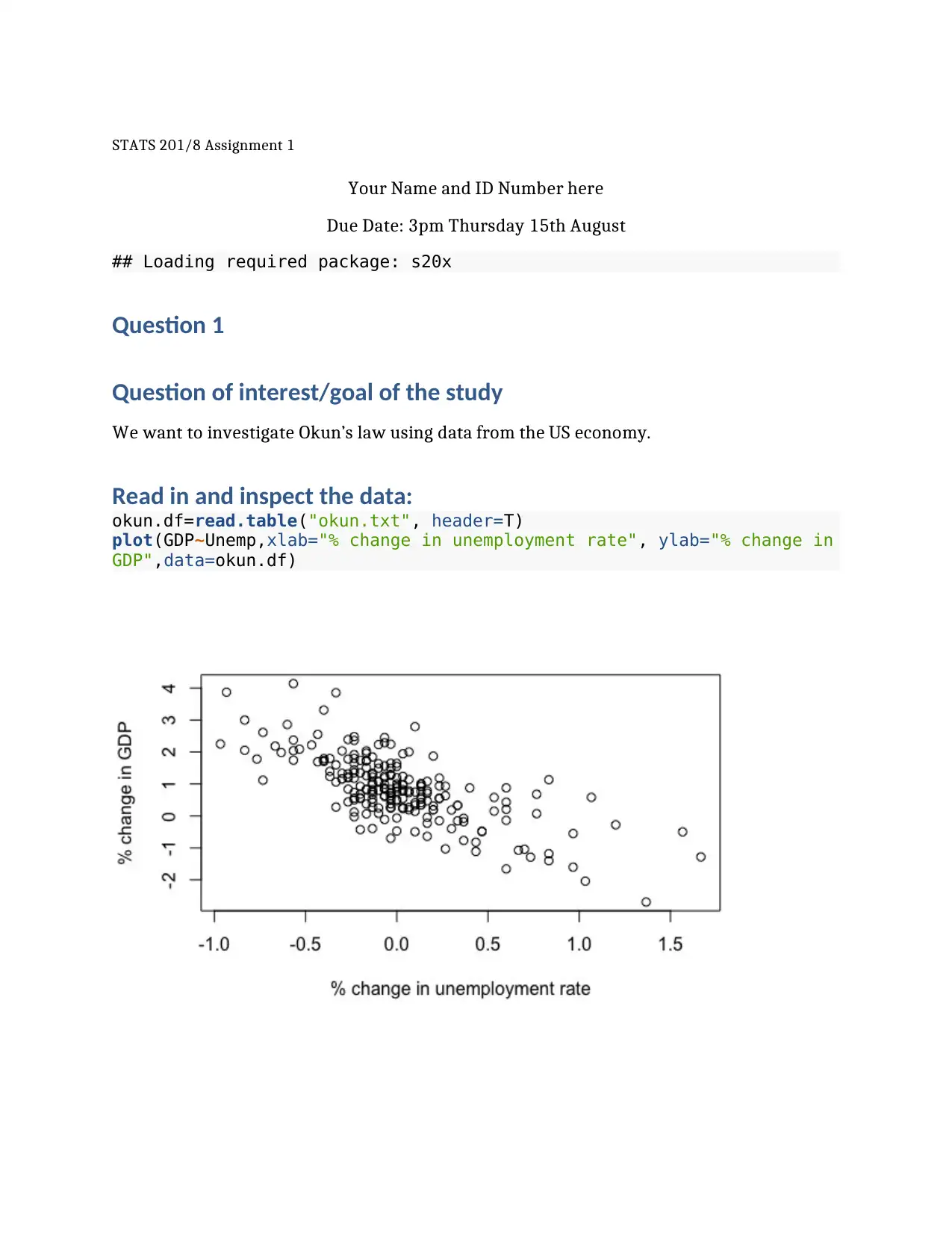
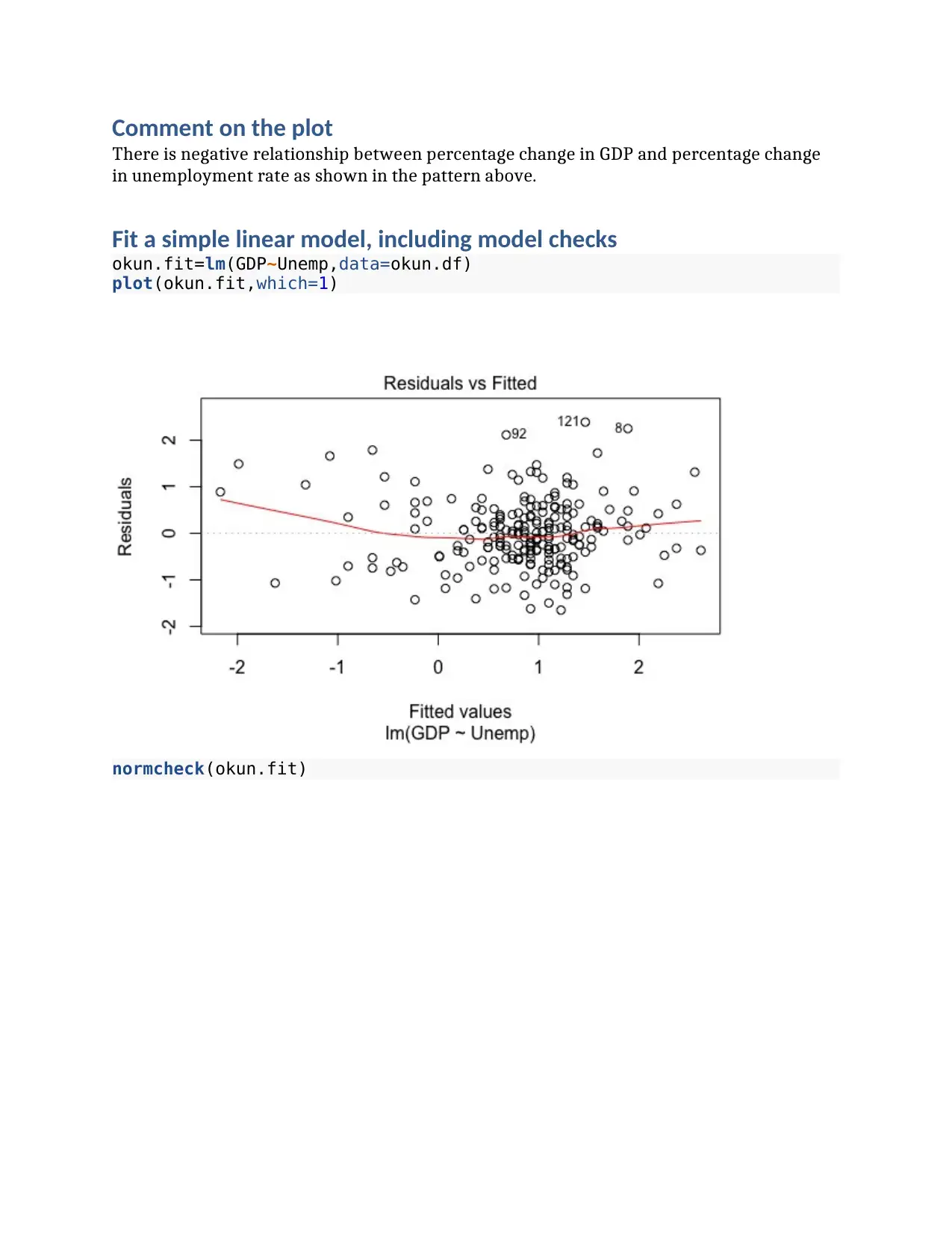
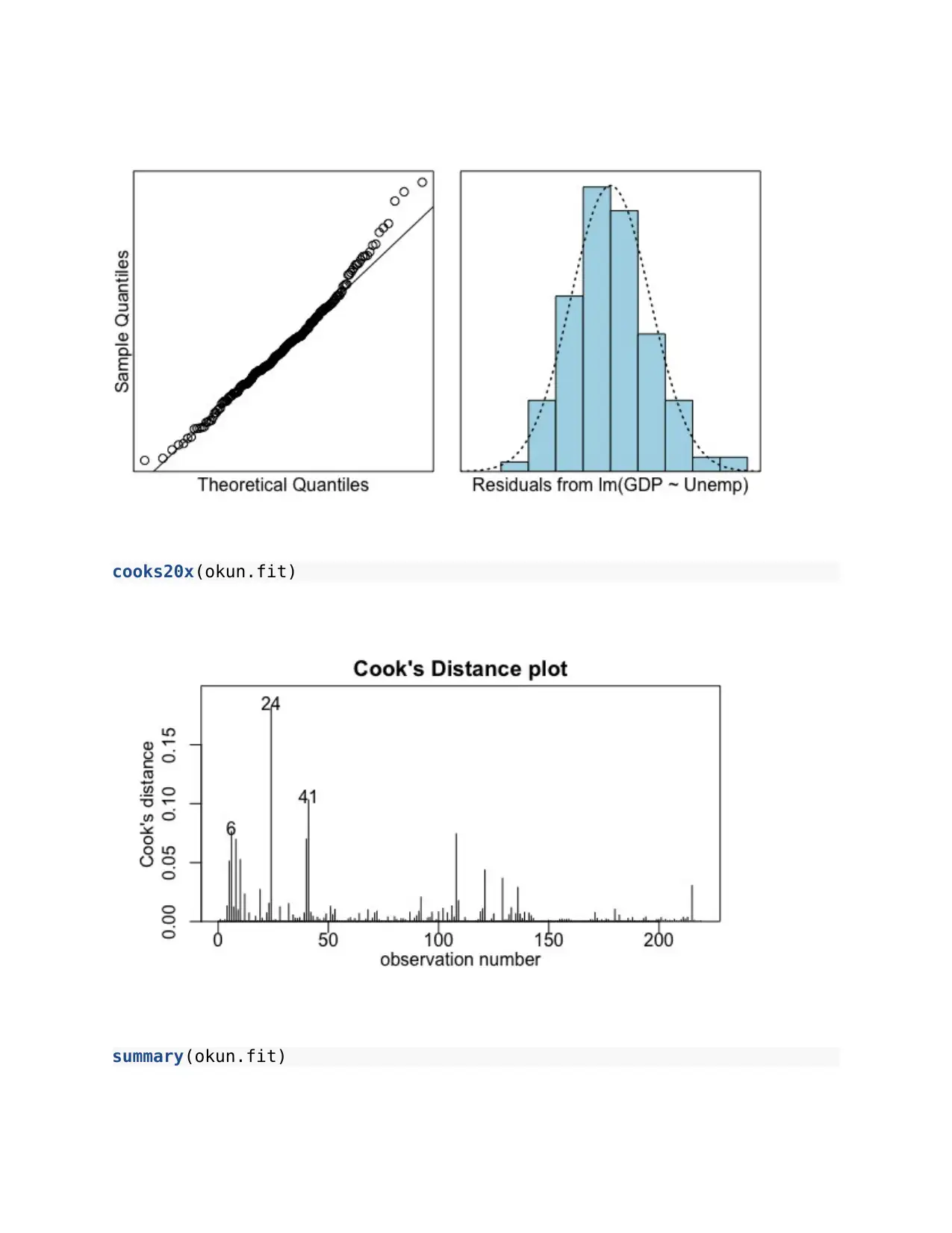
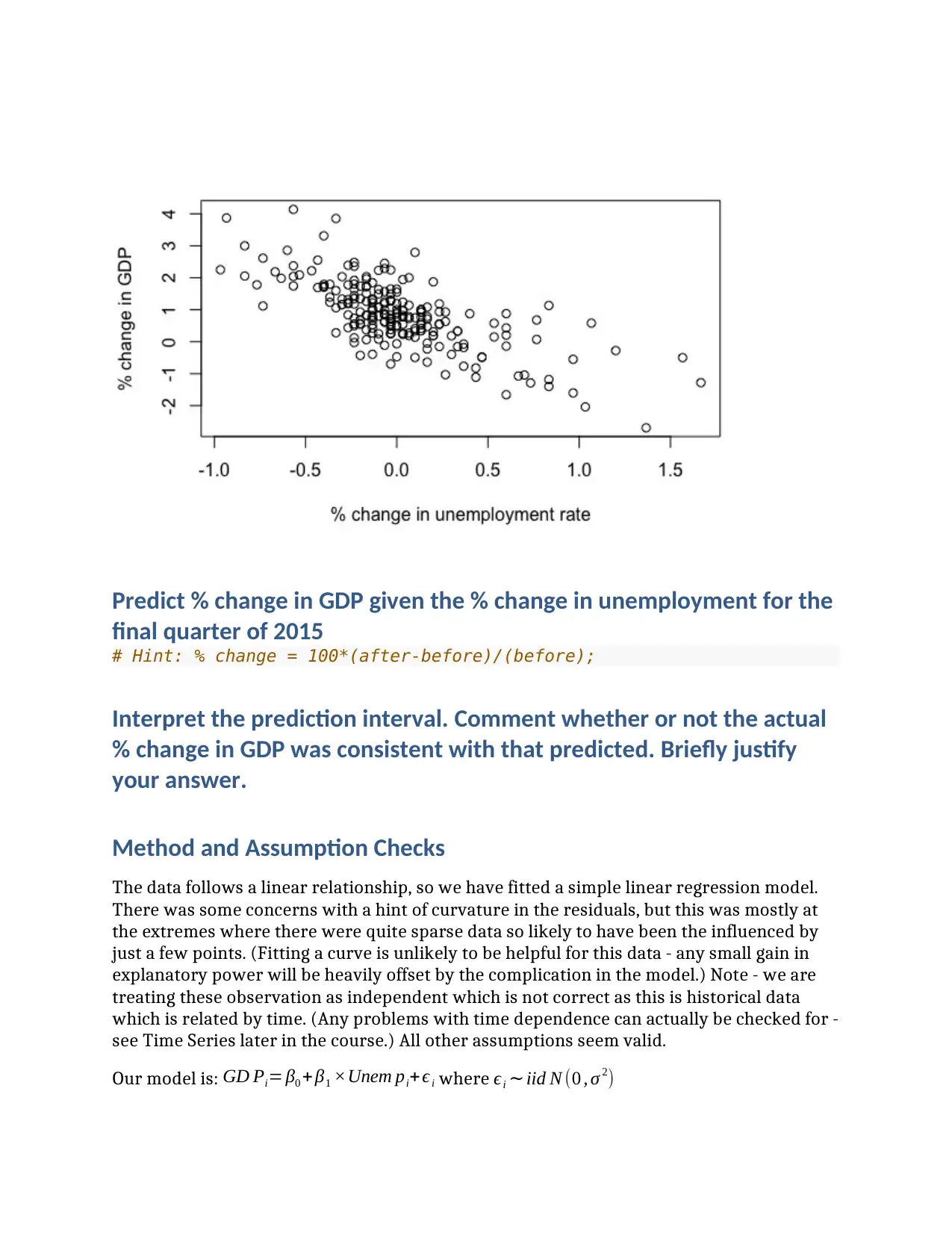
This assignment focuses on applying statistical methods to analyze real-world datasets. The first part investigates Okun's Law, examining the relationship between the percentage change in GDP and the percentage change in the unemployment rate using linear regression. The second part analyzes systolic blood pressure data before and after a therapy, employing a paired t-test to determine if there is a significant change. The final part investigates the relationship between the power consumption of an electric bike and its speed, utilizing linear regression to model and predict power consumption. The assignment includes data inspection, model fitting, model checks, and interpretation of results, including executive summaries for each question. The analysis includes calculating t-statistics, confidence intervals, and assessing model assumptions, providing a comprehensive statistical analysis of each scenario.





1 out of 14
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.