Stanford STATS216v Summer 2018 Problem Set 1 Assignment
VerifiedAdded on 2023/06/10
|10
|1809
|365
Homework Assignment
AI Summary
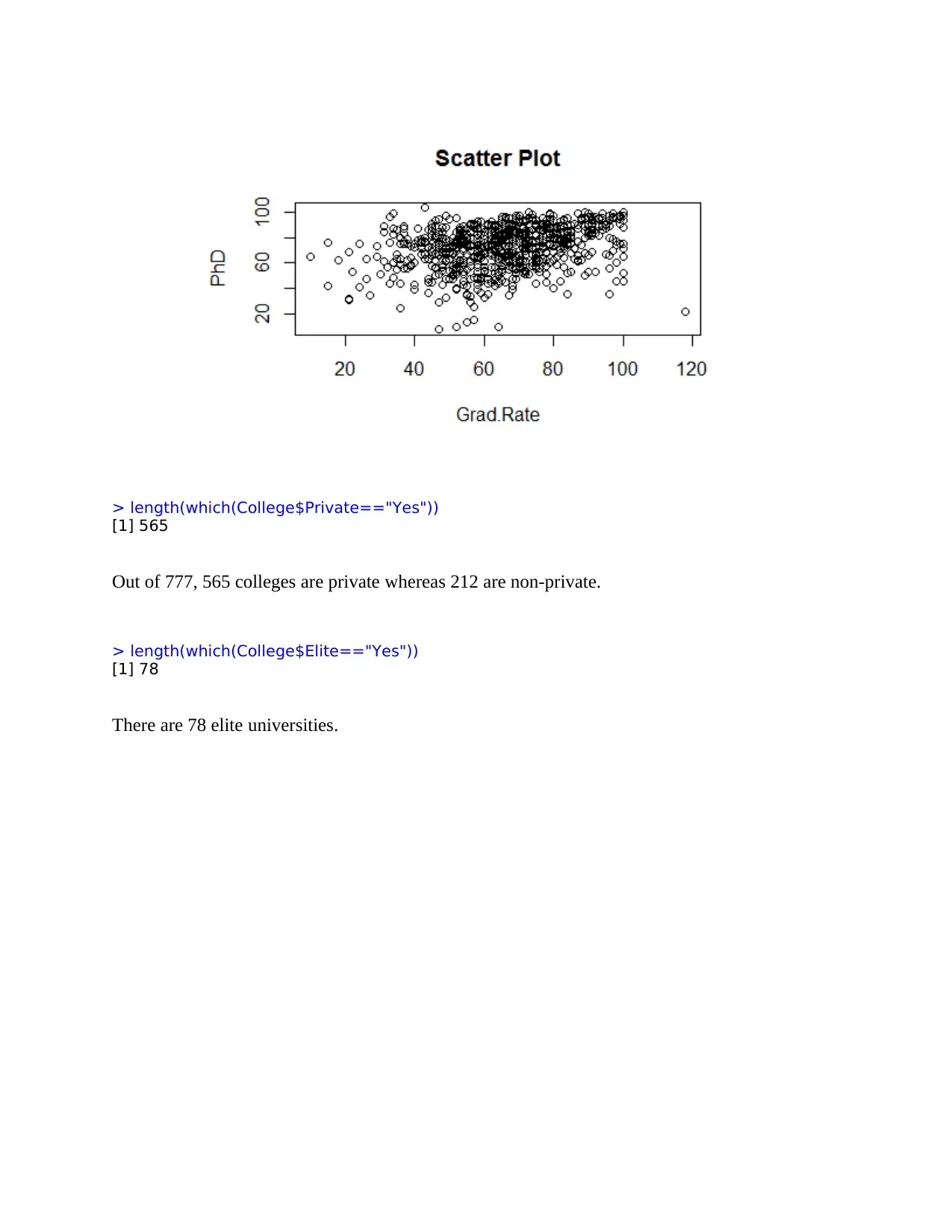
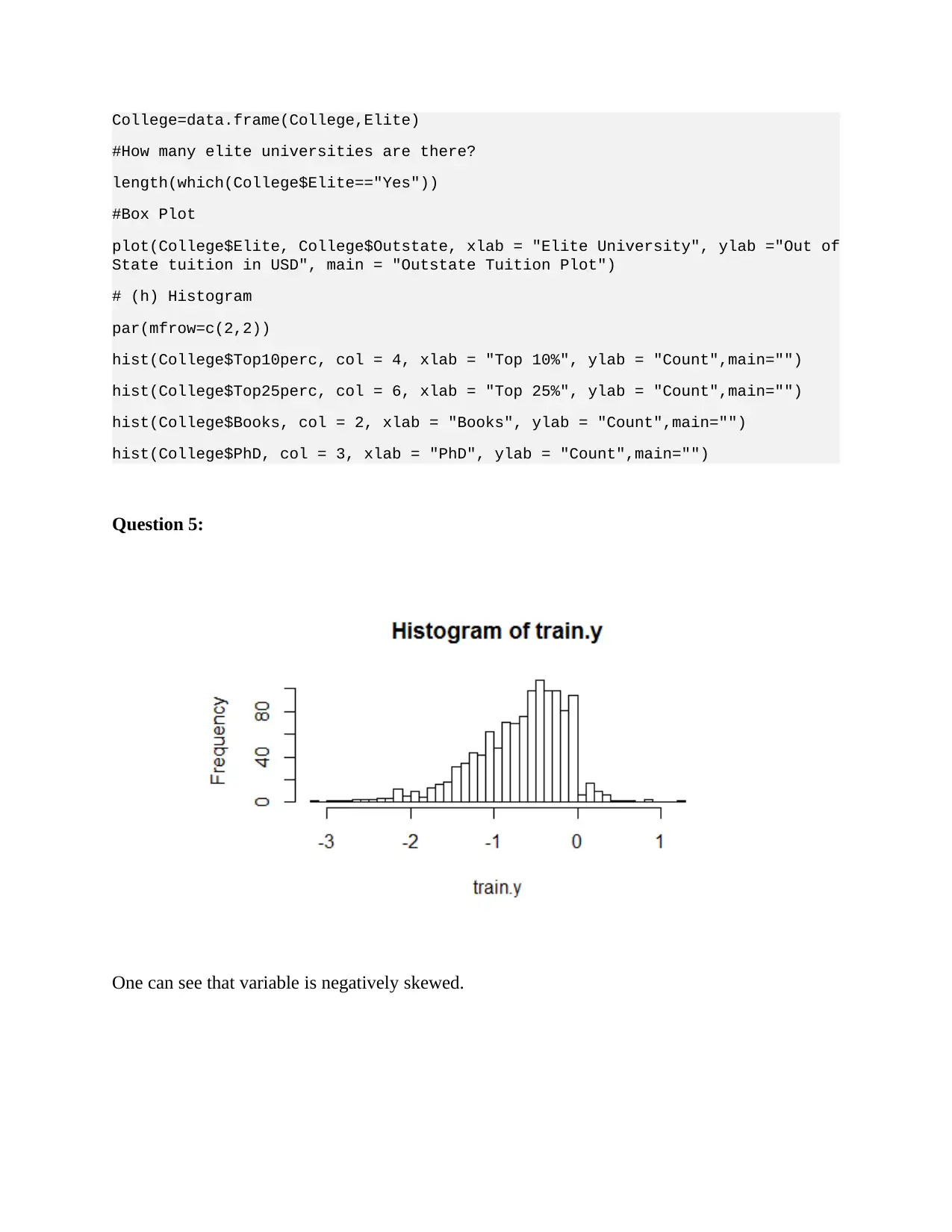
This document provides a comprehensive solution to Problem Set 1 for the STATS216v Introduction to Statistical Learning course at Stanford University, Summer 2018. The solution addresses various aspects of statistical learning, including supervised and unsupervised learning models. It covers regression and classification problems, determining the number of observations and predictors in different scenarios. The assignment includes detailed explanations and analysis of different scenarios, such as oil excavation, advertisement targeting, and unemployment rate prediction. The solution also explores the use of flexible and inflexible regression models, discussing their performance based on the number of predictors and observations. Furthermore, it provides R code and output to analyze college data, including summary statistics, scatter plots, and histograms. The document also includes an analysis of a linear regression model applied to ALS data, covering coefficient estimates, R-squared, RMSE, and bias-variance trade-offs. The solution provides insights into the practical application of statistical learning concepts and techniques.








1 out of 10
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.