Analysis of Structured Query Language and Server Services in Databases
VerifiedAdded on 2022/01/04
|13
|1744
|22
Report
AI Summary
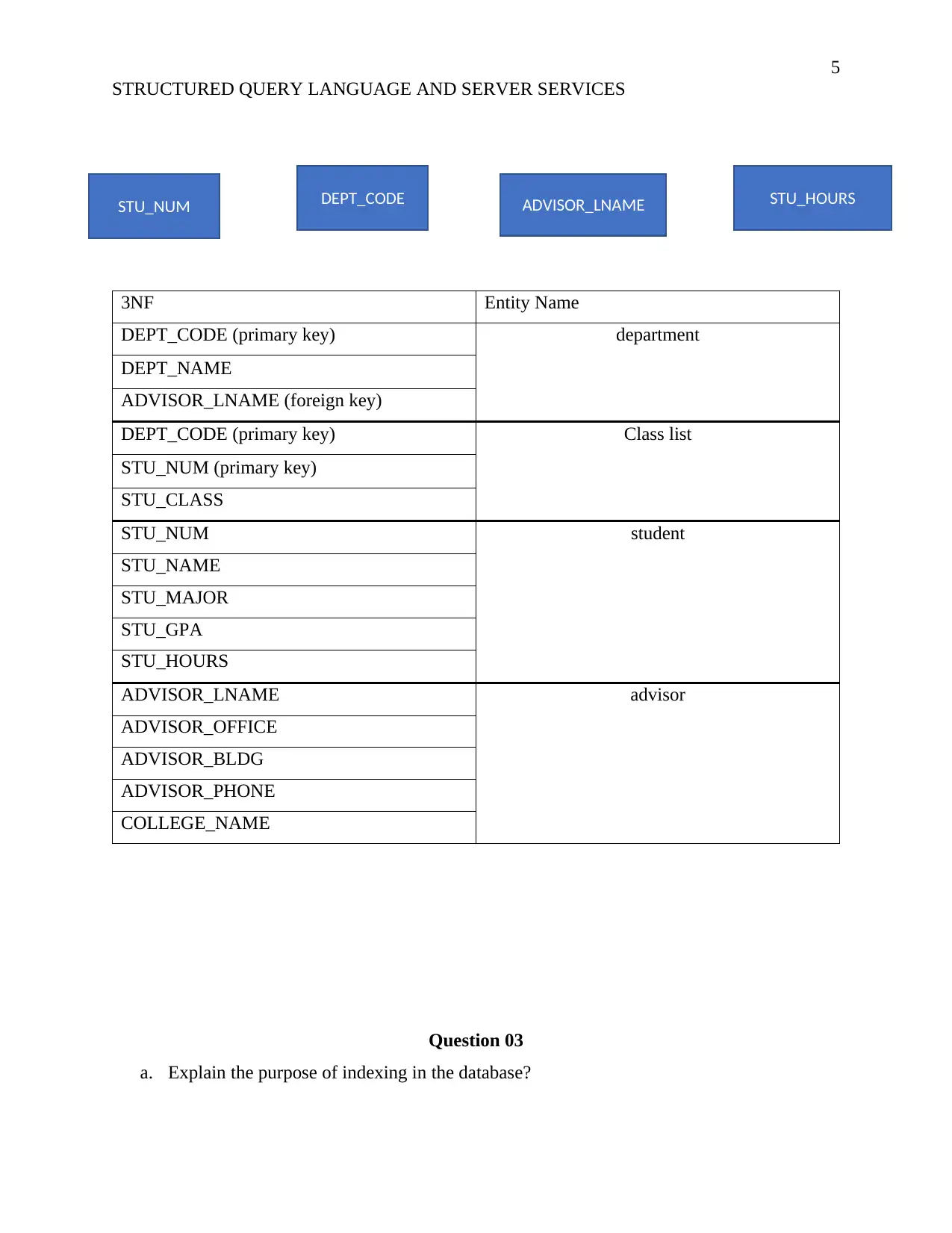
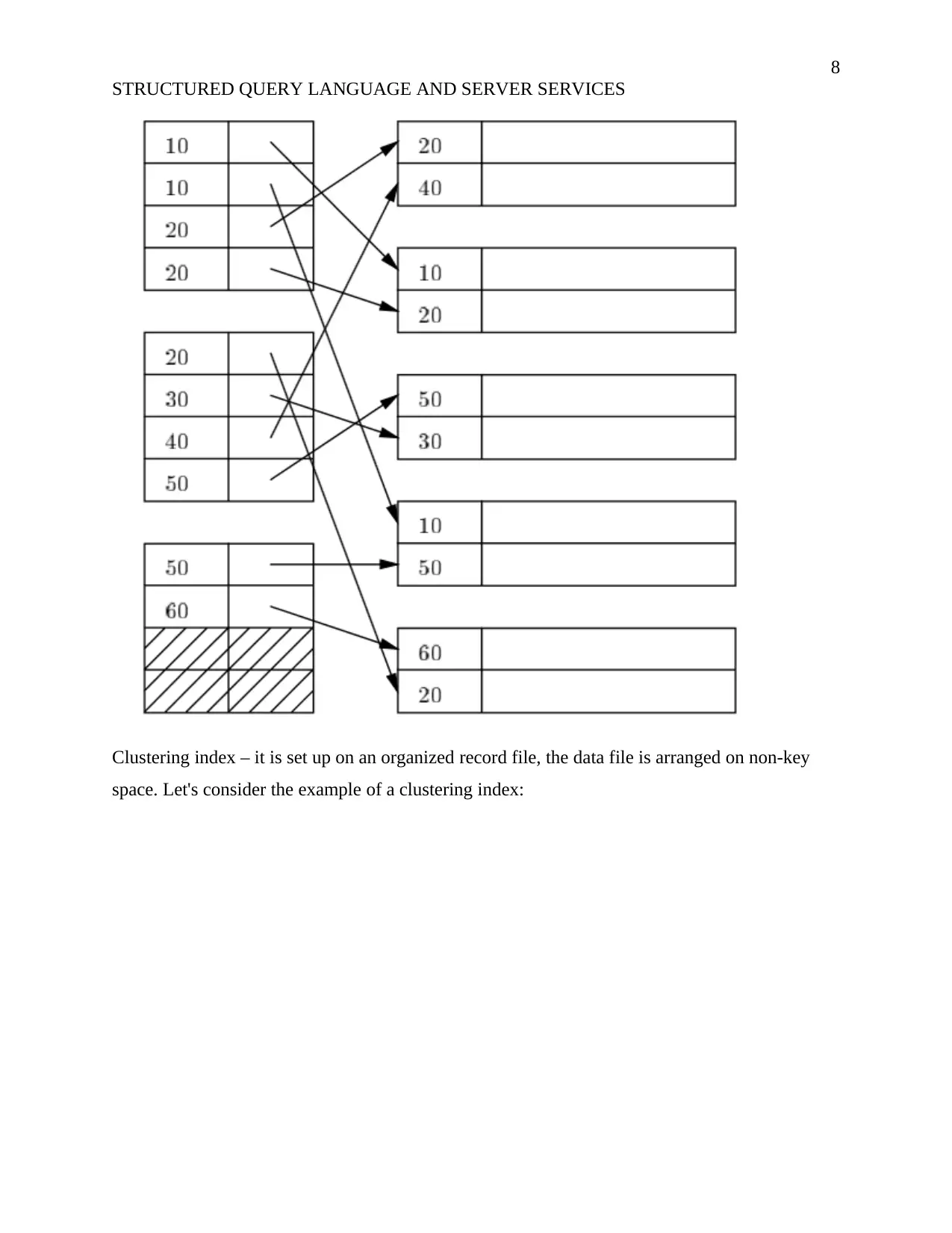
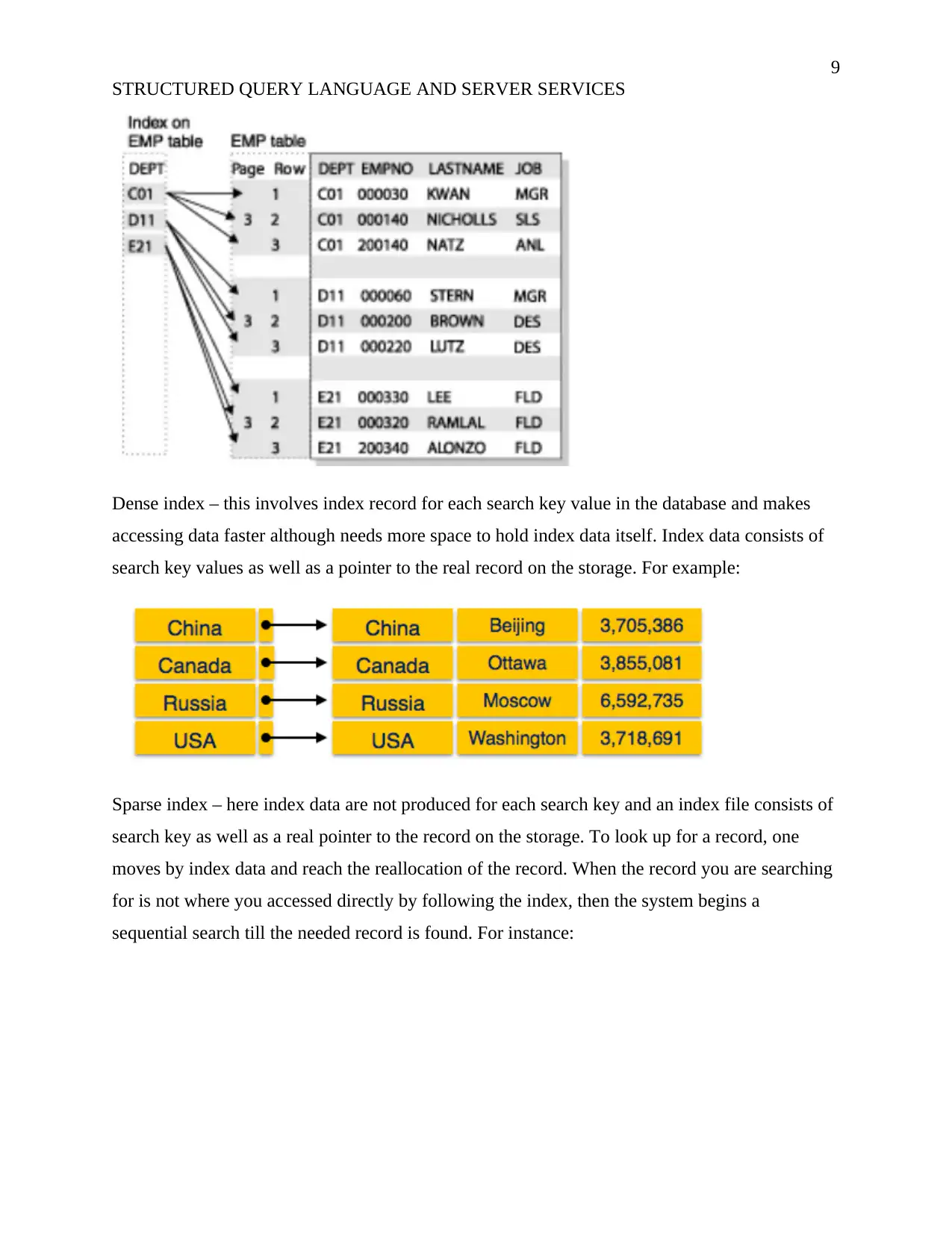
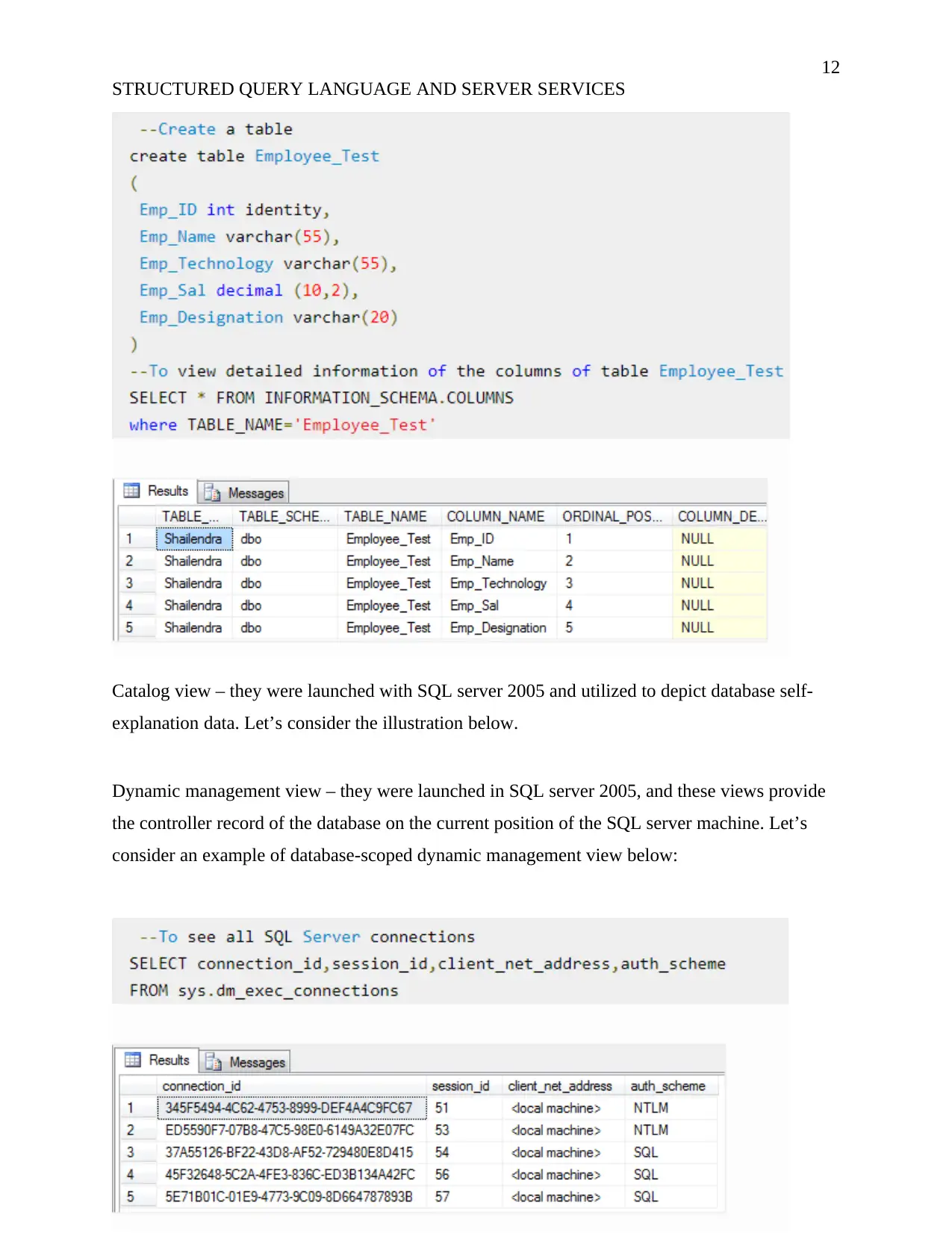
This report examines the concepts of Structured Query Language (SQL) and server services within the context of database management. It begins by evaluating database normalization, explaining its necessity in maintaining data integrity and efficiency, covering 1NF, 2NF, 3NF, BCNF, and 4NF. A dependency diagram is drawn and the conversion of a student record table into 3NF is demonstrated. The report then explores the purpose of indexing in databases, detailing various index types such as primary, secondary, clustering, dense, sparse, and multilevel indexes, with illustrative examples. Key features of indexed tables and different types of views, including information schema, catalog, and dynamic management views, are also discussed. The report provides a comprehensive overview of database design principles, data organization, and efficient data retrieval methods, offering valuable insights into database management and optimization.








1 out of 13
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.