Comprehensive Report on Numeracy and Data Analysis for Study Hours
VerifiedAdded on 2023/01/03
|10
|1277
|20
Report
AI Summary
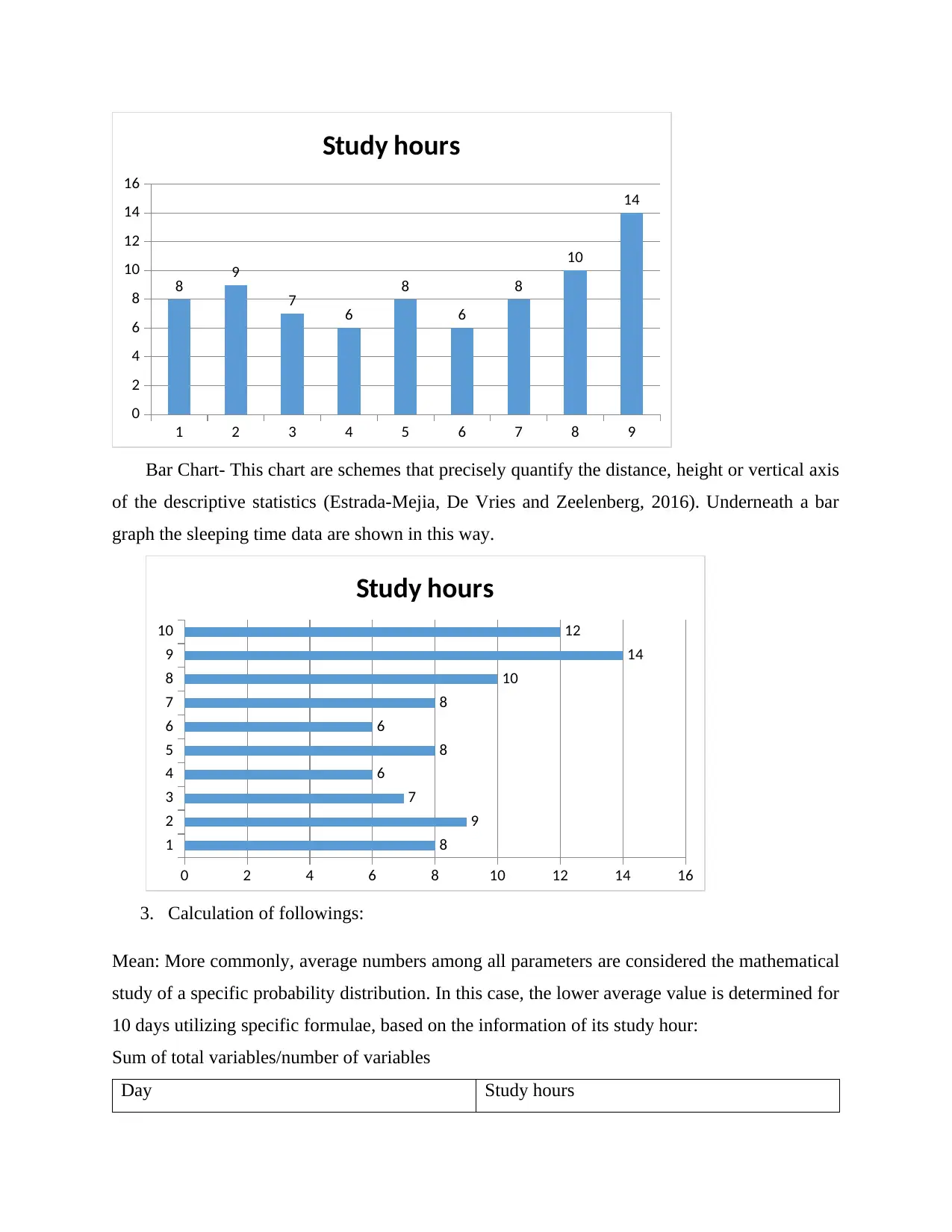
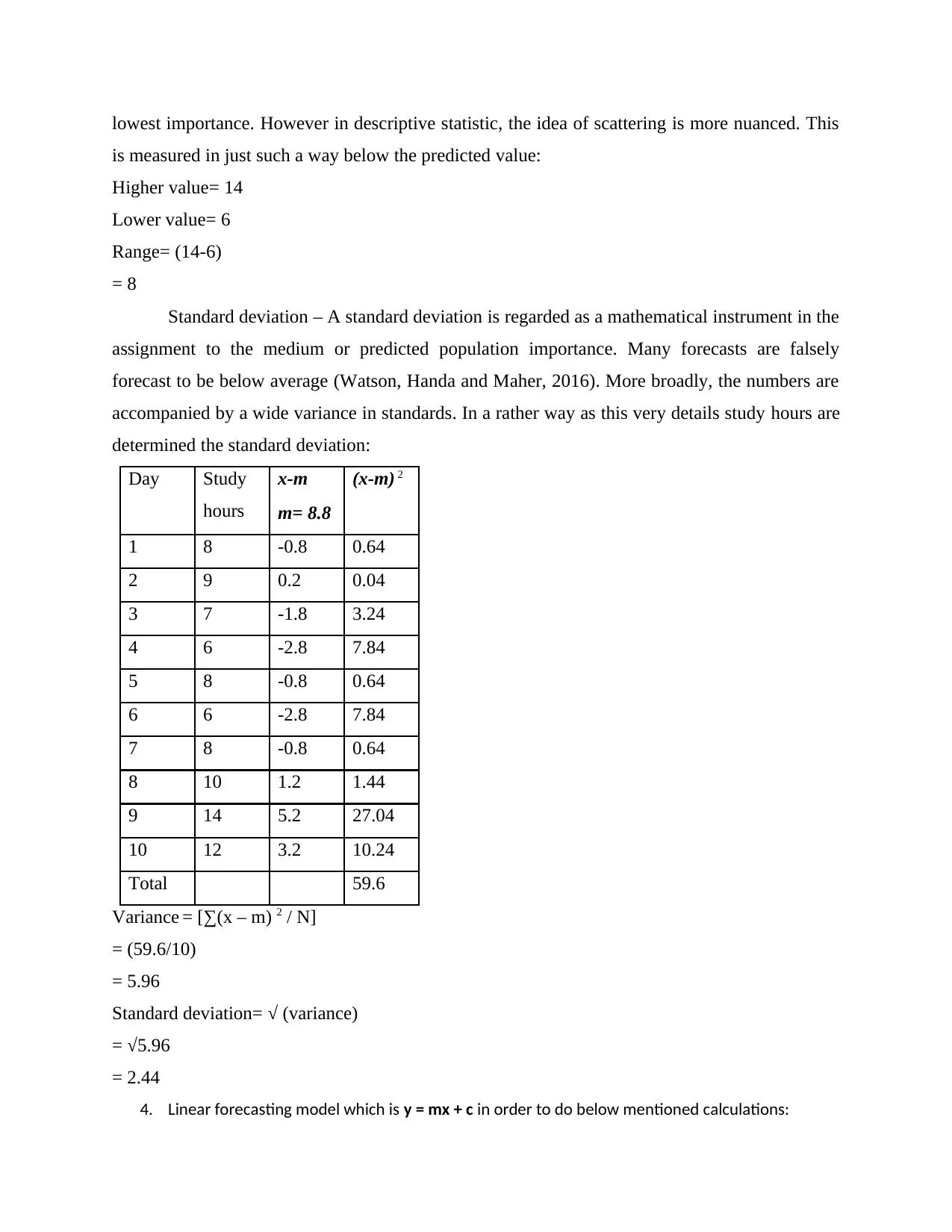
This report delves into the application of numeracy and data analysis, focusing on the analysis of study hours over a ten-day period. The report begins with data organization in a table format and proceeds to present the data visually using column and bar charts. Key statistical measures, including mean, mode, median, range, and standard deviation, are calculated to provide a comprehensive understanding of the data's central tendencies and dispersion. Furthermore, the report employs a linear forecasting model to predict study hours for the 11th and 15th days. The analysis highlights the practical utility of data analysis methods in drawing insights and making informed predictions, concluding with a summary of the findings and their implications.







1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.