Knowledge Engineering Report: Analyzing Twitter Data with RapidMiner
VerifiedAdded on 2023/03/17
|20
|3897
|53
Report
AI Summary
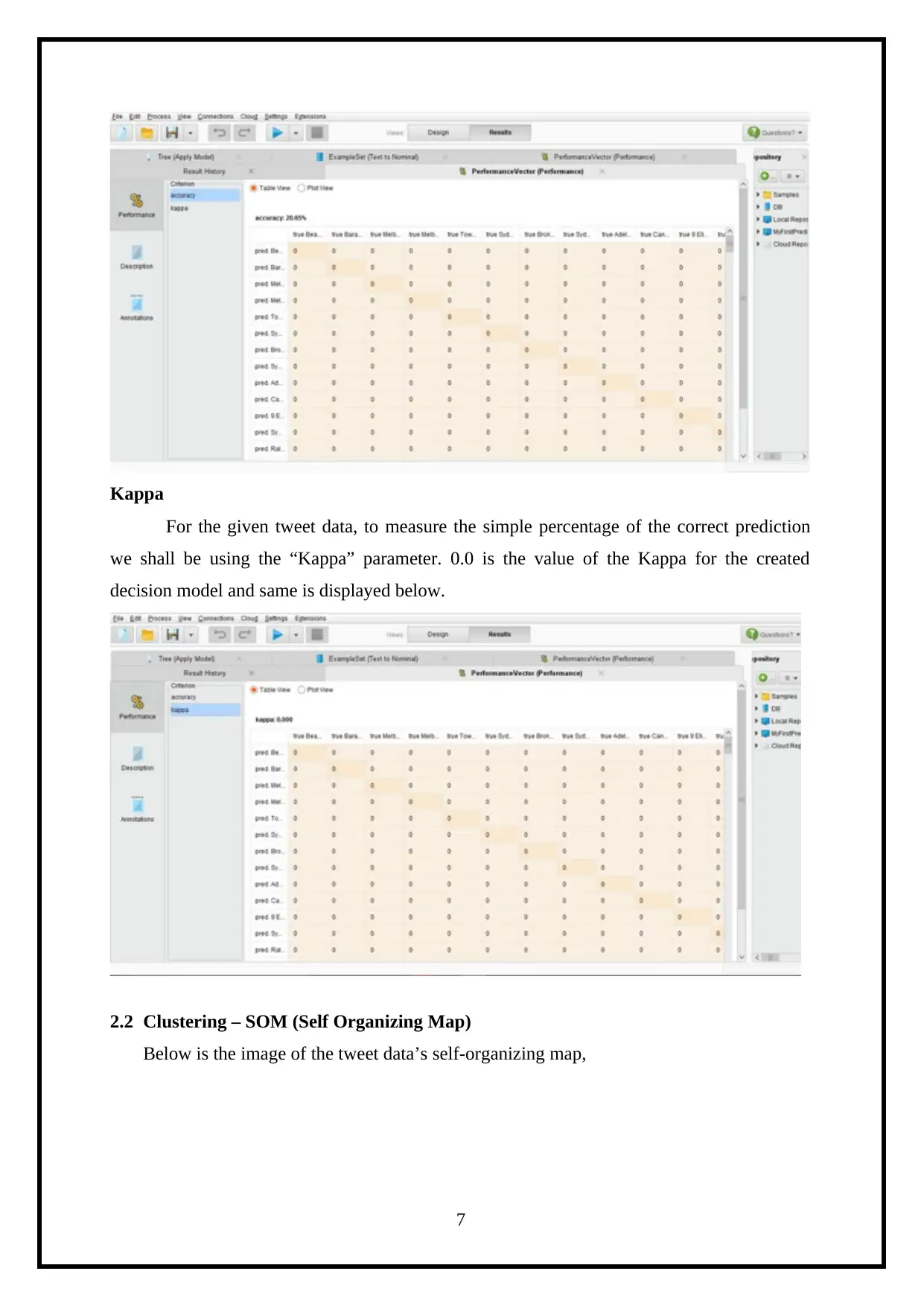
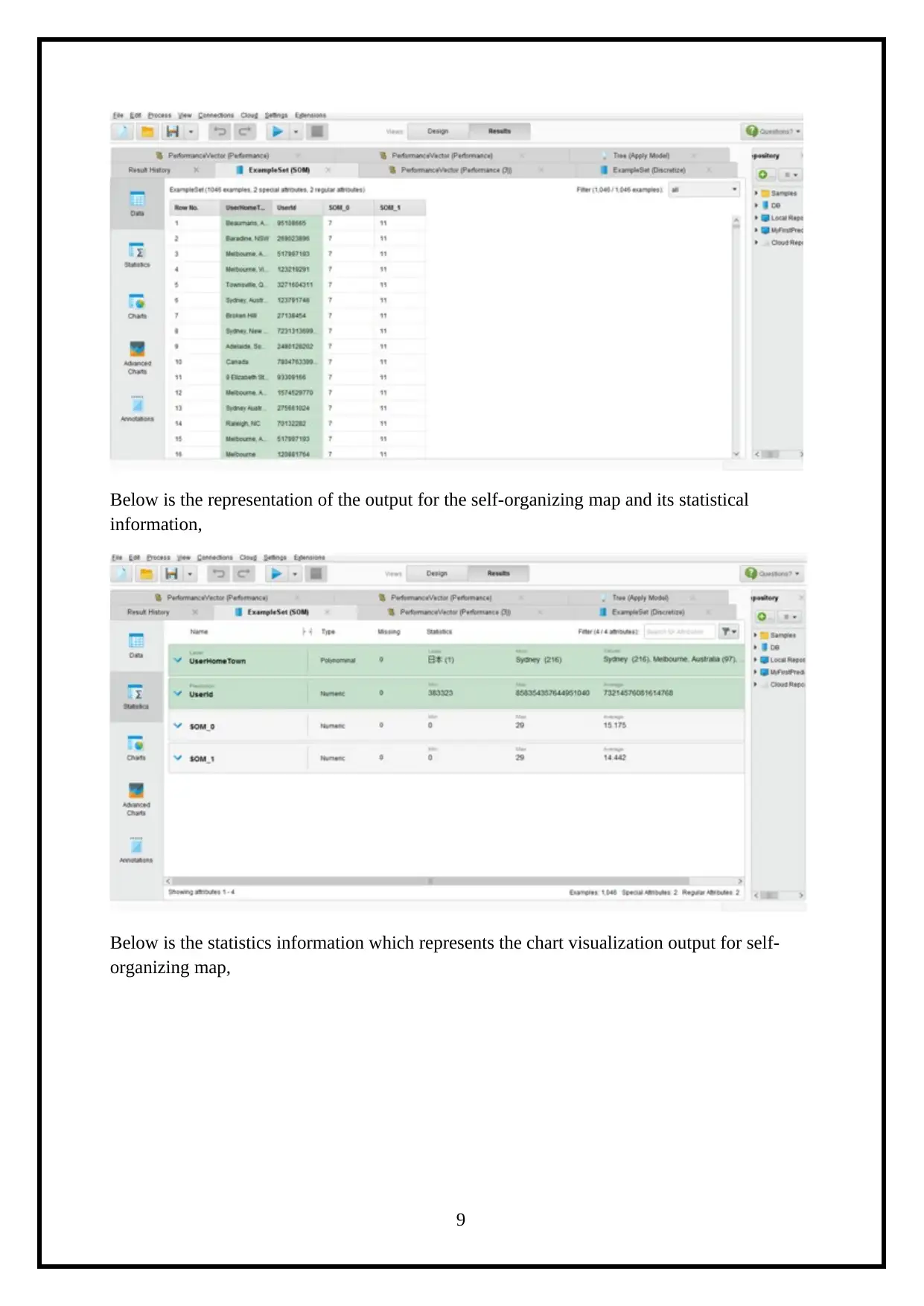
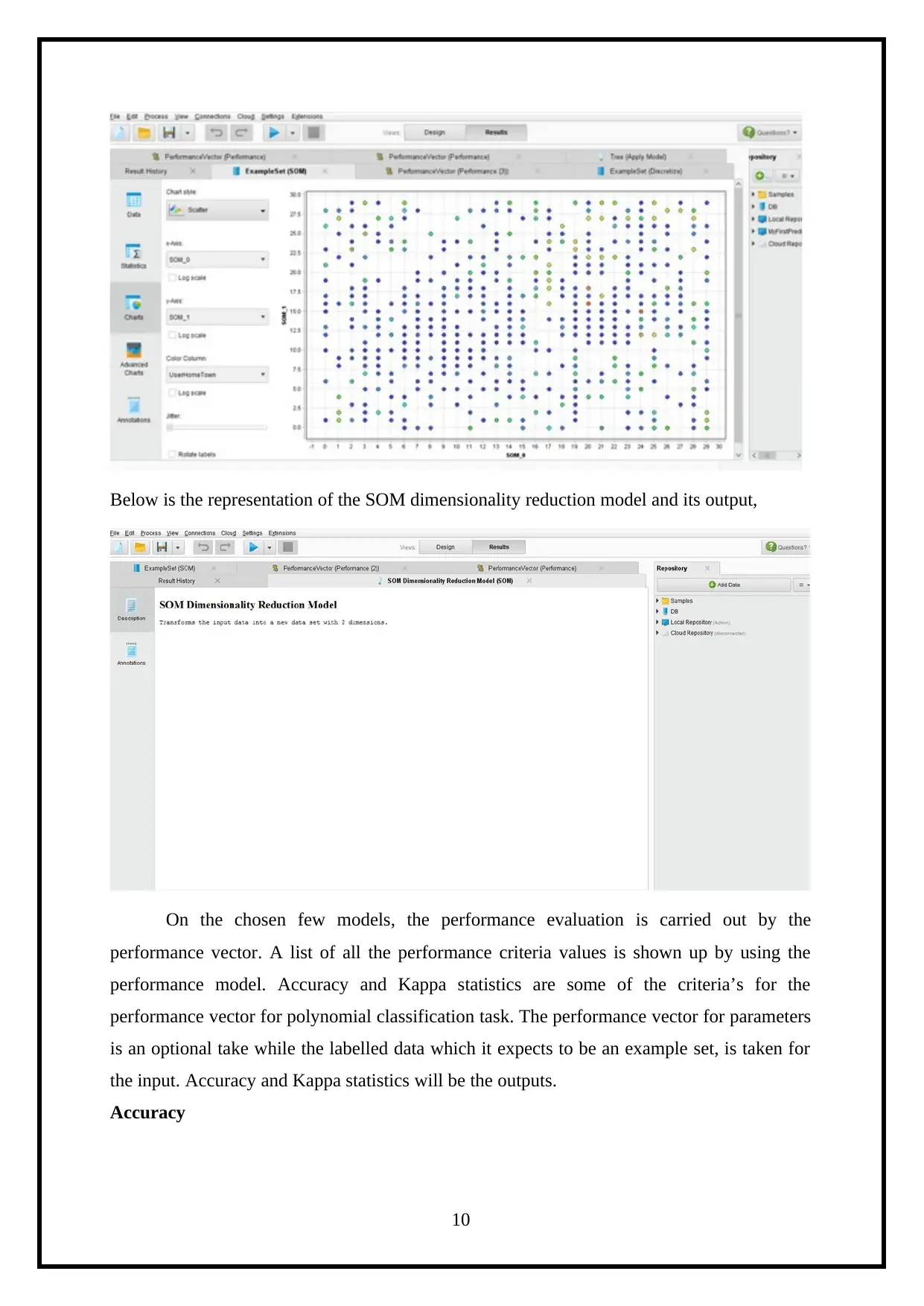
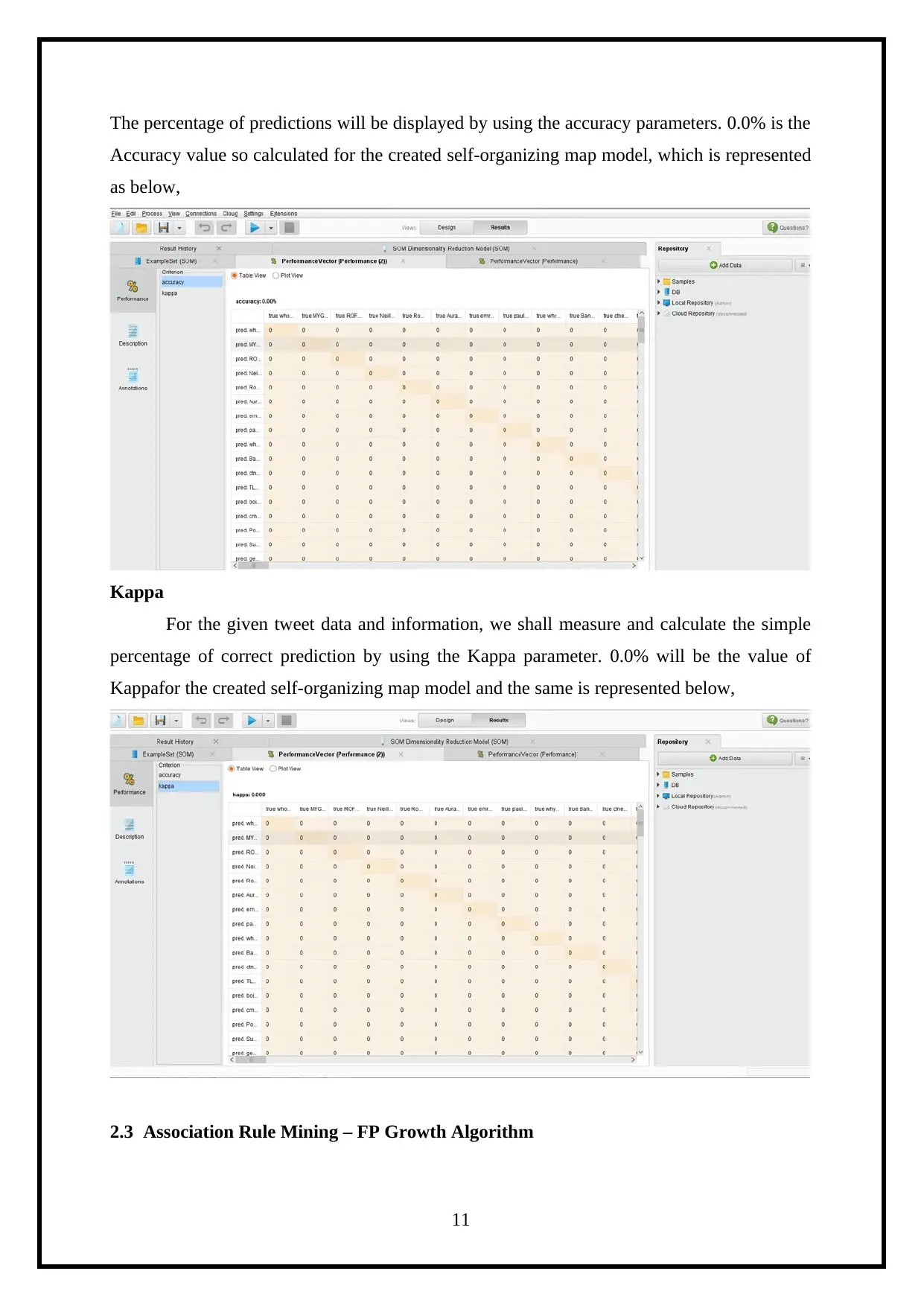
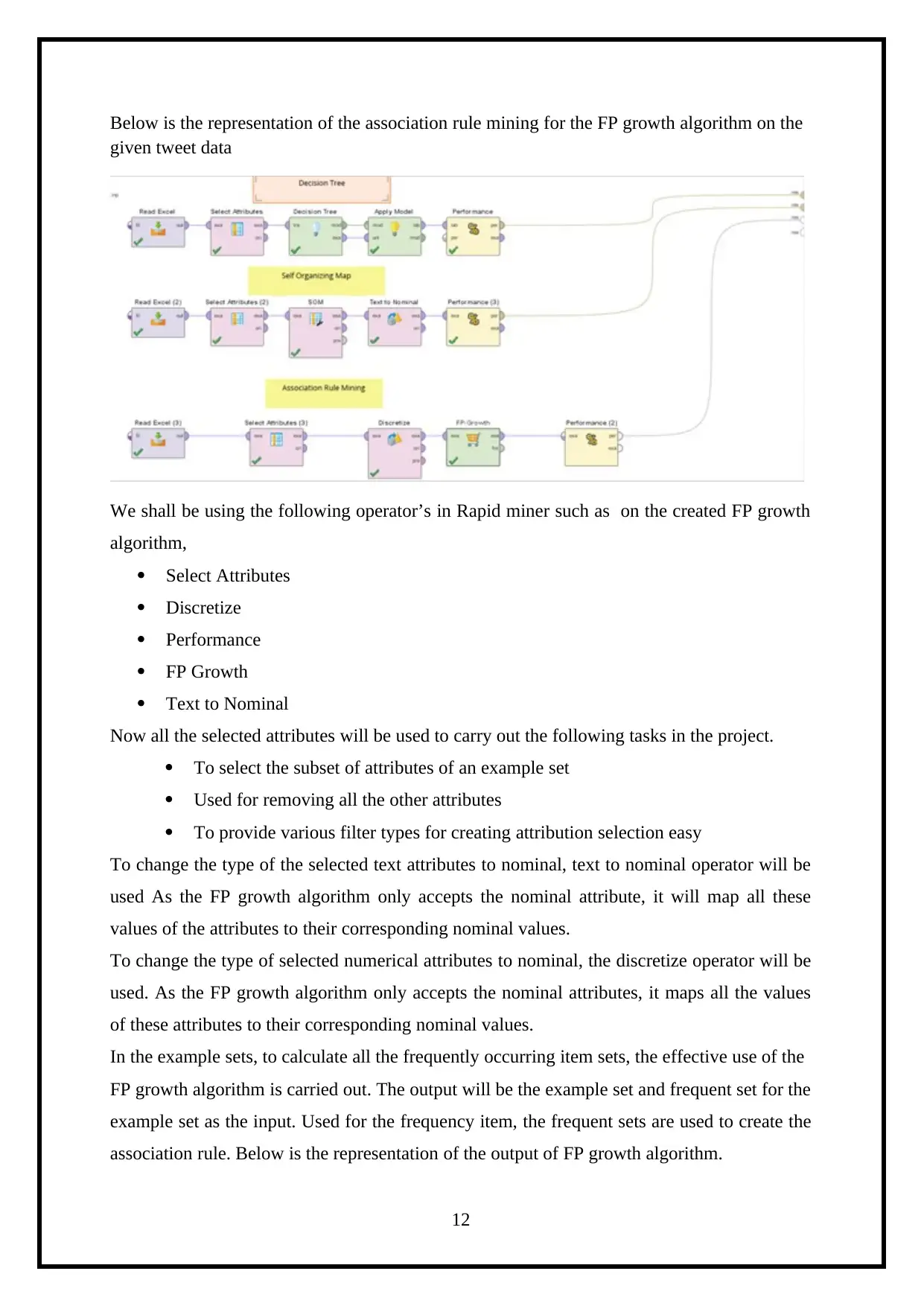
This report details a knowledge engineering assignment focused on analyzing Twitter data using the RapidMiner tool. The project aims to understand user online activity through their tweets. The report begins with an introduction to the context of social media and Twitter's role as a dynamic data source. It then outlines the business case, describing the tweet data attributes. The core of the report covers knowledge creation techniques, including classification using Decision Trees, clustering with Self-Organizing Maps (SOM), and association rule mining employing the FP Growth algorithm. Each technique is explained with relevant RapidMiner operators and visual representations of the results, such as accuracy and Kappa statistics. The report also discusses external source knowledge creations and concludes with an overview of the findings and references. The assignment showcases the application of data mining and machine learning techniques to extract meaningful insights from social media data. The report includes all the details of the assignment brief.







1 out of 20
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.