University Statistics: AMOS Analysis of Model Fit and Comparison
VerifiedAdded on 2023/01/07
|11
|1830
|80
Homework Assignment
AI Summary
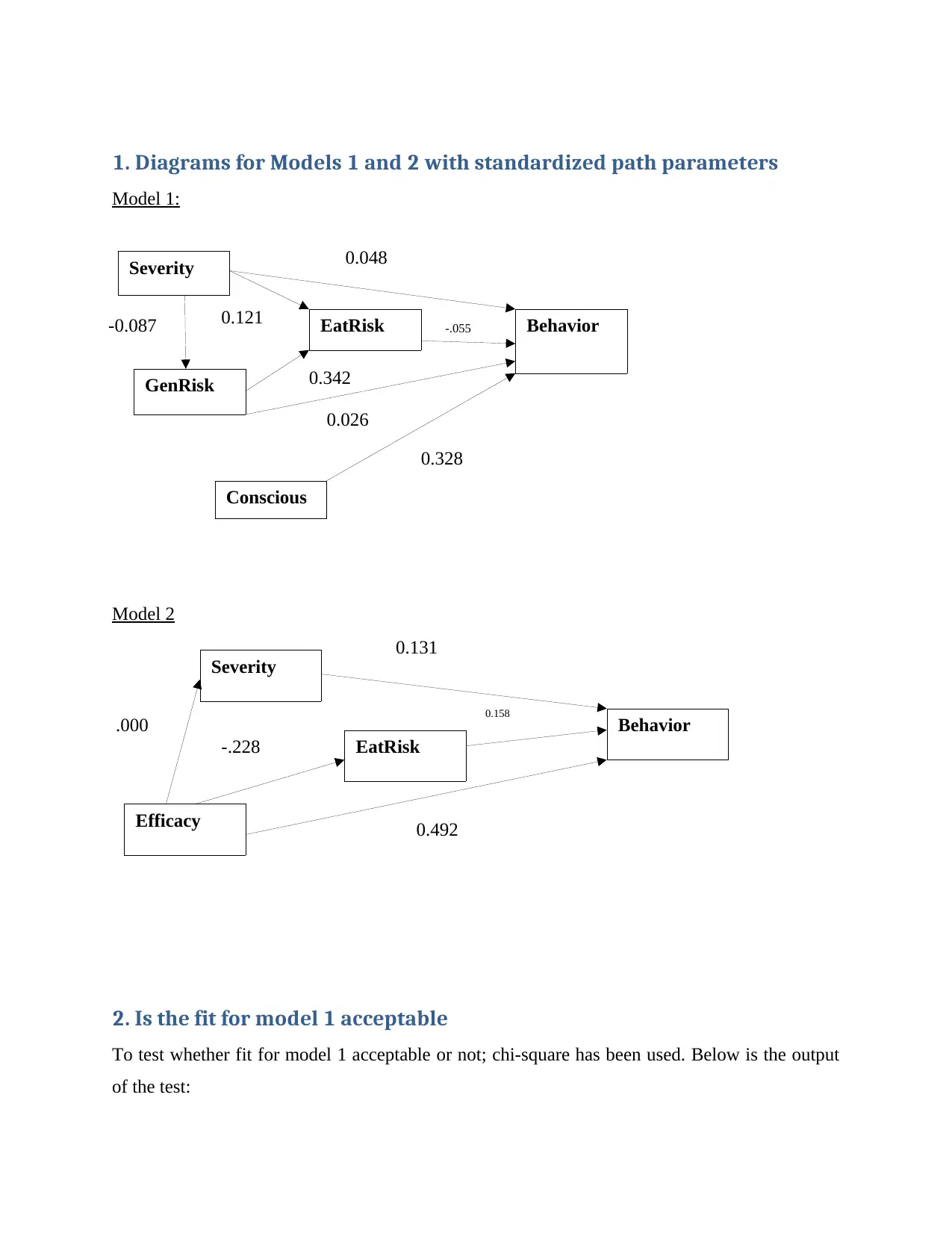
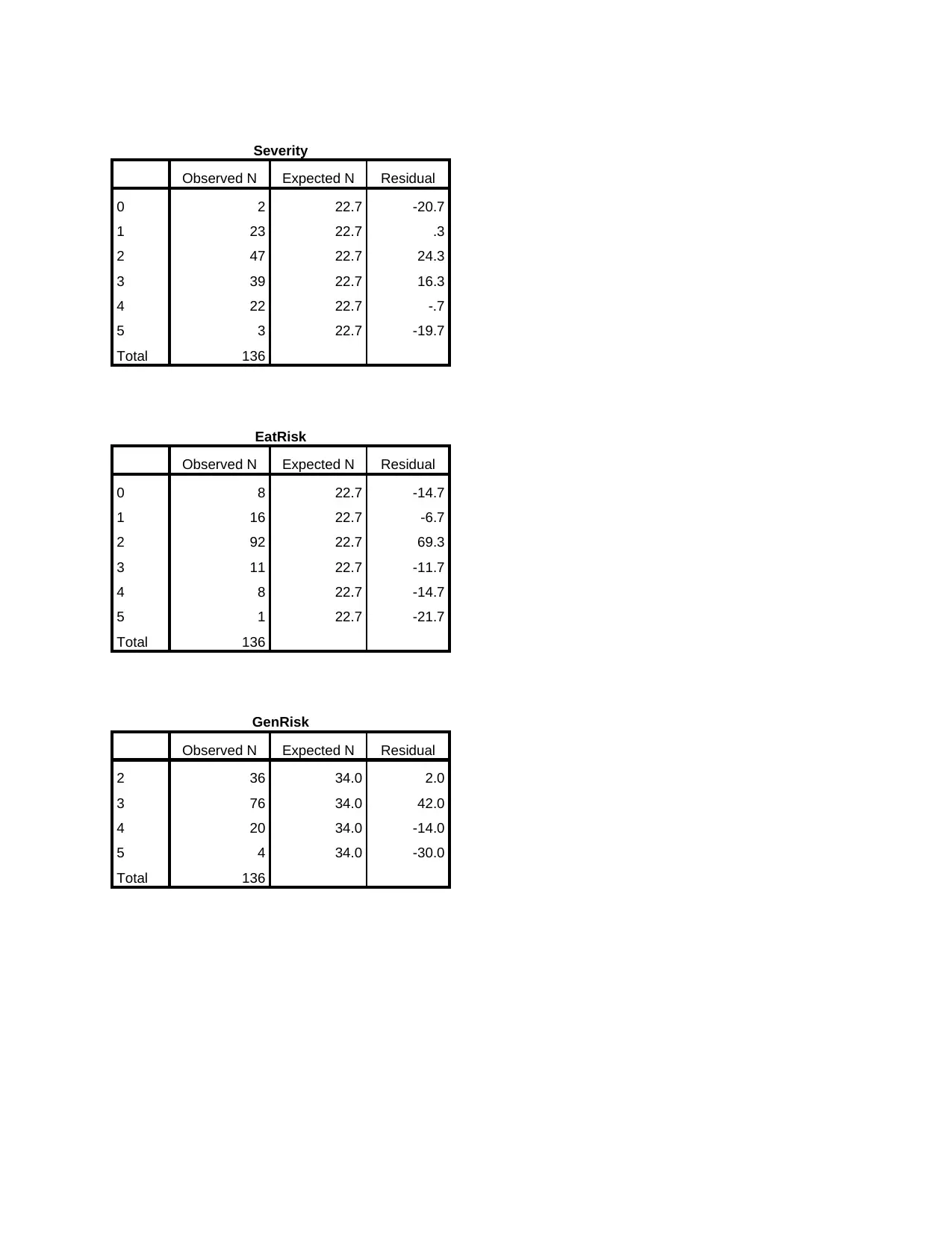
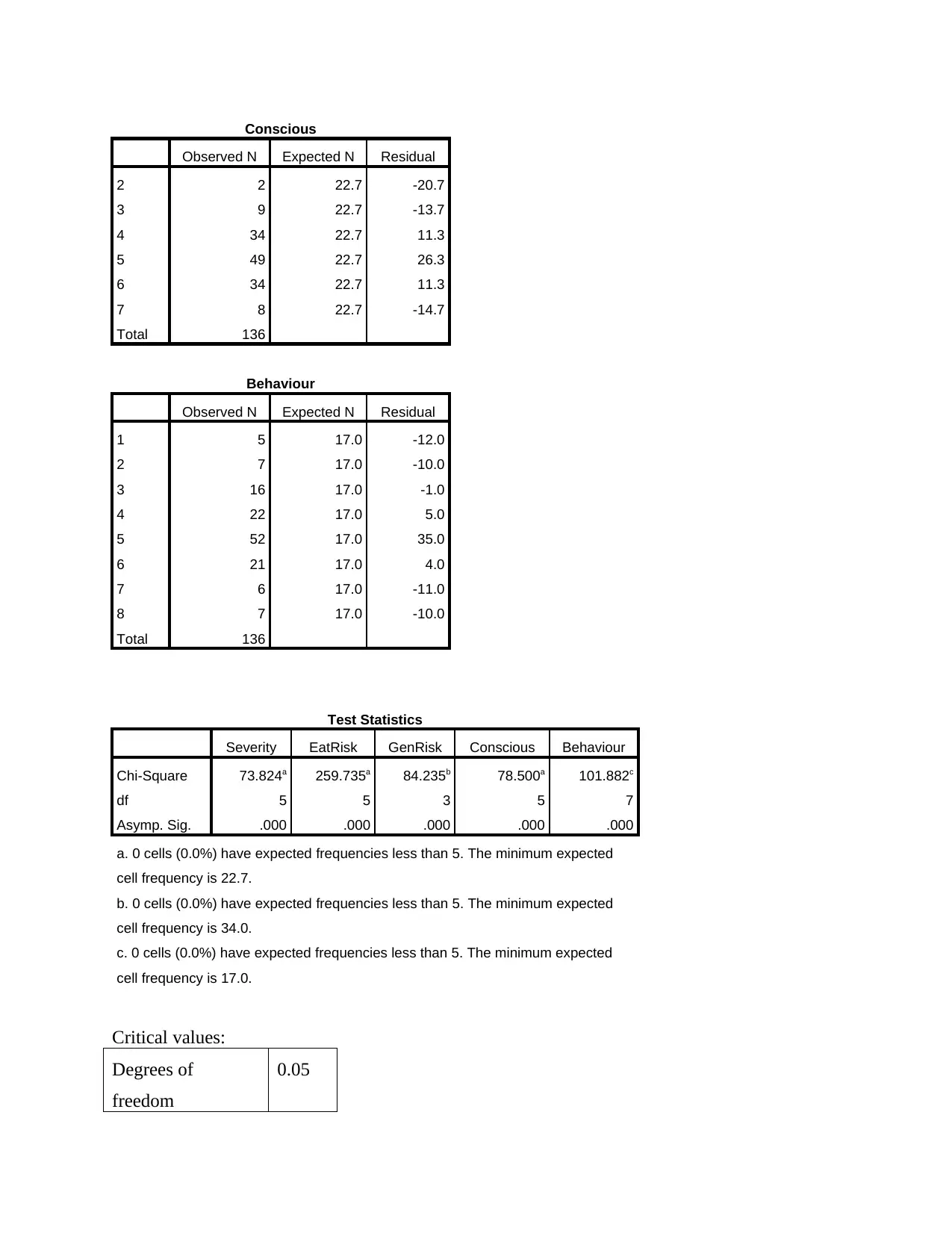
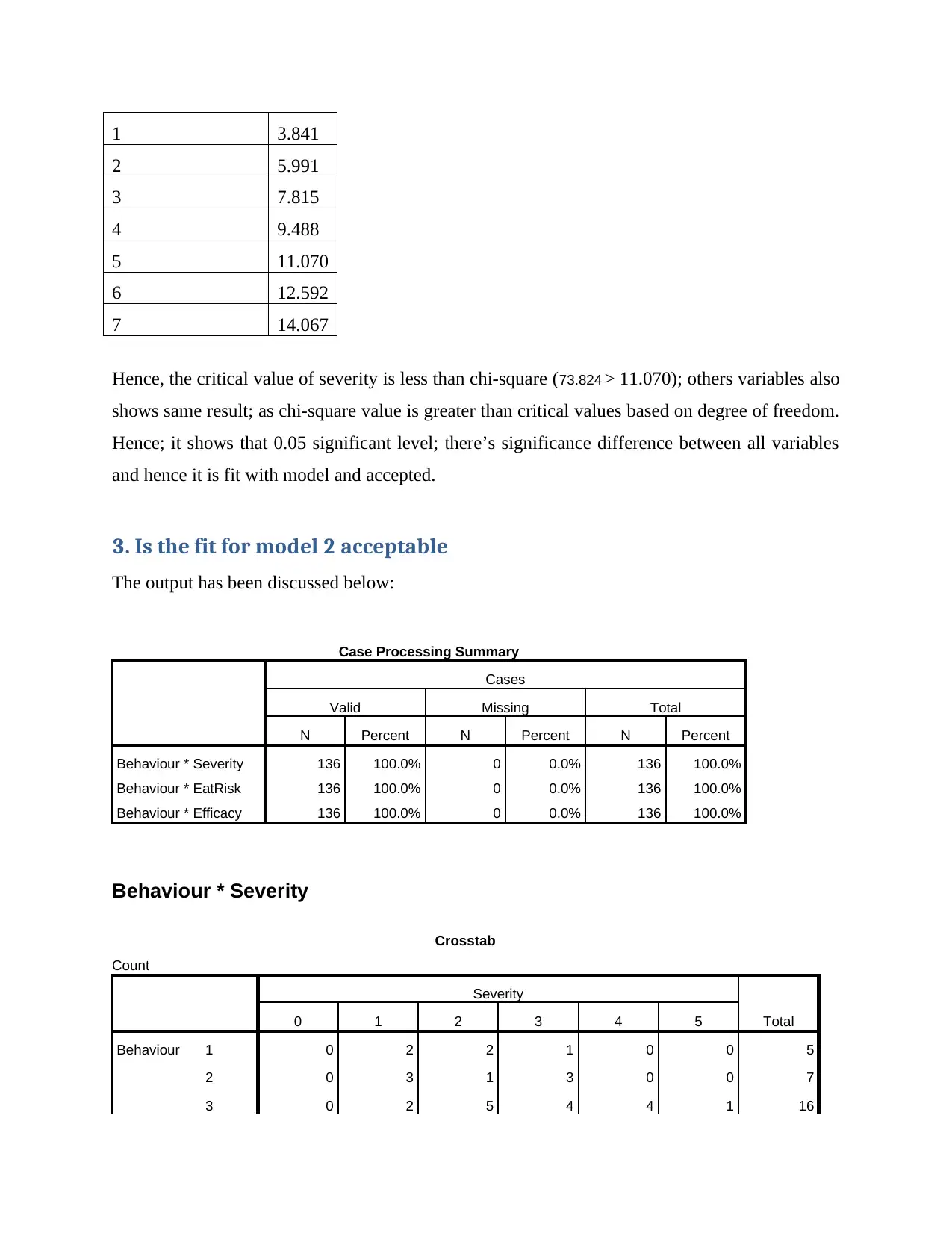
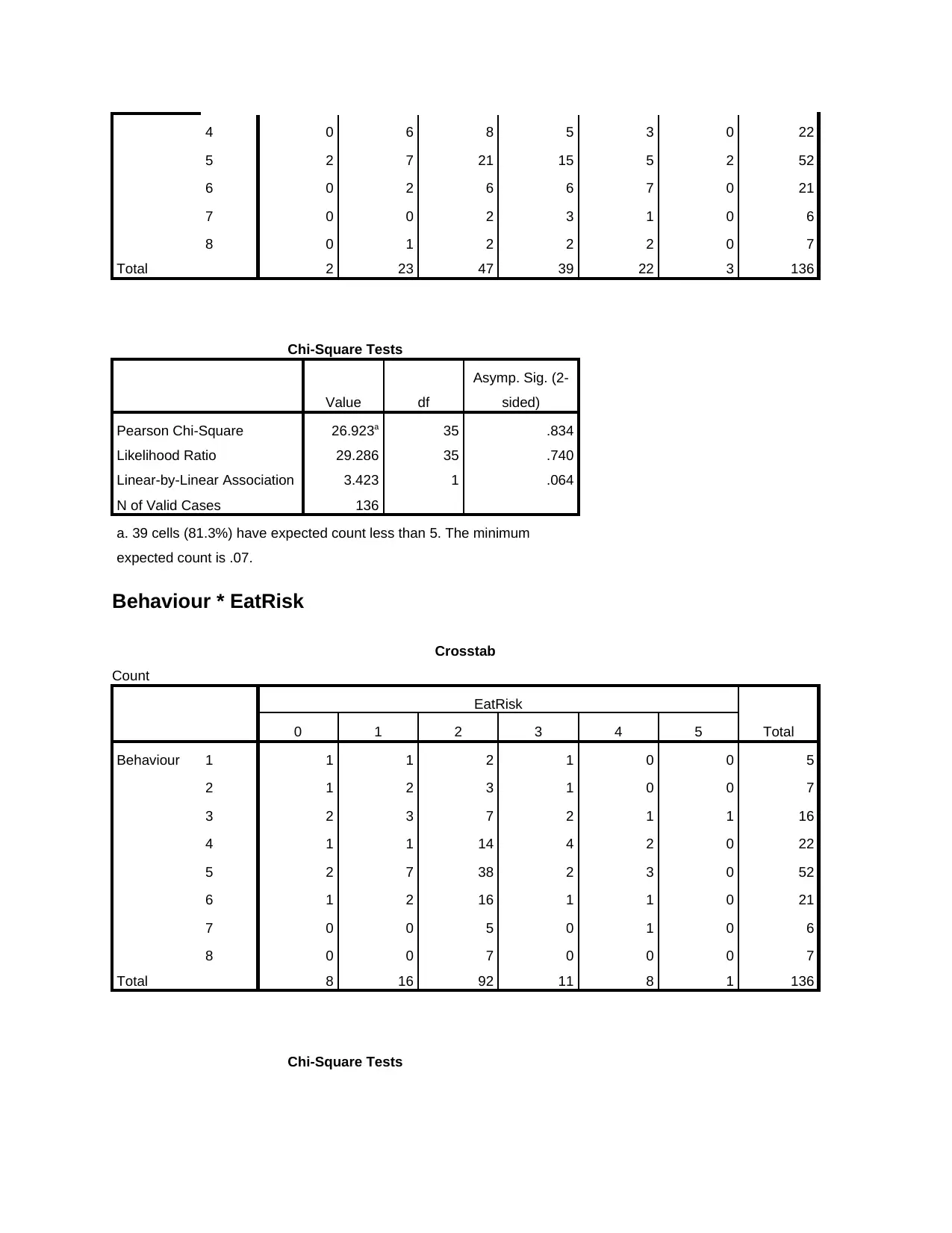
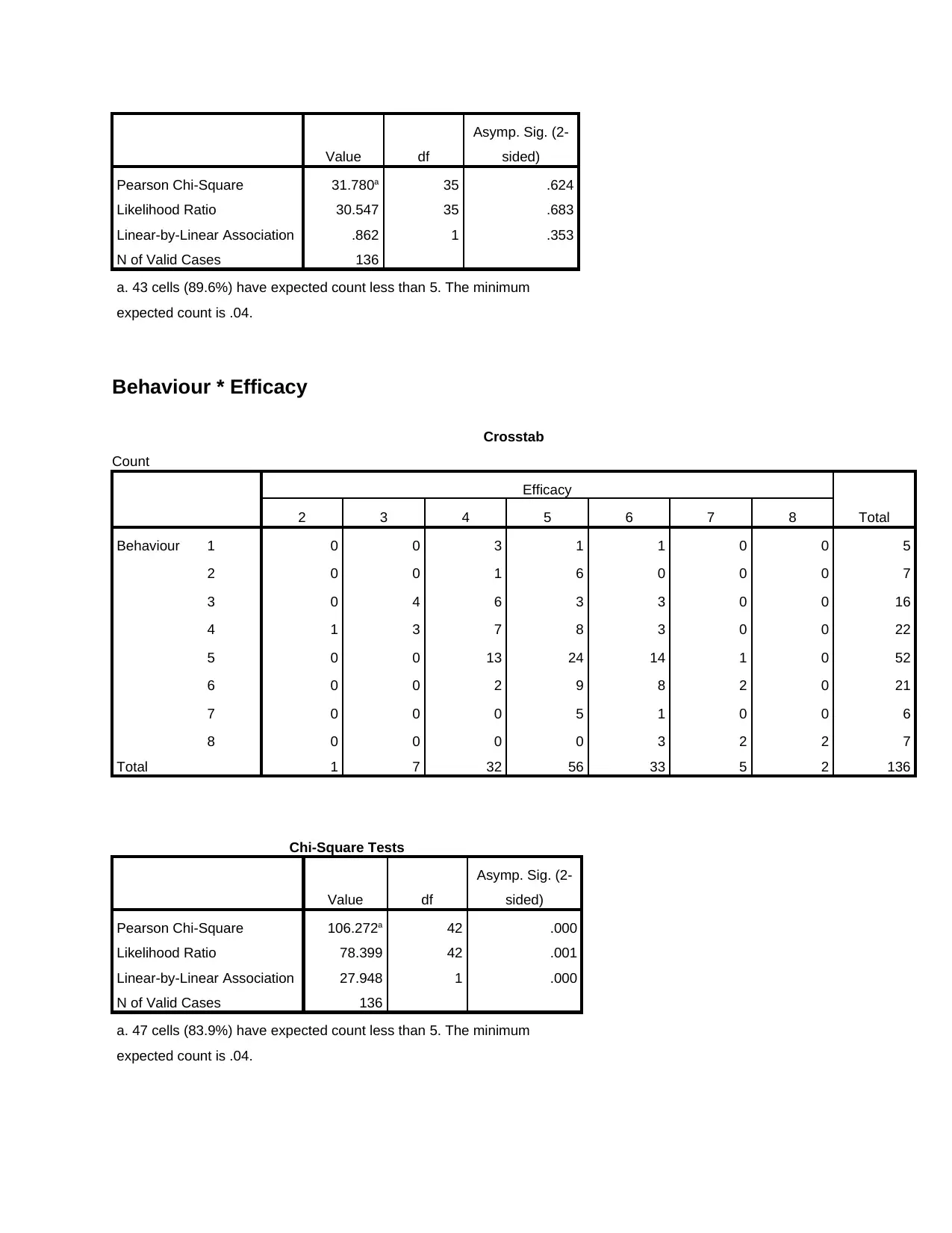
This assignment presents an analysis of two AMOS (Analysis of Moment Structures) models, focusing on their fit to the data and a comparison to determine which model is better. The analysis includes the evaluation of standardized path parameters for both models, followed by an assessment of the fit for each model using chi-square tests. The document details the chi-square test results for each variable in Model 1, including severity, EatRisk, GenRisk, and Conscious, and determines whether the fit is acceptable based on the critical values and degrees of freedom. Similarly, the analysis for Model 2 examines the fit based on chi-square tests for the relationships between Behavior and Severity, EatRisk, and Efficacy. The document identifies issues with Model 2, specifically highlighting that the chi-square values for Severity and EatRisk are less than critical values, indicating no significant difference. The assignment recommends improvements to the model, including the use of Goodness of Fit (GOF) statistics, and explores options for addressing model misfit. Finally, it concludes that Model 1 is the better fit based on the provided data and recommends its use for predicting behavior related to healthy eating.





1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.