Weka Analysis and Report: Data Science Module, Semester 1
VerifiedAdded on 2022/09/18
|7
|422
|34
Report
AI Summary
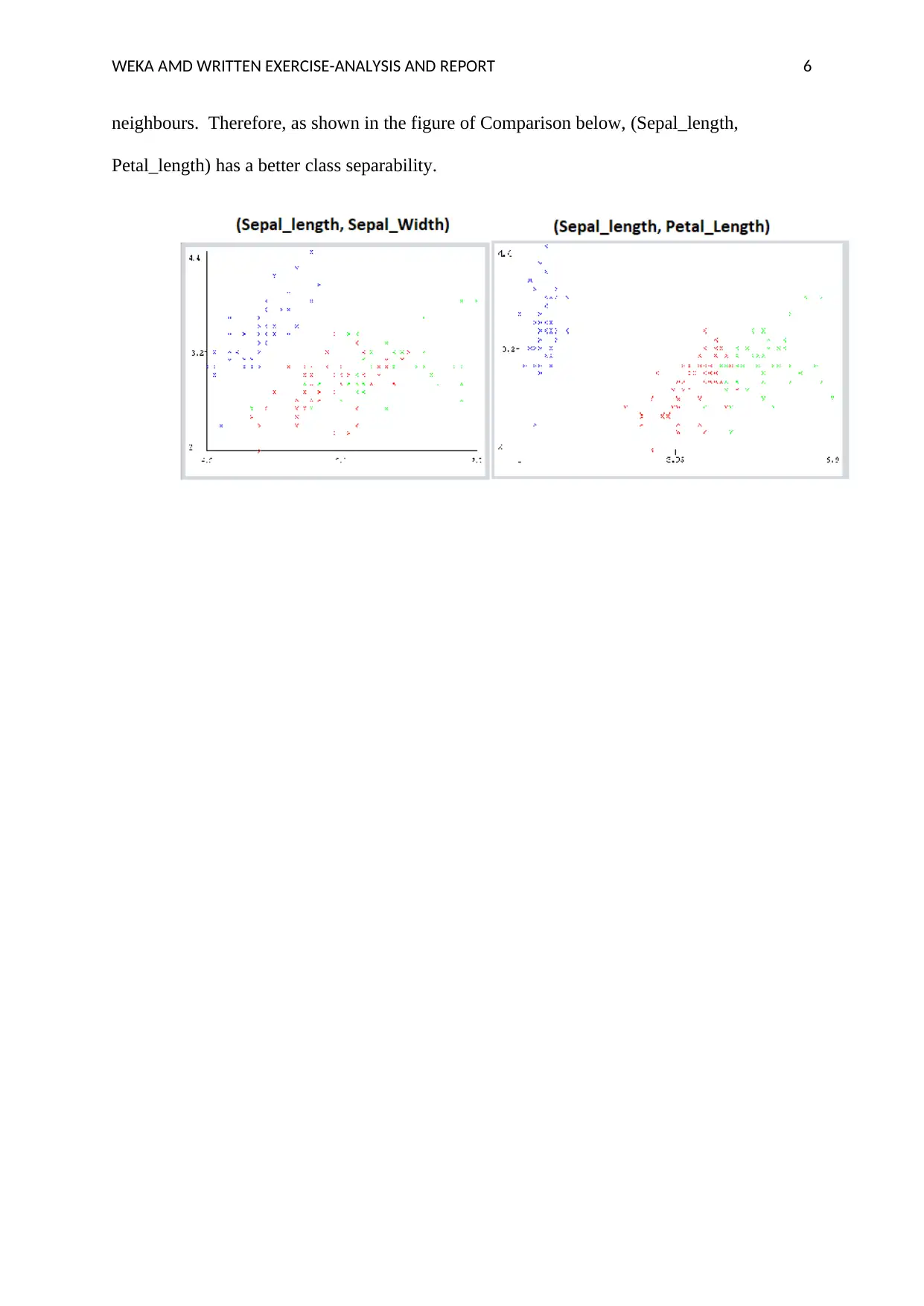
This report presents an analysis of a dataset using the Weka data mining software. The report begins with an overview of the dataset, including the number of instances, attributes, and classes. It then explores the attributes, visualizing the data using histograms and scatter plots. The analysis includes the removal of an attribute and the subsequent impact on the dataset. The report discusses class separability, demonstrating how different attributes contribute to the ability to distinguish between classes. The report also provides references to relevant literature on data mining and Weka. The analysis covers data exploration, attribute analysis, and data visualization techniques to derive meaningful insights from the dataset, and it concludes with a comparison of different plots and their effectiveness in representing the data.


1 out of 7
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.