Performance Analysis: Apriori Algorithm with Regression in Weka Tool
VerifiedAdded on 2020/03/07
|23
|3651
|71
Report
AI Summary
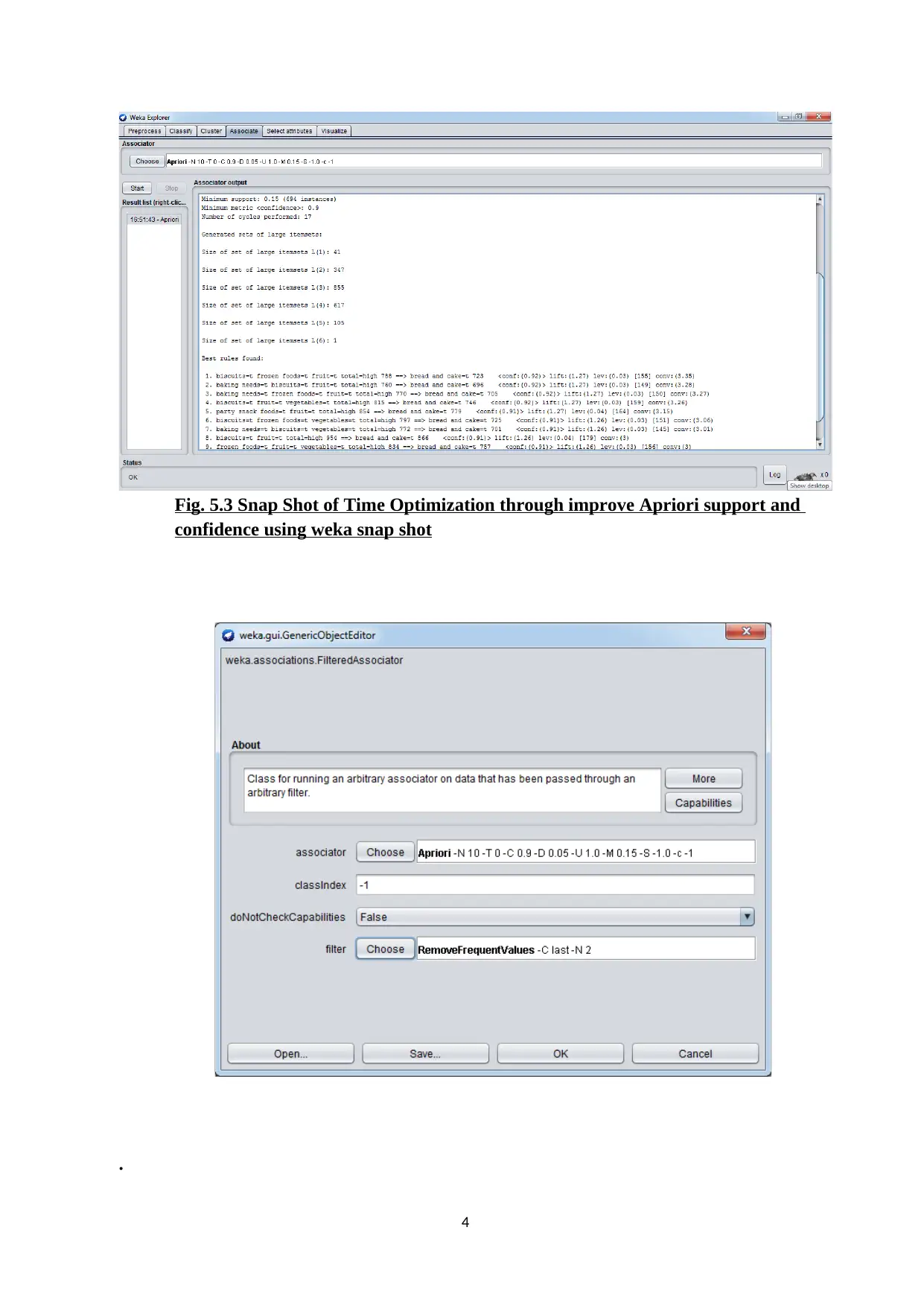
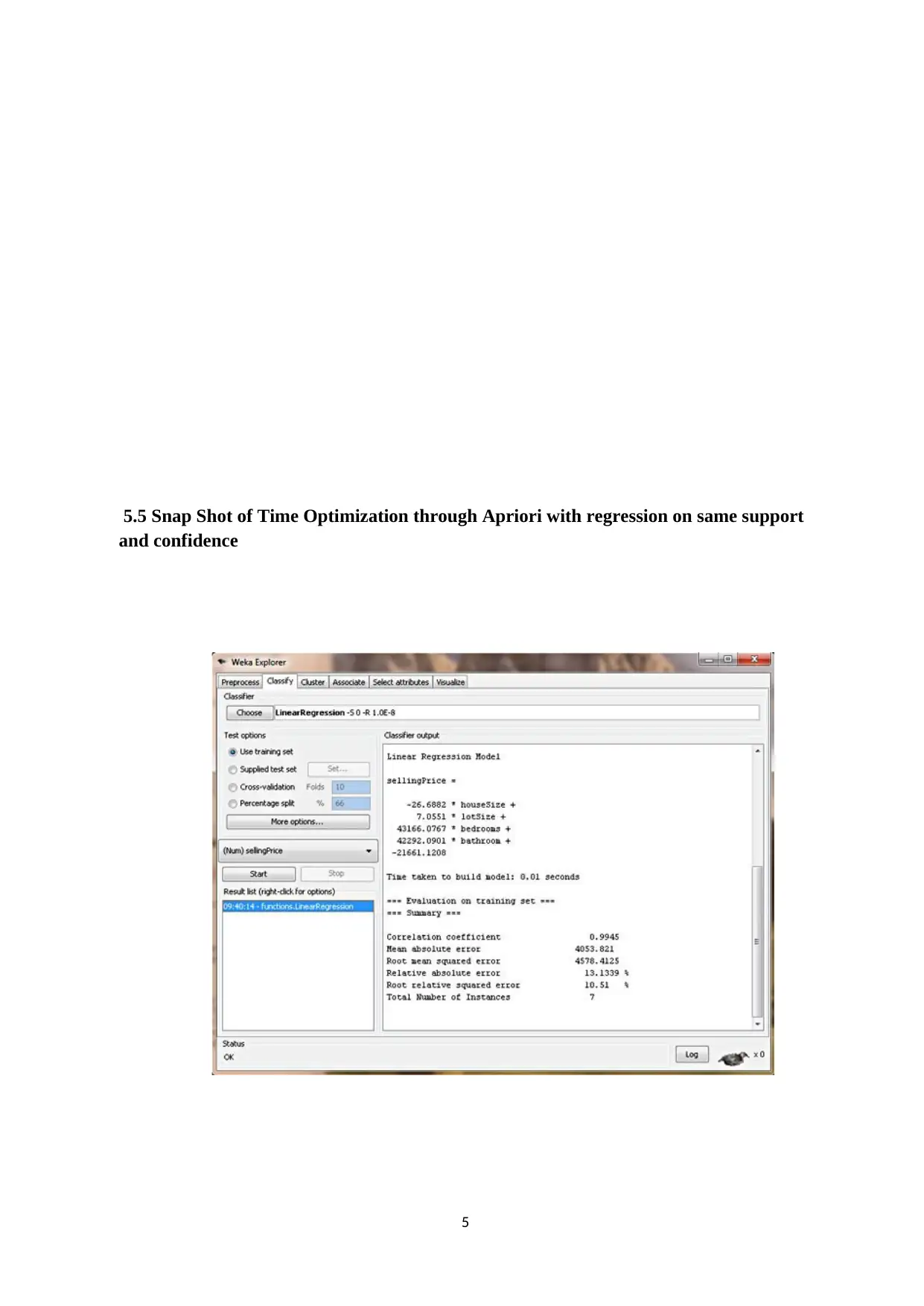
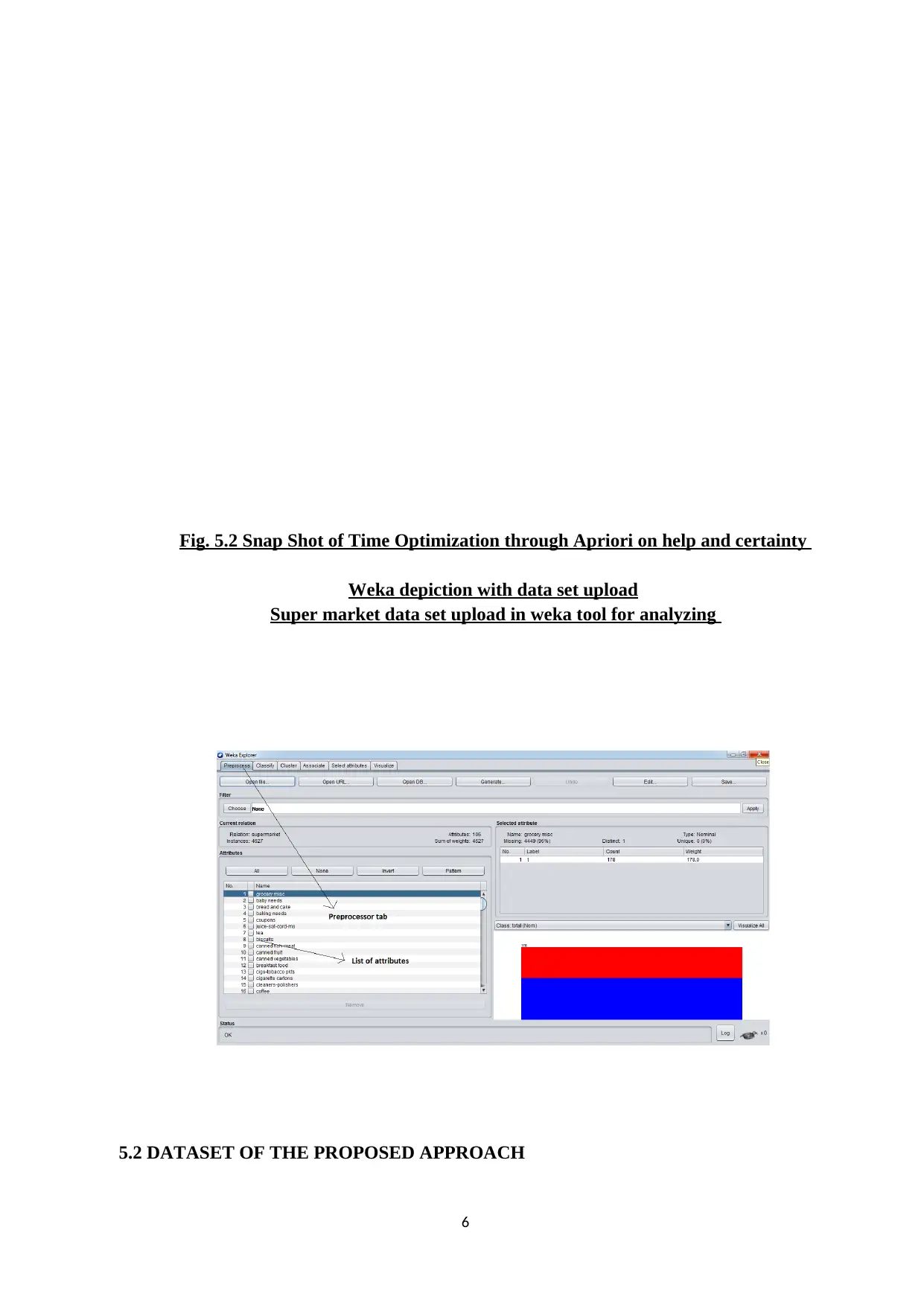
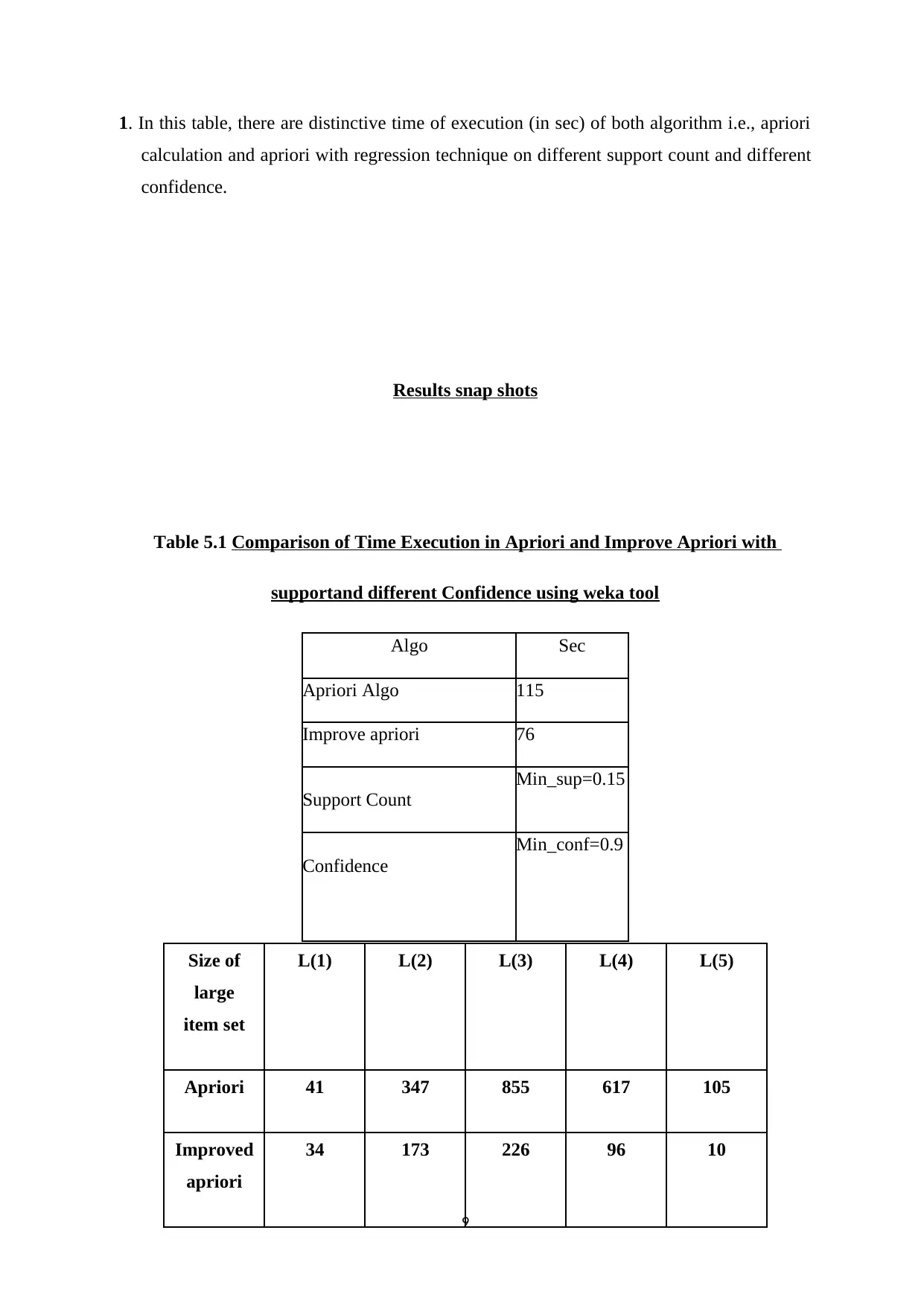
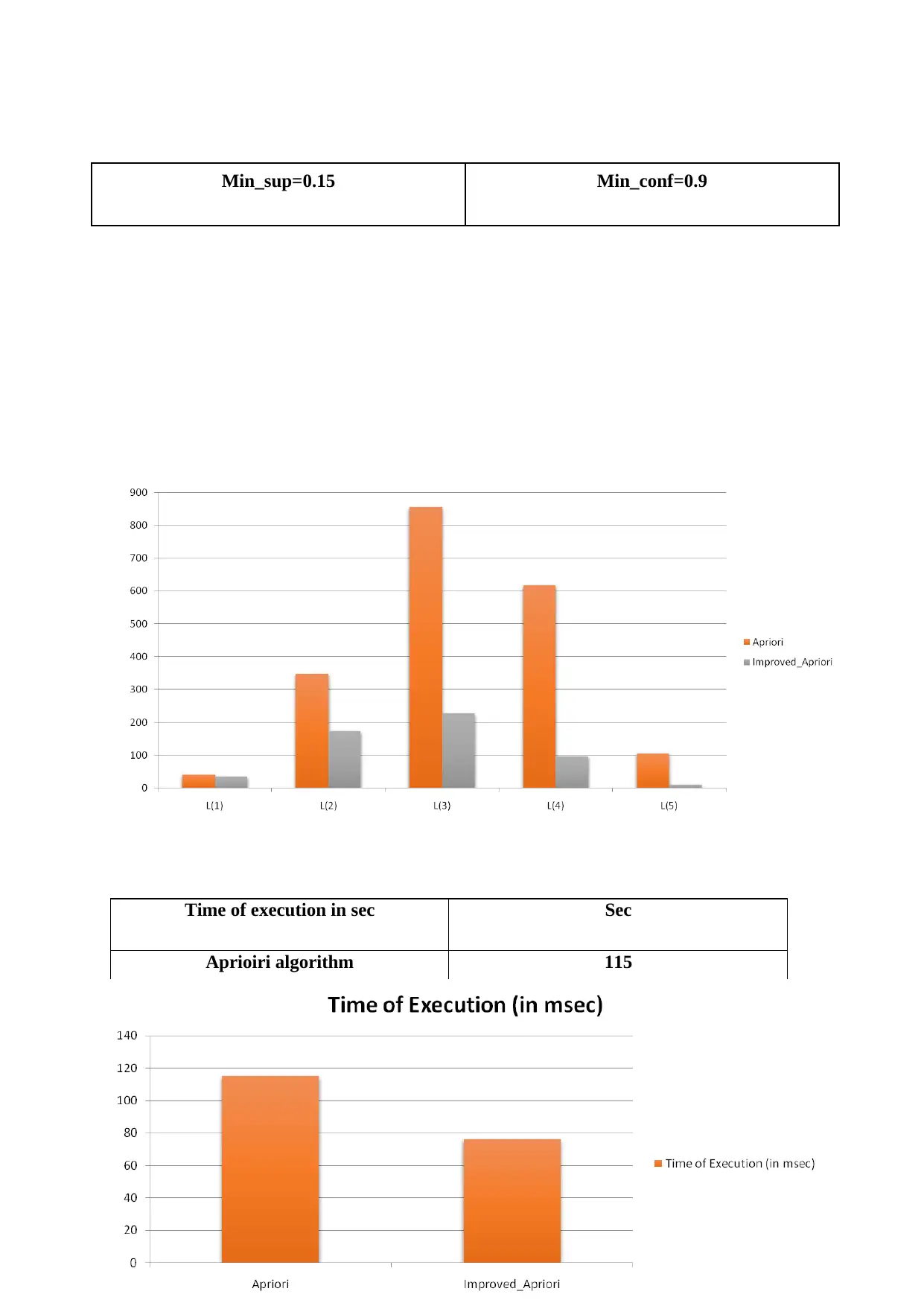
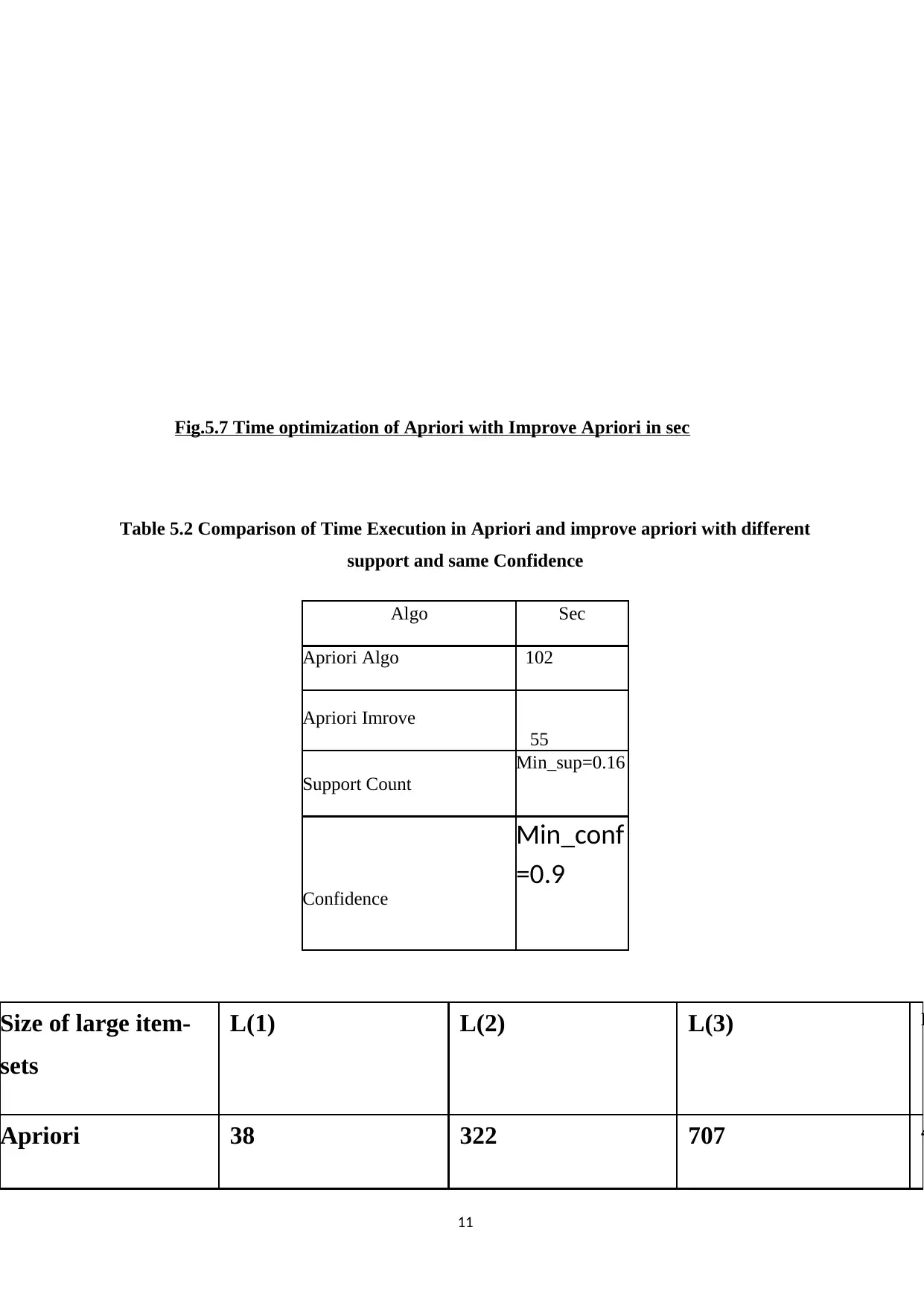
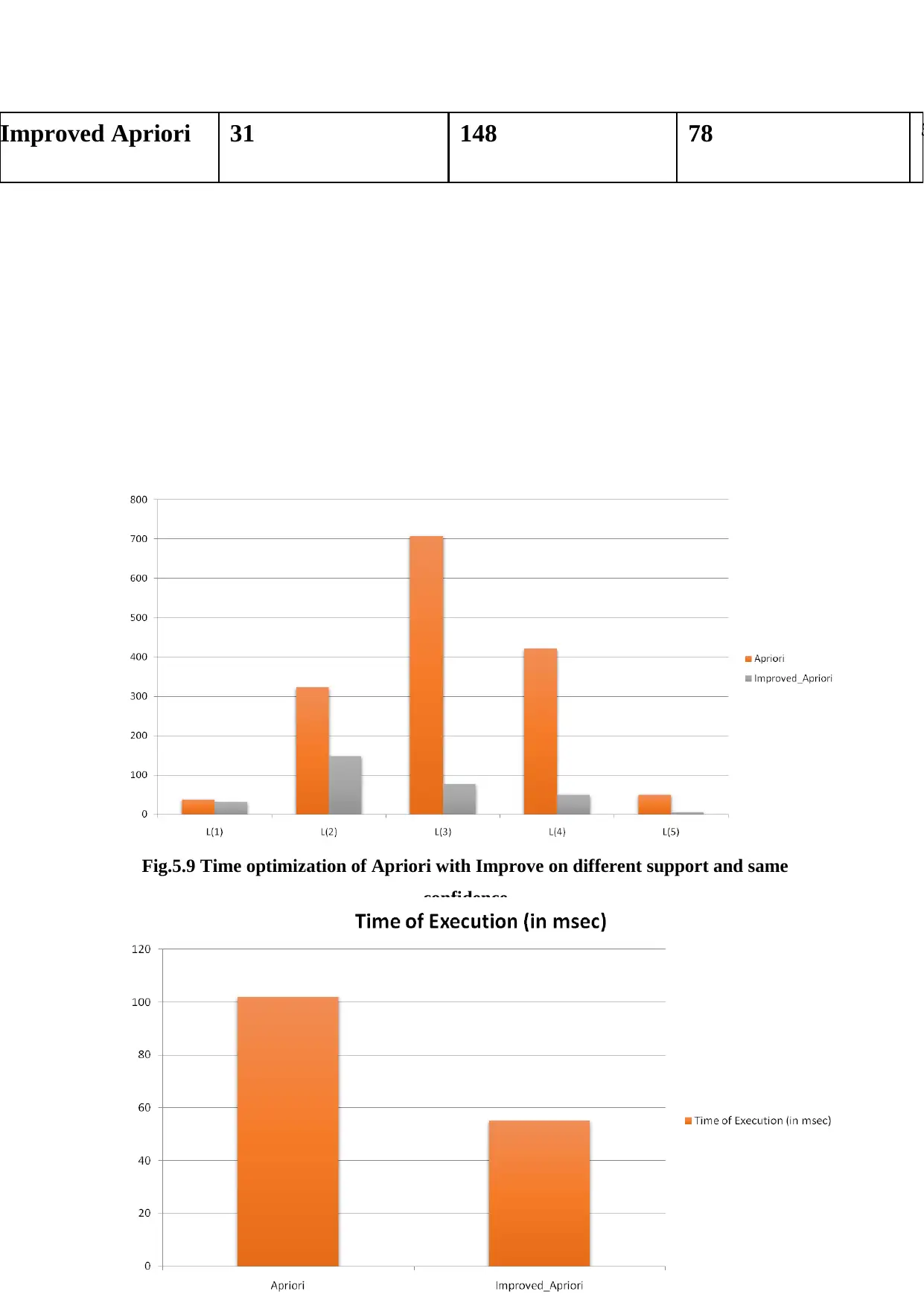
This report presents an experimental analysis of the Apriori algorithm and regression techniques implemented within the Weka tool. The study focuses on optimizing execution time when generating frequent patterns, strong rules, and maximal rules. The implementation uses synthetic and real datasets, including a supermarket dataset, to evaluate the performance of the algorithms under varying support and confidence levels. The report includes implementation snapshots, result tables, and graphs comparing the execution times of Apriori and improved Apriori algorithms, along with Apriori with regression. Key findings highlight the impact of different support and confidence values on the execution time, with a specific emphasis on how linear regression can reduce the execution time for item sets with a predicted confidence of zero. Additionally, the report touches upon big data concepts like clustering and association rule mining, with a focus on minimizing costs associated with big data processing.





1 out of 23
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.