Business Analysis Report: Data Mining with WEKA Tool for Loan Data
VerifiedAdded on 2020/05/08
|6
|1882
|203
Report
AI Summary
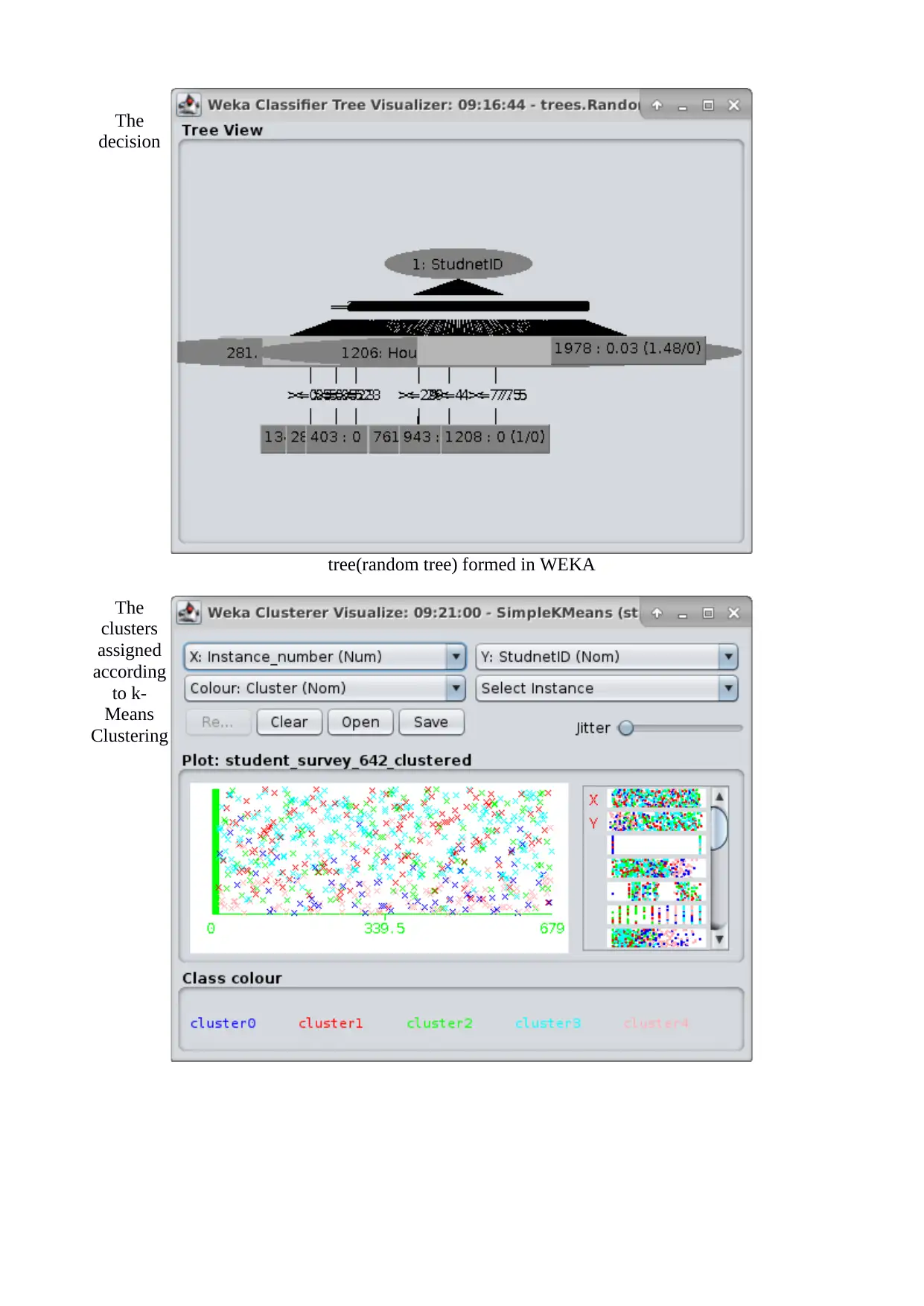
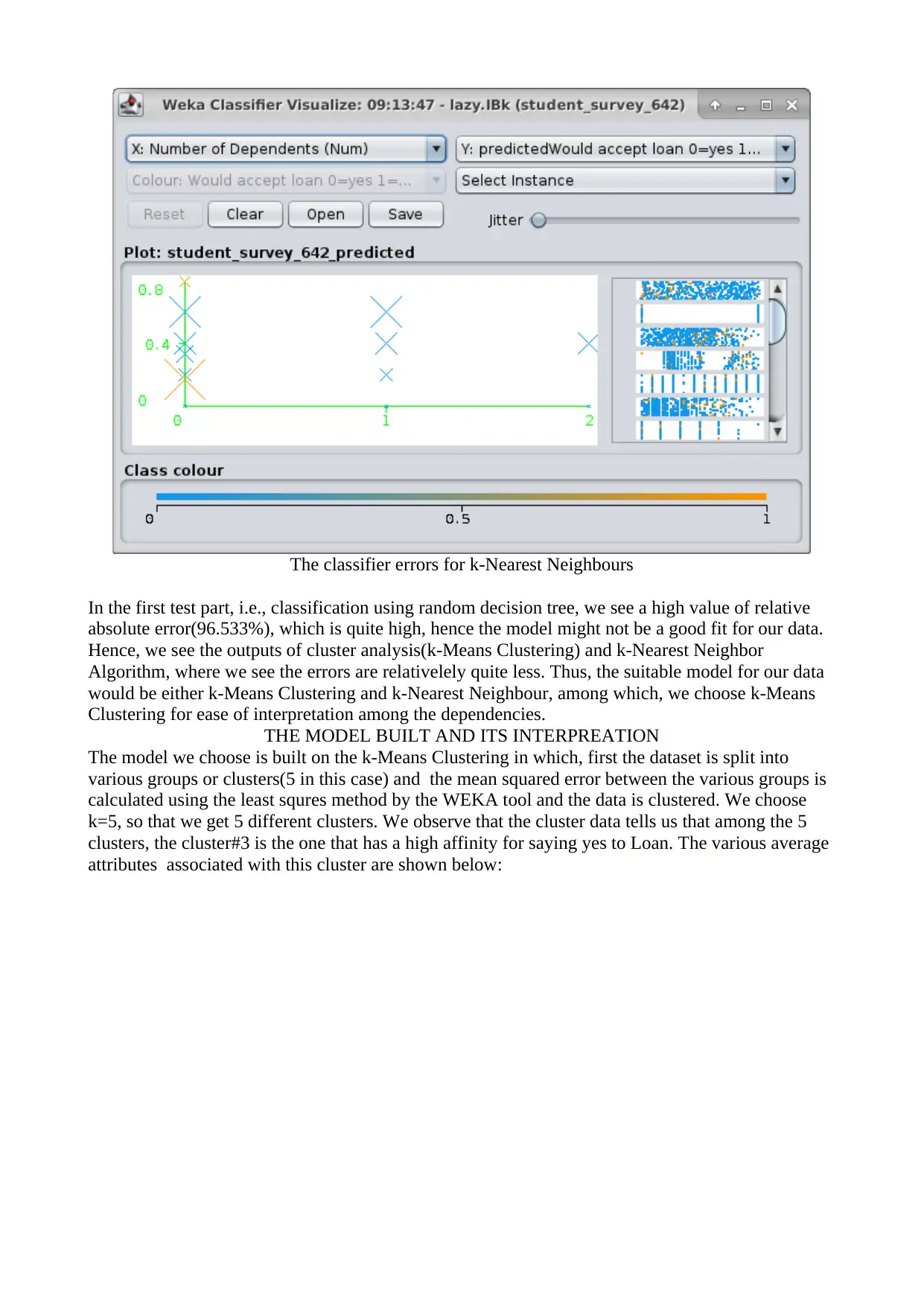
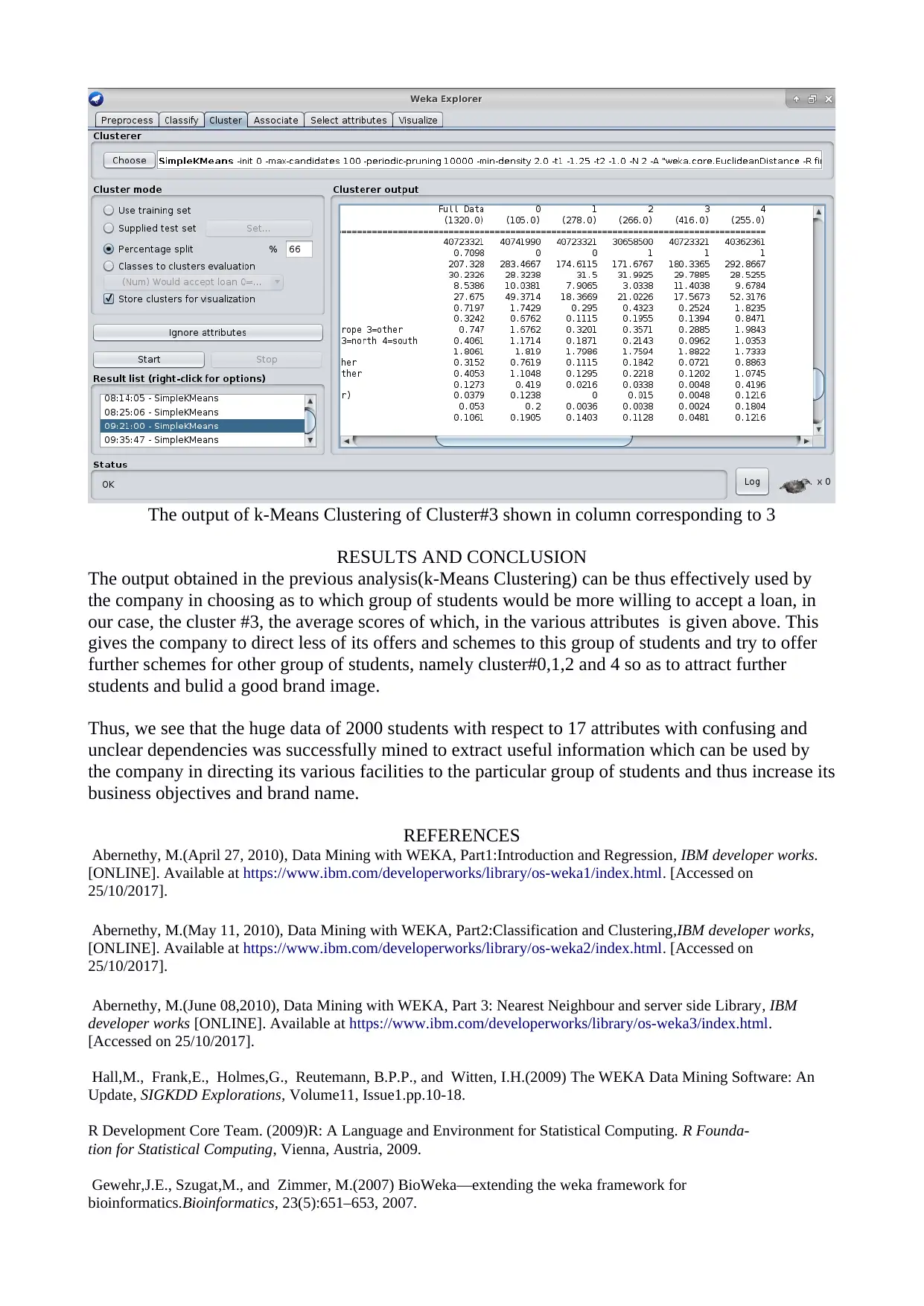
This report presents a business analysis of student loan data using the WEKA data mining tool. It begins with an introduction to data mining concepts, including directed and undirected approaches, and explains various techniques like descriptive statistics, cluster analysis, and classification. The report then details the data visualization and preprocessing steps, highlighting the challenges of interpreting scatter plots with categorical variables. The core of the report focuses on choosing an appropriate data mining model, discussing the suitability of linear regression, decision trees, k-means clustering, and k-Nearest Neighbors. The report describes the generation of test designs, splitting the data into training and testing sets, and presents the results of applying decision tree, k-Means Clustering, and k-Nearest Neighbors algorithms. The report concludes that k-Means Clustering provides the most interpretable model for the dataset. The model identified Cluster #3 as having a high affinity for accepting loans, and this information can be used to refine loan offering strategies. The report includes references to relevant academic and technical resources.


1 out of 6
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.