HA1011: Applied Quantitative Methods Assignment - Semester 2
VerifiedAdded on 2023/06/04
|14
|1060
|341
Homework Assignment
AI Summary
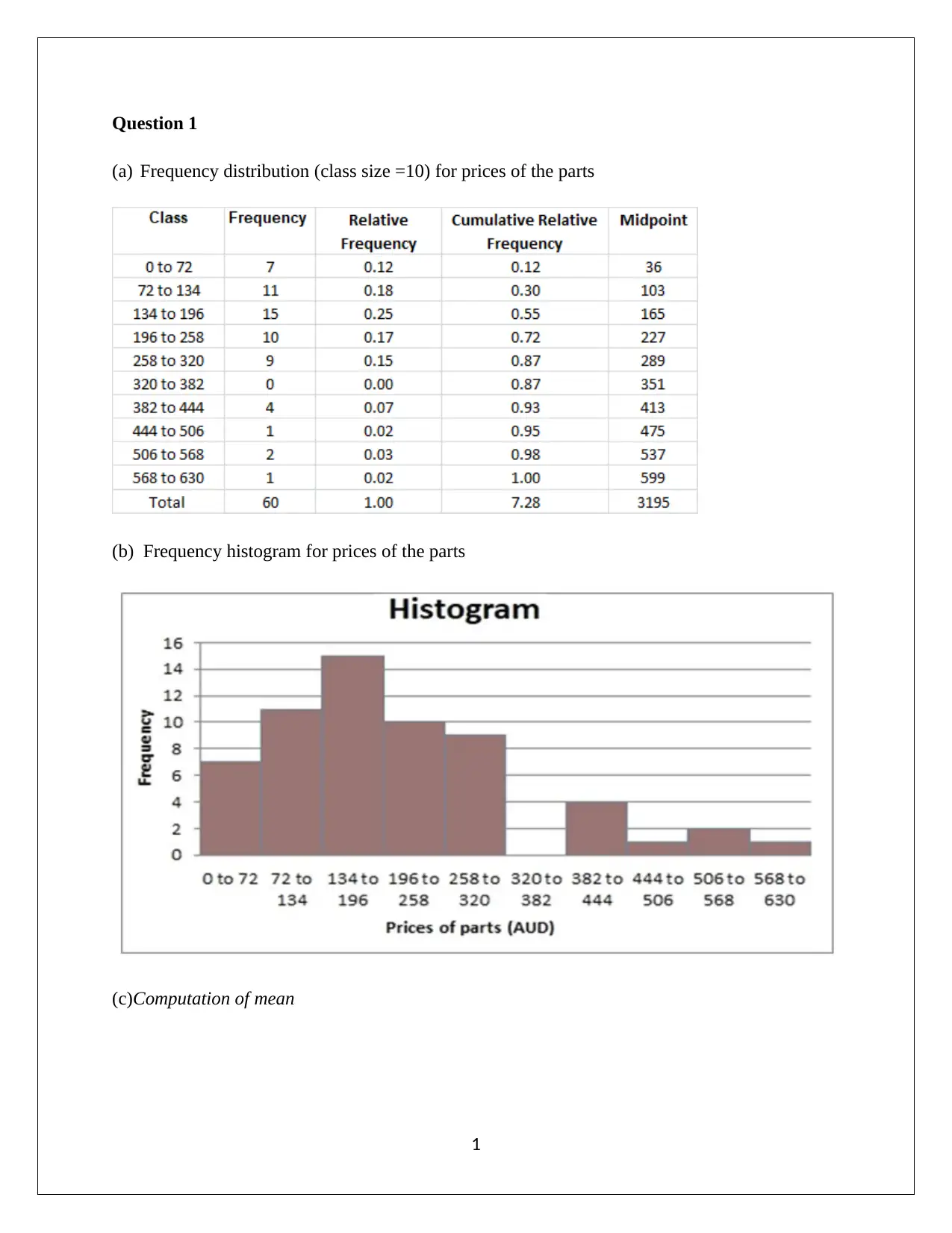
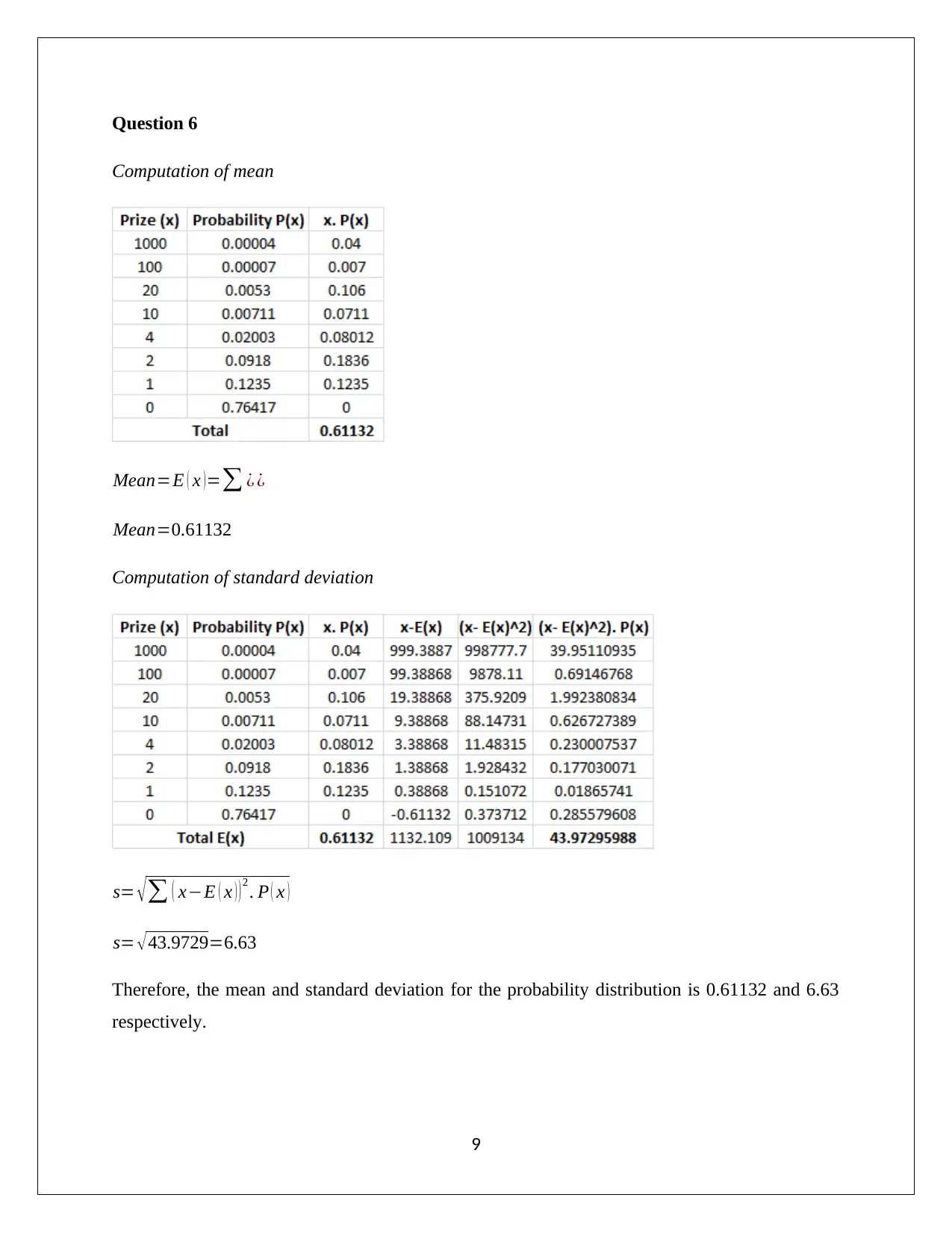
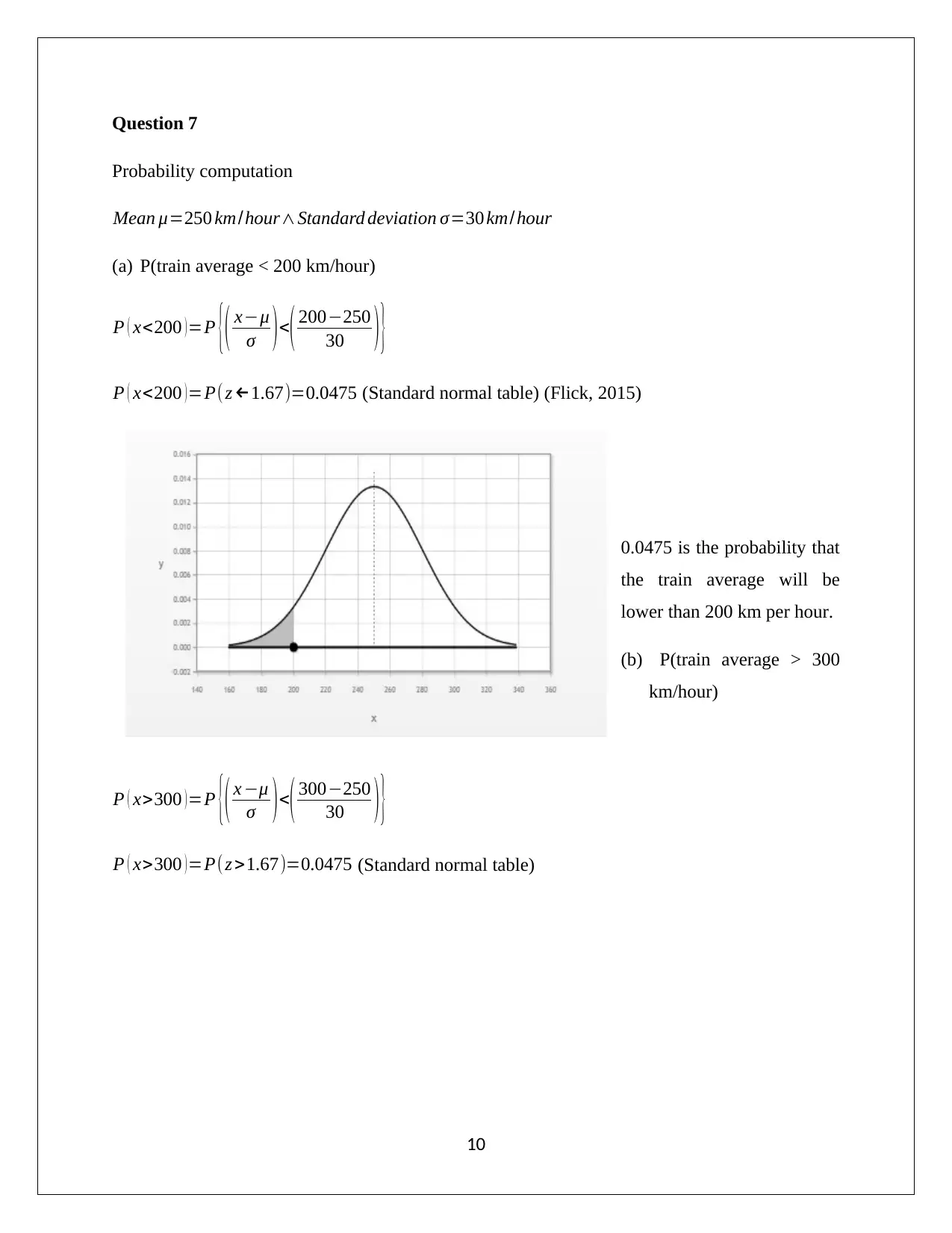
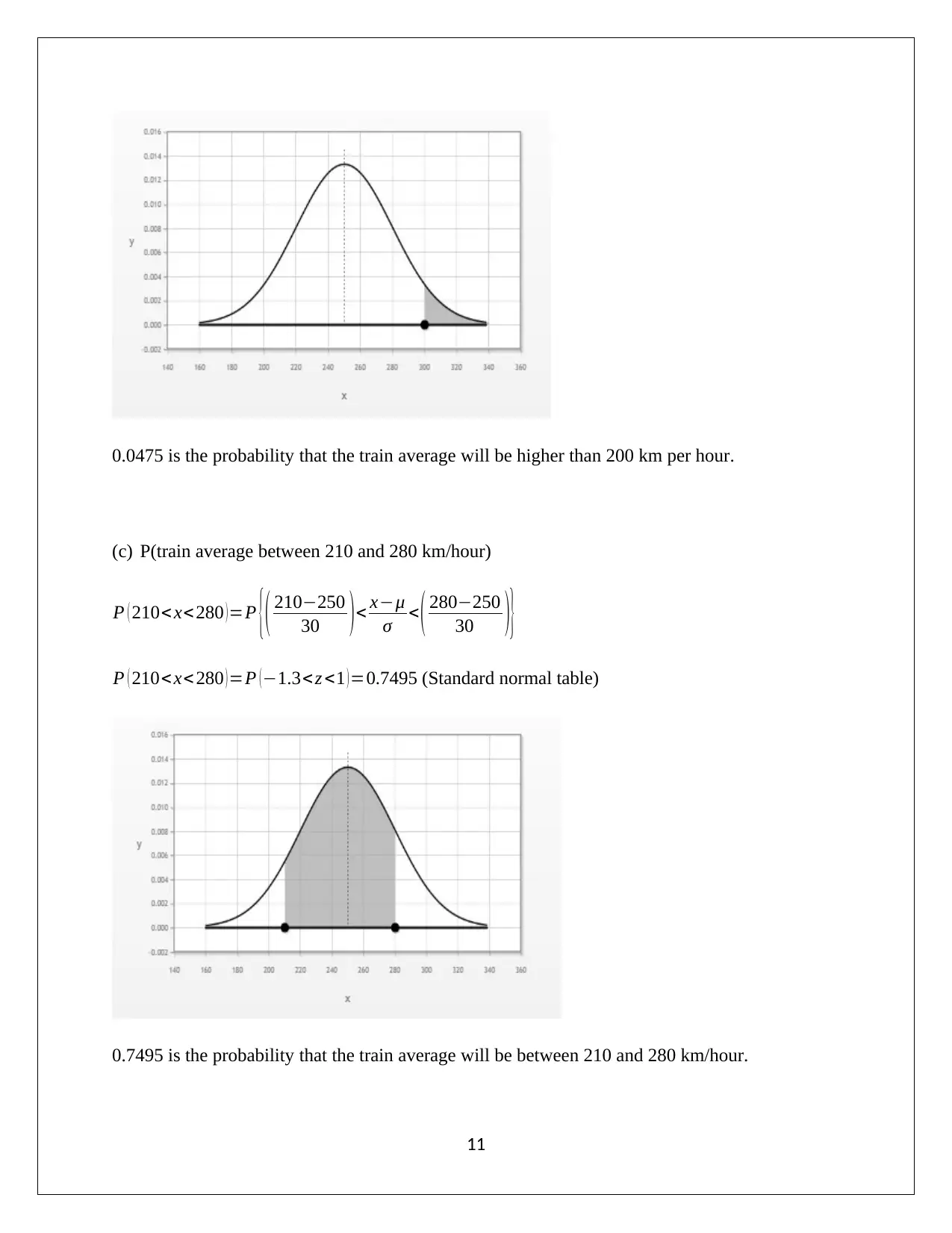
This document presents a complete solution to an Applied Quantitative Methods assignment, likely for a course like HA1011. The assignment covers a range of statistical concepts, including frequency distributions, histograms, and calculations of mean, median, and mode. It delves into sample data analysis, standard deviation, interquartile range (IQR), and correlation coefficients. The solution includes calculations for a least squares regression line and the coefficient of determination. Probability calculations are also provided, including conditional probabilities and the analysis of independent and dependent events. Furthermore, the assignment explores probability distributions, including calculations of mean, standard deviation, and probabilities related to the normal distribution. The document provides detailed interpretations and explanations for each step, supported by relevant references.








1 out of 14
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.