Taxation Assessment Report: Statistical Analysis and Recommendations
VerifiedAdded on 2020/07/22
|15
|2655
|86
Report
AI Summary
This assessment report provides a comprehensive analysis of taxation data, utilizing various statistical techniques. The report examines a sample of 60 individuals, analyzing variables such as gender, age, income, and lodgement method. Descriptive statistics, including mean, median, and standard deviation, are calculated for each variable. The report further explores confidence intervals, hypothesis testing, correlation, and regression analysis to determine relationships between variables. Key findings include the observation that a majority of taxpayers use tax agents, and the report concludes with recommendations for government initiatives to simplify the tax payment process. The report also uses tables and graphical representations to illustrate the data and findings.

Assessment Report- Taxation
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

EXECUTIVE SUMMARY
To analysing the dependency of people in terms of making the taxable payment is the prime
requirement of the government. In the preset report there has been analysis of various data set on
the basis of setting the frequencies and the various observations. Further, there will be
calculations relevant with correlation and regressions techniques which will help in determining
the appropriate relationship among the selected variables.
To analysing the dependency of people in terms of making the taxable payment is the prime
requirement of the government. In the preset report there has been analysis of various data set on
the basis of setting the frequencies and the various observations. Further, there will be
calculations relevant with correlation and regressions techniques which will help in determining
the appropriate relationship among the selected variables.

Table of Contents
PART A...........................................................................................................................................1
1 Selection of the random sample...............................................................................................1
2 Descriptive Statistics................................................................................................................2
PART B............................................................................................................................................3
3 Confidence Intervals................................................................................................................3
4 Hypothesis Testing...................................................................................................................4
5 Correlation................................................................................................................................5
CONCLUSION................................................................................................................................6
REFERENCES................................................................................................................................7
APPENDIX......................................................................................................................................8
PART A...........................................................................................................................................1
1 Selection of the random sample...............................................................................................1
2 Descriptive Statistics................................................................................................................2
PART B............................................................................................................................................3
3 Confidence Intervals................................................................................................................3
4 Hypothesis Testing...................................................................................................................4
5 Correlation................................................................................................................................5
CONCLUSION................................................................................................................................6
REFERENCES................................................................................................................................7
APPENDIX......................................................................................................................................8
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
PART A
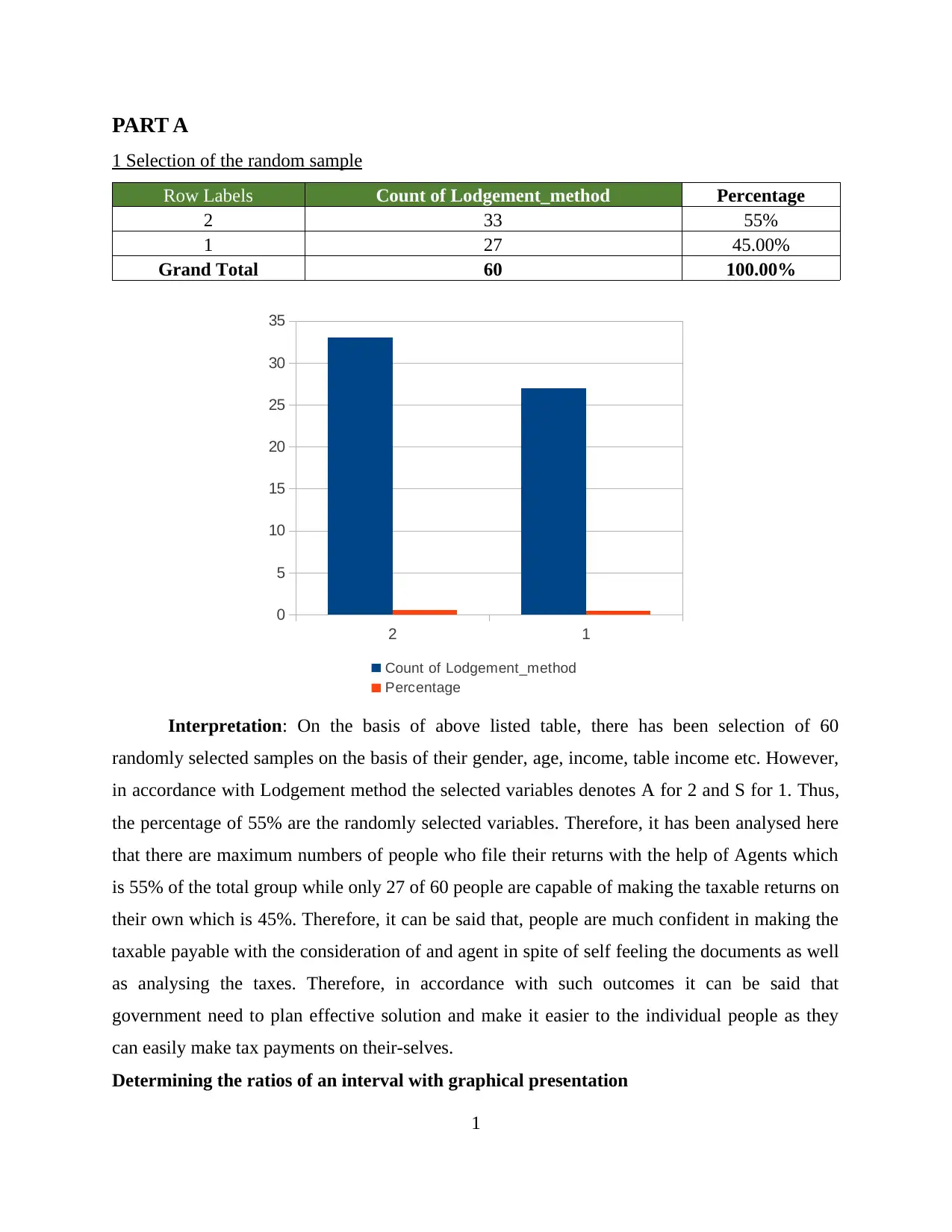
1 Selection of the random sample
Row Labels Count of Lodgement_method Percentage
2 33 55%
1 27 45.00%
Grand Total 60 100.00%
2 1
0
5
10
15
20
25
30
35
Count of Lodgement_method
Percentage
Interpretation: On the basis of above listed table, there has been selection of 60
randomly selected samples on the basis of their gender, age, income, table income etc. However,
in accordance with Lodgement method the selected variables denotes A for 2 and S for 1. Thus,
the percentage of 55% are the randomly selected variables. Therefore, it has been analysed here
that there are maximum numbers of people who file their returns with the help of Agents which
is 55% of the total group while only 27 of 60 people are capable of making the taxable returns on
their own which is 45%. Therefore, it can be said that, people are much confident in making the
taxable payable with the consideration of and agent in spite of self feeling the documents as well
as analysing the taxes. Therefore, in accordance with such outcomes it can be said that
government need to plan effective solution and make it easier to the individual people as they
can easily make tax payments on their-selves.
Determining the ratios of an interval with graphical presentation
1
1 Selection of the random sample
Row Labels Count of Lodgement_method Percentage
2 33 55%
1 27 45.00%
Grand Total 60 100.00%
2 1
0
5
10
15
20
25
30
35
Count of Lodgement_method
Percentage
Interpretation: On the basis of above listed table, there has been selection of 60
randomly selected samples on the basis of their gender, age, income, table income etc. However,
in accordance with Lodgement method the selected variables denotes A for 2 and S for 1. Thus,
the percentage of 55% are the randomly selected variables. Therefore, it has been analysed here
that there are maximum numbers of people who file their returns with the help of Agents which
is 55% of the total group while only 27 of 60 people are capable of making the taxable returns on
their own which is 45%. Therefore, it can be said that, people are much confident in making the
taxable payable with the consideration of and agent in spite of self feeling the documents as well
as analysing the taxes. Therefore, in accordance with such outcomes it can be said that
government need to plan effective solution and make it easier to the individual people as they
can easily make tax payments on their-selves.
Determining the ratios of an interval with graphical presentation
1
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
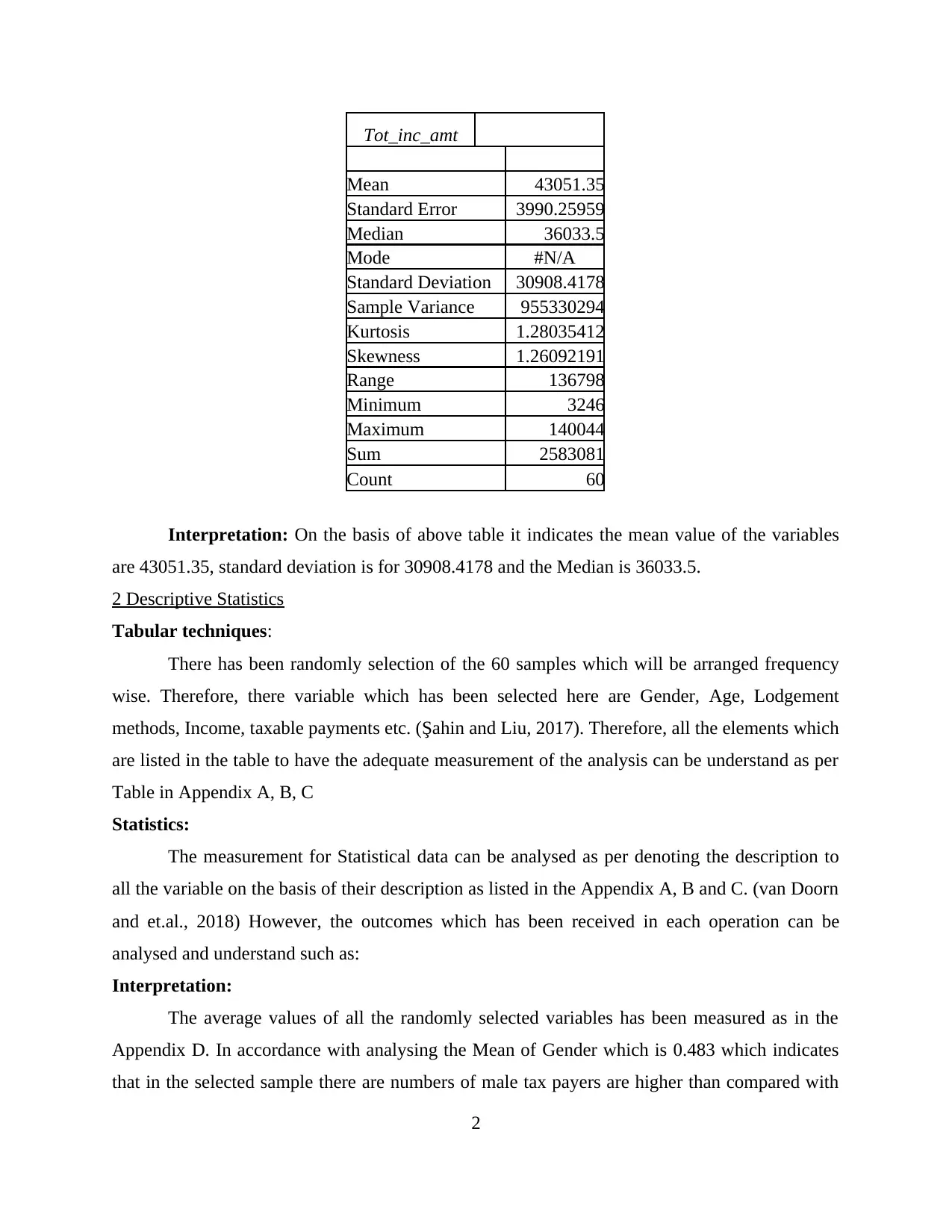
Tot_inc_amt
Mean 43051.35
Standard Error 3990.25959
Median 36033.5
Mode #N/A
Standard Deviation 30908.4178
Sample Variance 955330294
Kurtosis 1.28035412
Skewness 1.26092191
Range 136798
Minimum 3246
Maximum 140044
Sum 2583081
Count 60
Interpretation: On the basis of above table it indicates the mean value of the variables
are 43051.35, standard deviation is for 30908.4178 and the Median is 36033.5.
2 Descriptive Statistics
Tabular techniques:
There has been randomly selection of the 60 samples which will be arranged frequency
wise. Therefore, there variable which has been selected here are Gender, Age, Lodgement
methods, Income, taxable payments etc. (Şahin and Liu, 2017). Therefore, all the elements which
are listed in the table to have the adequate measurement of the analysis can be understand as per
Table in Appendix A, B, C
Statistics:
The measurement for Statistical data can be analysed as per denoting the description to
all the variable on the basis of their description as listed in the Appendix A, B and C. (van Doorn
and et.al., 2018) However, the outcomes which has been received in each operation can be
analysed and understand such as:
Interpretation:
The average values of all the randomly selected variables has been measured as in the
Appendix D. In accordance with analysing the Mean of Gender which is 0.483 which indicates
that in the selected sample there are numbers of male tax payers are higher than compared with
2
Mean 43051.35
Standard Error 3990.25959
Median 36033.5
Mode #N/A
Standard Deviation 30908.4178
Sample Variance 955330294
Kurtosis 1.28035412
Skewness 1.26092191
Range 136798
Minimum 3246
Maximum 140044
Sum 2583081
Count 60
Interpretation: On the basis of above table it indicates the mean value of the variables
are 43051.35, standard deviation is for 30908.4178 and the Median is 36033.5.
2 Descriptive Statistics
Tabular techniques:
There has been randomly selection of the 60 samples which will be arranged frequency
wise. Therefore, there variable which has been selected here are Gender, Age, Lodgement
methods, Income, taxable payments etc. (Şahin and Liu, 2017). Therefore, all the elements which
are listed in the table to have the adequate measurement of the analysis can be understand as per
Table in Appendix A, B, C
Statistics:
The measurement for Statistical data can be analysed as per denoting the description to
all the variable on the basis of their description as listed in the Appendix A, B and C. (van Doorn
and et.al., 2018) However, the outcomes which has been received in each operation can be
analysed and understand such as:
Interpretation:
The average values of all the randomly selected variables has been measured as in the
Appendix D. In accordance with analysing the Mean of Gender which is 0.483 which indicates
that in the selected sample there are numbers of male tax payers are higher than compared with
2

the female. In relation with the mean value of Age range which is 4.83 it indicates that there are
maximum numbers of taxpayer of age between 49-54. Thus, while analysing the occupational
code's mean value it indicates 4.48 which presents that in the selected group there are large
numbers of employees from the community and personal service sector. In accordance with the
mean value of lodgement it determines that there are comparatively equivalent lodgement
methods such as through self efforts or through agents.
In accordance with the mode value of all the variables the Gender as 0(Male), age range
as 2 (60-64), occupational code as 0, Lodgement has 2 etc. However, it can be said that such
variables bring the knowledge that there are large numbers of male tax payers who are making
the taxable payments. Therefore, the median of such variables are gender as 0, age range as 4.5,
occupational code as 4.5, lodgement as 2 and on. However, it can be said that the selected
samples are very helpful as it determines that there are maximum numbers of male tex
practitioners and they belong to the age group between 60-64 which are working in the sector of
community and personal service sector.
PART B
3 Confidence Intervals
To analyse this statistical term which is helpful in measuring and observing the data on
the basis of selected frequency. However, in the below listed analysis there has been selection of
the adequate variable and have the frequency analysed over it (Olivoto and et.al., 2018). Thus,
the analysis is based on analysing the income level of all the individuals as the 95% of the
confidence interval for mean calculations. Therefore, it will be on the basis of all the data inputs
of the survey such as 2338.
Descrip
tives
income
N Mean Std.
Deviation
Std.
Error
95% Confidence Interval
for Mean
Minim
um
3
maximum numbers of taxpayer of age between 49-54. Thus, while analysing the occupational
code's mean value it indicates 4.48 which presents that in the selected group there are large
numbers of employees from the community and personal service sector. In accordance with the
mean value of lodgement it determines that there are comparatively equivalent lodgement
methods such as through self efforts or through agents.
In accordance with the mode value of all the variables the Gender as 0(Male), age range
as 2 (60-64), occupational code as 0, Lodgement has 2 etc. However, it can be said that such
variables bring the knowledge that there are large numbers of male tax payers who are making
the taxable payments. Therefore, the median of such variables are gender as 0, age range as 4.5,
occupational code as 4.5, lodgement as 2 and on. However, it can be said that the selected
samples are very helpful as it determines that there are maximum numbers of male tex
practitioners and they belong to the age group between 60-64 which are working in the sector of
community and personal service sector.
PART B
3 Confidence Intervals
To analyse this statistical term which is helpful in measuring and observing the data on
the basis of selected frequency. However, in the below listed analysis there has been selection of
the adequate variable and have the frequency analysed over it (Olivoto and et.al., 2018). Thus,
the analysis is based on analysing the income level of all the individuals as the 95% of the
confidence interval for mean calculations. Therefore, it will be on the basis of all the data inputs
of the survey such as 2338.
Descrip
tives
income
N Mean Std.
Deviation
Std.
Error
95% Confidence Interval
for Mean
Minim
um
3
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
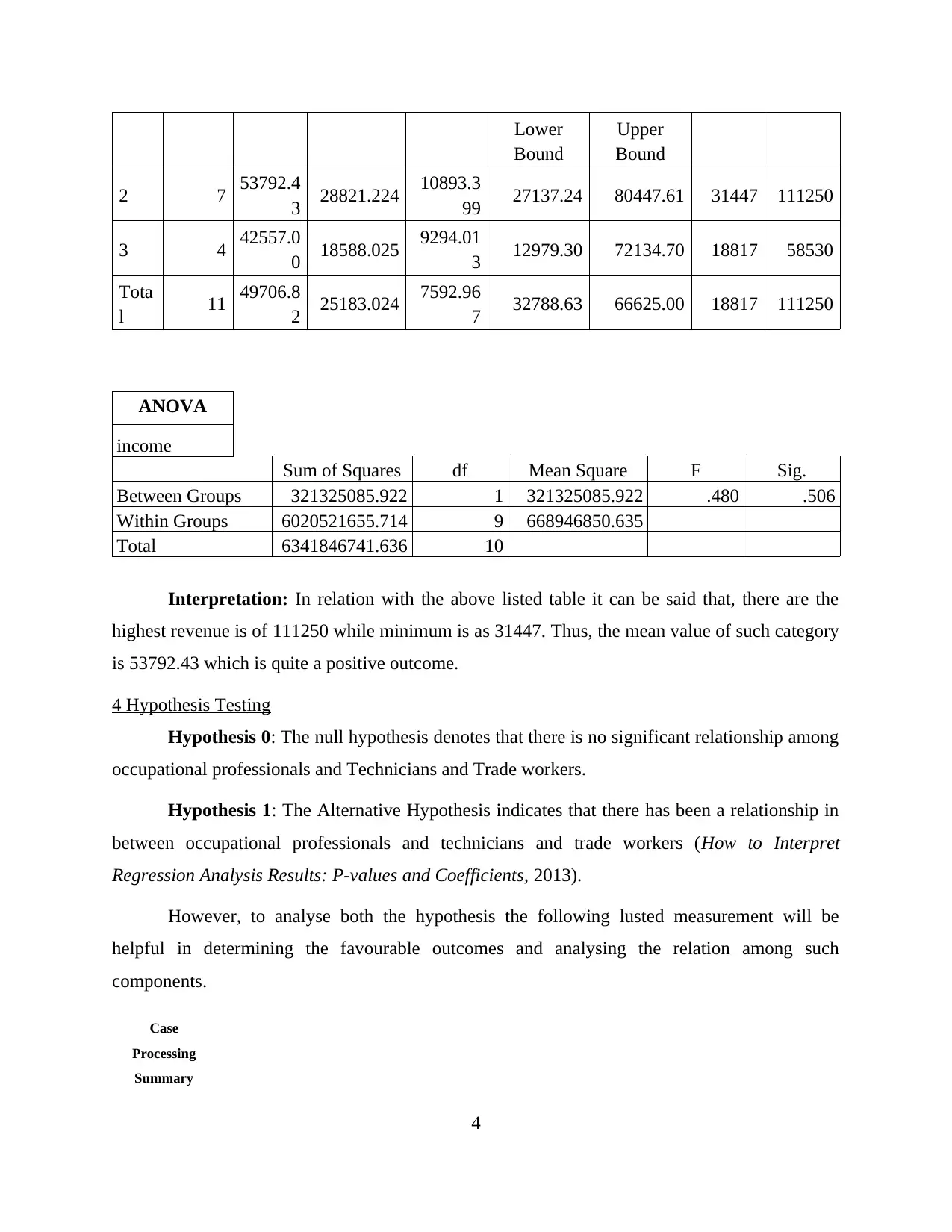
Lower
Bound
Upper
Bound
2 7 53792.4
3 28821.224 10893.3
99 27137.24 80447.61 31447 111250
3 4 42557.0
0 18588.025 9294.01
3 12979.30 72134.70 18817 58530
Tota
l 11 49706.8
2 25183.024 7592.96
7 32788.63 66625.00 18817 111250
ANOVA
income
Sum of Squares df Mean Square F Sig.
Between Groups 321325085.922 1 321325085.922 .480 .506
Within Groups 6020521655.714 9 668946850.635
Total 6341846741.636 10
Interpretation: In relation with the above listed table it can be said that, there are the
highest revenue is of 111250 while minimum is as 31447. Thus, the mean value of such category
is 53792.43 which is quite a positive outcome.
4 Hypothesis Testing
Hypothesis 0: The null hypothesis denotes that there is no significant relationship among
occupational professionals and Technicians and Trade workers.
Hypothesis 1: The Alternative Hypothesis indicates that there has been a relationship in
between occupational professionals and technicians and trade workers (How to Interpret
Regression Analysis Results: P-values and Coefficients, 2013).
However, to analyse both the hypothesis the following lusted measurement will be
helpful in determining the favourable outcomes and analysing the relation among such
components.
Case
Processing
Summary
4
Bound
Upper
Bound
2 7 53792.4
3 28821.224 10893.3
99 27137.24 80447.61 31447 111250
3 4 42557.0
0 18588.025 9294.01
3 12979.30 72134.70 18817 58530
Tota
l 11 49706.8
2 25183.024 7592.96
7 32788.63 66625.00 18817 111250
ANOVA
income
Sum of Squares df Mean Square F Sig.
Between Groups 321325085.922 1 321325085.922 .480 .506
Within Groups 6020521655.714 9 668946850.635
Total 6341846741.636 10
Interpretation: In relation with the above listed table it can be said that, there are the
highest revenue is of 111250 while minimum is as 31447. Thus, the mean value of such category
is 53792.43 which is quite a positive outcome.
4 Hypothesis Testing
Hypothesis 0: The null hypothesis denotes that there is no significant relationship among
occupational professionals and Technicians and Trade workers.
Hypothesis 1: The Alternative Hypothesis indicates that there has been a relationship in
between occupational professionals and technicians and trade workers (How to Interpret
Regression Analysis Results: P-values and Coefficients, 2013).
However, to analyse both the hypothesis the following lusted measurement will be
helpful in determining the favourable outcomes and analysing the relation among such
components.
Case
Processing
Summary
4
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
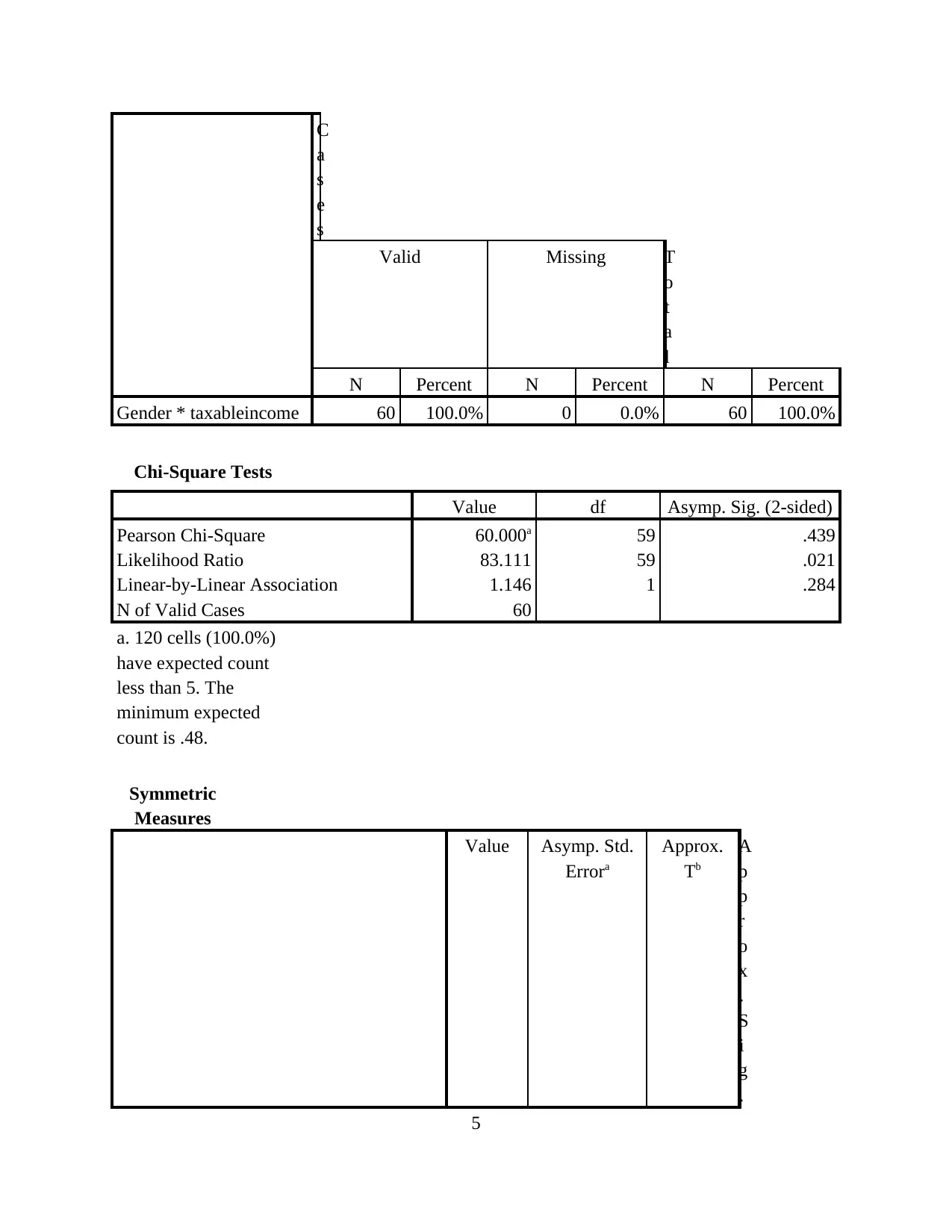
C
a
s
e
s
Valid Missing T
o
t
a
l
N Percent N Percent N Percent
Gender * taxableincome 60 100.0% 0 0.0% 60 100.0%
Chi-Square Tests
Value df Asymp. Sig. (2-sided)
Pearson Chi-Square 60.000a 59 .439
Likelihood Ratio 83.111 59 .021
Linear-by-Linear Association 1.146 1 .284
N of Valid Cases 60
a. 120 cells (100.0%)
have expected count
less than 5. The
minimum expected
count is .48.
Symmetric
Measures
Value Asymp. Std.
Errora
Approx.
Tb
A
p
p
r
o
x
.
S
i
g
.
5
a
s
e
s
Valid Missing T
o
t
a
l
N Percent N Percent N Percent
Gender * taxableincome 60 100.0% 0 0.0% 60 100.0%
Chi-Square Tests
Value df Asymp. Sig. (2-sided)
Pearson Chi-Square 60.000a 59 .439
Likelihood Ratio 83.111 59 .021
Linear-by-Linear Association 1.146 1 .284
N of Valid Cases 60
a. 120 cells (100.0%)
have expected count
less than 5. The
minimum expected
count is .48.
Symmetric
Measures
Value Asymp. Std.
Errora
Approx.
Tb
A
p
p
r
o
x
.
S
i
g
.
5
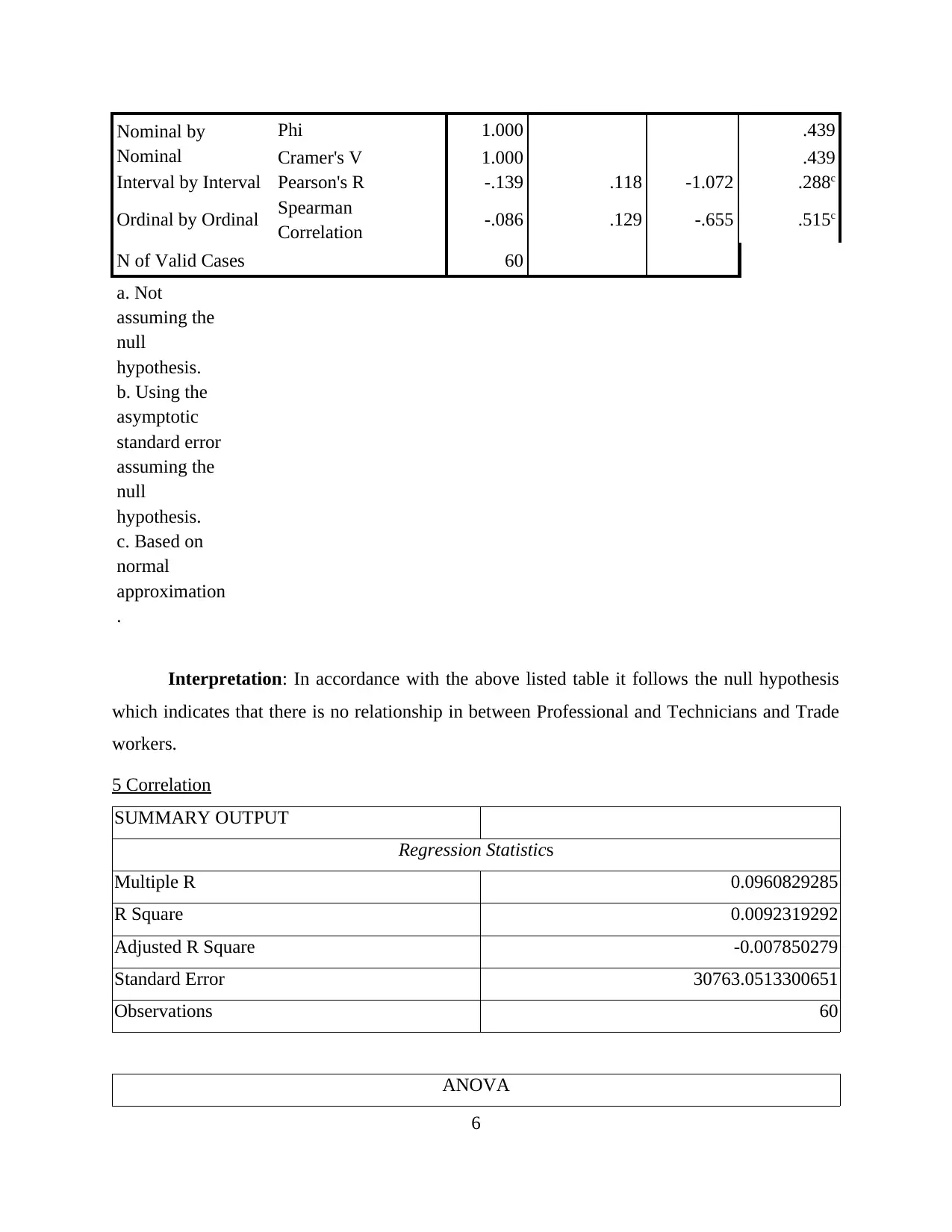
Nominal by
Nominal
Phi 1.000 .439
Cramer's V 1.000 .439
Interval by Interval Pearson's R -.139 .118 -1.072 .288c
Ordinal by Ordinal Spearman
Correlation -.086 .129 -.655 .515c
N of Valid Cases 60
a. Not
assuming the
null
hypothesis.
b. Using the
asymptotic
standard error
assuming the
null
hypothesis.
c. Based on
normal
approximation
.
Interpretation: In accordance with the above listed table it follows the null hypothesis
which indicates that there is no relationship in between Professional and Technicians and Trade
workers.
5 Correlation
SUMMARY OUTPUT
Regression Statistics
Multiple R 0.0960829285
R Square 0.0092319292
Adjusted R Square -0.007850279
Standard Error 30763.0513300651
Observations 60
ANOVA
6
Nominal
Phi 1.000 .439
Cramer's V 1.000 .439
Interval by Interval Pearson's R -.139 .118 -1.072 .288c
Ordinal by Ordinal Spearman
Correlation -.086 .129 -.655 .515c
N of Valid Cases 60
a. Not
assuming the
null
hypothesis.
b. Using the
asymptotic
standard error
assuming the
null
hypothesis.
c. Based on
normal
approximation
.
Interpretation: In accordance with the above listed table it follows the null hypothesis
which indicates that there is no relationship in between Professional and Technicians and Trade
workers.
5 Correlation
SUMMARY OUTPUT
Regression Statistics
Multiple R 0.0960829285
R Square 0.0092319292
Adjusted R Square -0.007850279
Standard Error 30763.0513300651
Observations 60
ANOVA
6
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
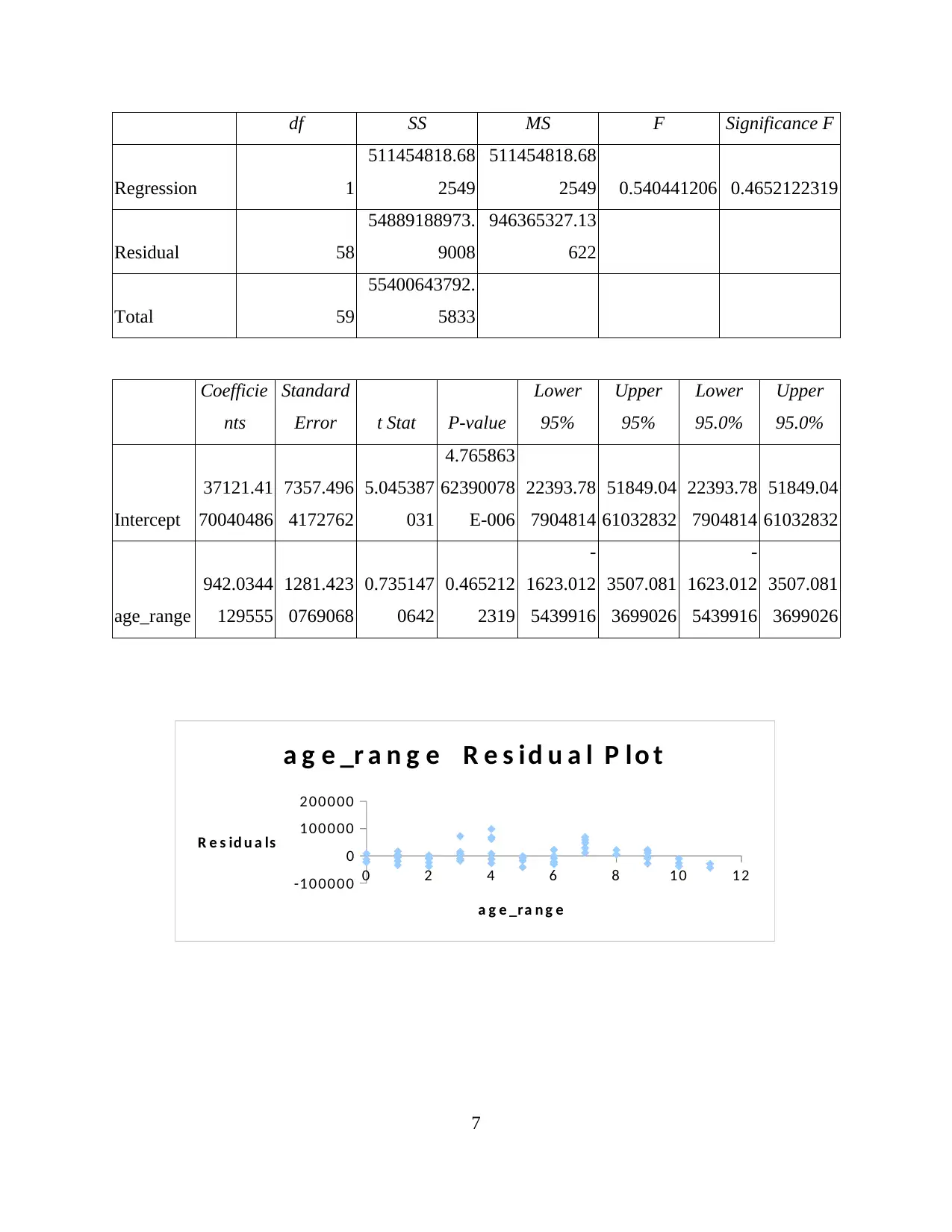
df SS MS F Significance F
Regression 1
511454818.68
2549
511454818.68
2549 0.540441206 0.4652122319
Residual 58
54889188973.
9008
946365327.13
622
Total 59
55400643792.
5833
Coefficie
nts
Standard
Error t Stat P-value
Lower
95%
Upper
95%
Lower
95.0%
Upper
95.0%
Intercept
37121.41
70040486
7357.496
4172762
5.045387
031
4.765863
62390078
E-006
22393.78
7904814
51849.04
61032832
22393.78
7904814
51849.04
61032832
age_range
942.0344
129555
1281.423
0769068
0.735147
0642
0.465212
2319
-
1623.012
5439916
3507.081
3699026
-
1623.012
5439916
3507.081
3699026
0 2 4 6 8 10 12
-100000
0
100000
200000
a g e _r a n g e R e s id u a l P lo t
a g e _ra n g e
R e s id u a ls
7
Regression 1
511454818.68
2549
511454818.68
2549 0.540441206 0.4652122319
Residual 58
54889188973.
9008
946365327.13
622
Total 59
55400643792.
5833
Coefficie
nts
Standard
Error t Stat P-value
Lower
95%
Upper
95%
Lower
95.0%
Upper
95.0%
Intercept
37121.41
70040486
7357.496
4172762
5.045387
031
4.765863
62390078
E-006
22393.78
7904814
51849.04
61032832
22393.78
7904814
51849.04
61032832
age_range
942.0344
129555
1281.423
0769068
0.735147
0642
0.465212
2319
-
1623.012
5439916
3507.081
3699026
-
1623.012
5439916
3507.081
3699026
0 2 4 6 8 10 12
-100000
0
100000
200000
a g e _r a n g e R e s id u a l P lo t
a g e _ra n g e
R e s id u a ls
7
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

30/12/1899
0
50000
100000
150000
N o r m a l P r o b a b ilit y P lo t
C olum n P
S a m p le P e rc e n ti le
T a x a b le _I n c o m e
Interpretation: In accordance with the correlation and regression analysis it represents
the significance value as 0.46. Therefore, there can be use of such null hypothesis as it reflects
the favourable value which is more than the significant level of 0.05.
CONCLUSION
In accordance with the above report it can be said that there has been use of various
statistical techniques as well as analysis that helps in making the adequate analysis of the data
set. However, it has been analysed there are majority of the male tax payers in compared with
females as well as they make the payments of taxes with the help of agents. Moreover, it can be
said that the government need to implement techniques that will be helpful and convenient to the
people in terms of making the taxable payments on their own.
8
0
50000
100000
150000
N o r m a l P r o b a b ilit y P lo t
C olum n P
S a m p le P e rc e n ti le
T a x a b le _I n c o m e
Interpretation: In accordance with the correlation and regression analysis it represents
the significance value as 0.46. Therefore, there can be use of such null hypothesis as it reflects
the favourable value which is more than the significant level of 0.05.
CONCLUSION
In accordance with the above report it can be said that there has been use of various
statistical techniques as well as analysis that helps in making the adequate analysis of the data
set. However, it has been analysed there are majority of the male tax payers in compared with
females as well as they make the payments of taxes with the help of agents. Moreover, it can be
said that the government need to implement techniques that will be helpful and convenient to the
people in terms of making the taxable payments on their own.
8

REFERENCES
Books and Journals
Olivoto, T. and et.al., 2018. Confidence Interval Width for Pearson’s Correlation Coefficient: A
Gaussian-Independent Estimator Based on Sample Size and Strength of Association.
Agronomy Journal.
Şahin, R. and Liu, P., 2017. Correlation coefficient of single-valued neutrosophic hesitant fuzzy
sets and its applications in decision making. Neural Computing and Applications. 28(6).
pp.1387-1395.
van Doorn, J. and et.al., 2018. Bayesian inference for Kendall’s rank correlation coefficient. The
American Statistician, pp.1-6.
Online
How to Interpret Regression Analysis Results: P-values and Coefficients. 2013. [Online].
Available through :<http://blog.minitab.com/blog/adventures-in-statistics-2/how-to-
interpret-regression-analysis-results-p-values-and-coefficients>.
9
Books and Journals
Olivoto, T. and et.al., 2018. Confidence Interval Width for Pearson’s Correlation Coefficient: A
Gaussian-Independent Estimator Based on Sample Size and Strength of Association.
Agronomy Journal.
Şahin, R. and Liu, P., 2017. Correlation coefficient of single-valued neutrosophic hesitant fuzzy
sets and its applications in decision making. Neural Computing and Applications. 28(6).
pp.1387-1395.
van Doorn, J. and et.al., 2018. Bayesian inference for Kendall’s rank correlation coefficient. The
American Statistician, pp.1-6.
Online
How to Interpret Regression Analysis Results: P-values and Coefficients. 2013. [Online].
Available through :<http://blog.minitab.com/blog/adventures-in-statistics-2/how-to-
interpret-regression-analysis-results-p-values-and-coefficients>.
9
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 15
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.