University Data Science: Assignment 2 on Data Warehousing & Analysis
VerifiedAdded on 2020/03/04
|22
|3176
|50
Report
AI Summary
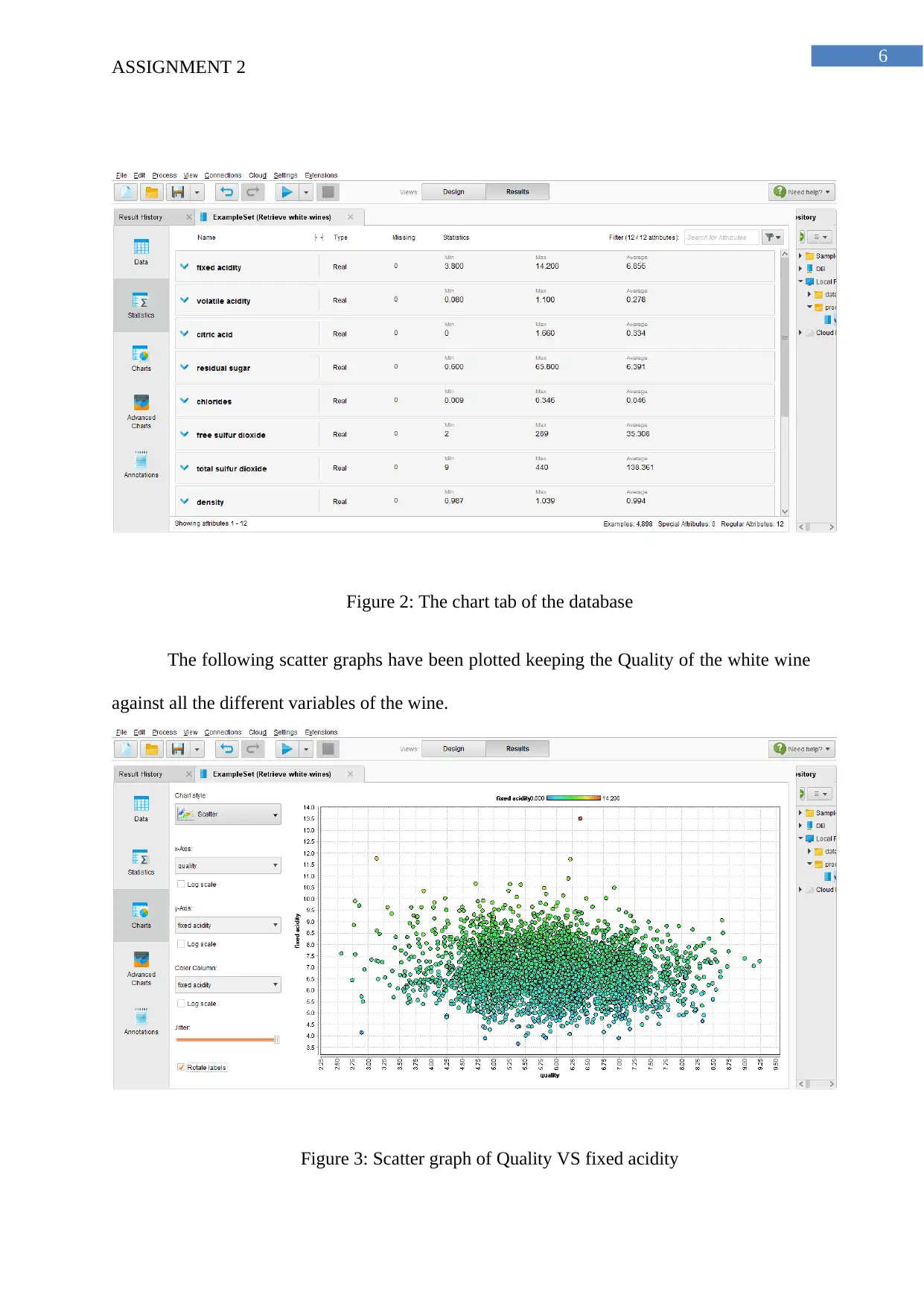
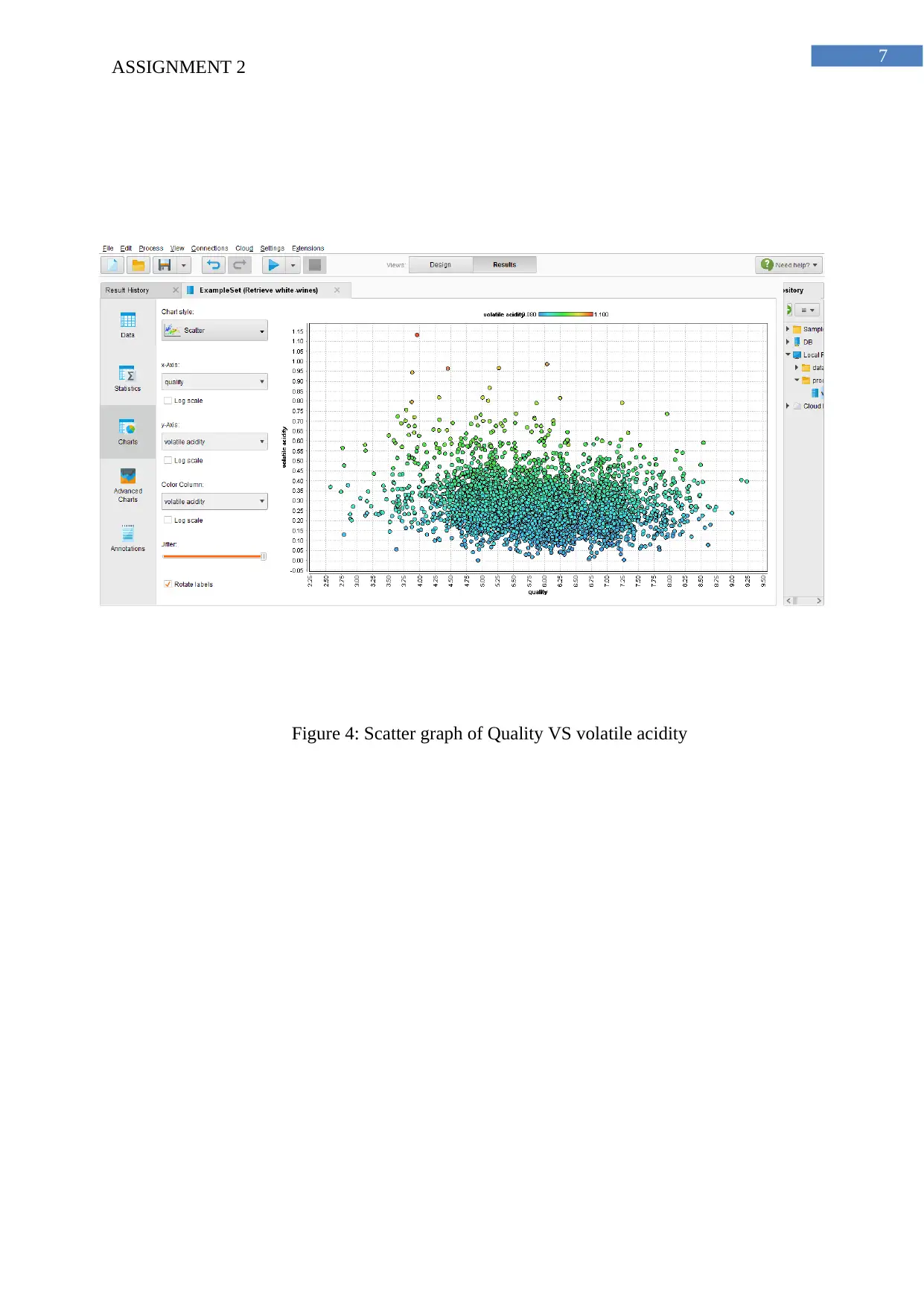
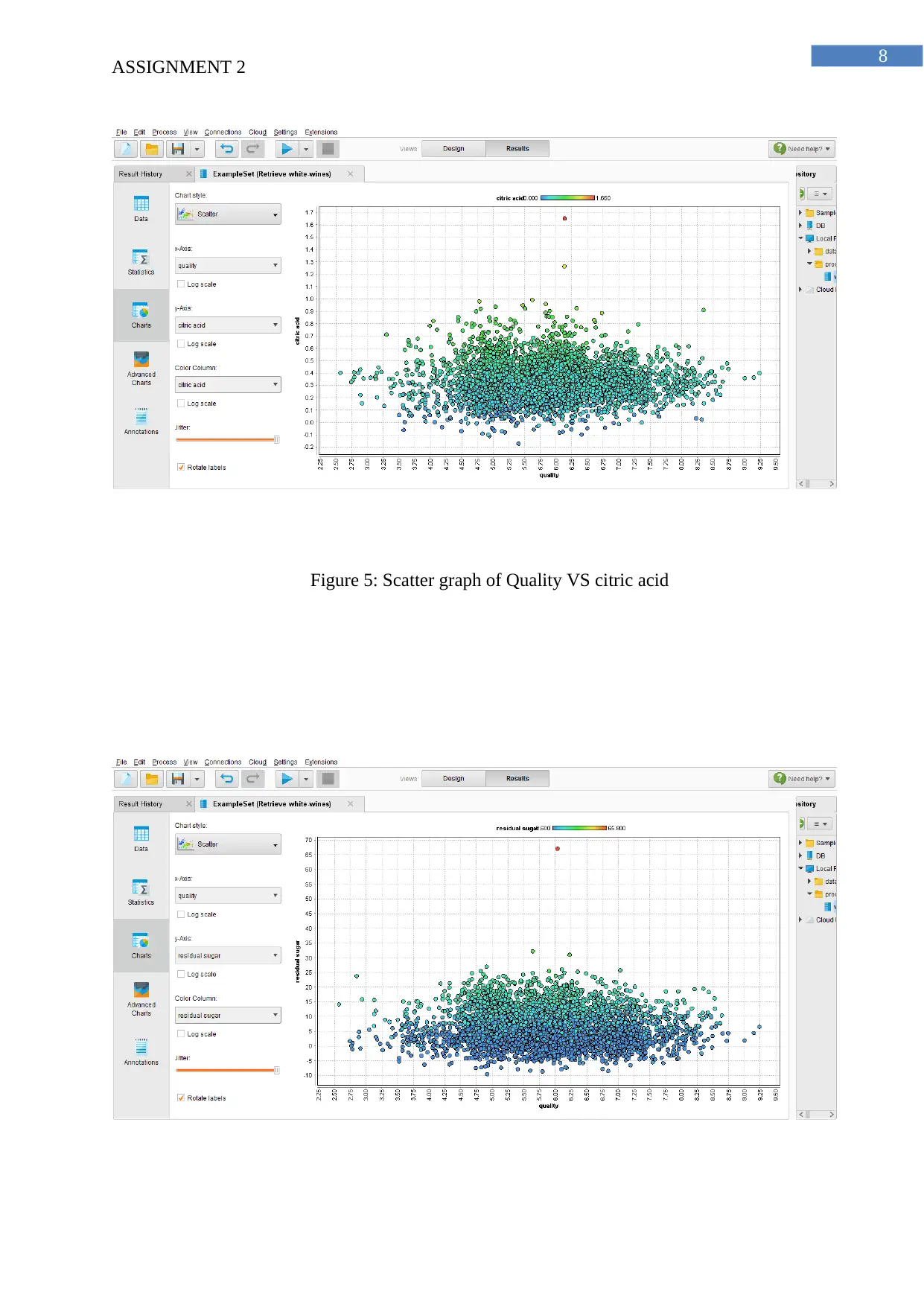
This report analyzes data warehousing, data lakes, and data marts, comparing their functionalities and applications within organizations. It explores data warehousing's role in structured data analysis, data lakes for handling diverse data types, and data marts for departmental data analysis. The report then presents a practical application of data analysis using RapidMiner. The analysis focuses on determining the key variables influencing white wine quality through scatter graphs and a correlation table. Furthermore, it details the process of creating a linear regression model to predict wine quality, providing the resulting equation and coefficient values for each variable. The report highlights the top five variables affecting wine quality, according to both the initial scatter graph analysis and the correlation table, concluding with the linear regression equation derived from the RapidMiner analysis.





1 out of 22
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.